定义
正则表达式(Regular Expression)
用某种模式去匹配一类字符串的公式,主要用来描述字符串匹配的工具。
匹配
文本或字符存在不止一个部分满足给定的正则表达式,这是每一个这样的部分都被称为一个匹配。 匹配分为以下三种类型:
- 形容词性的匹配
即一个字符串匹配一个正则表达式 - 名词性的匹配
即在文本或字符串里匹配正则表达式 - 名词性的匹配
即字符串中满足给定的正则表达式的一部分
元字符
元字符(Metacharacter)是一类非常特殊的字符,它能够匹配一个位置或字符集合中的一个字符,元字符可以分为两种类型
- 匹配位置的元字符
- 匹配字符的元字符
元字符只能匹配一个字符位置,也就是一个匹配的单位是一个字符,而不是一个字符串
匹配位置的元字符
测试
^a
匹配第一个字母为a的一行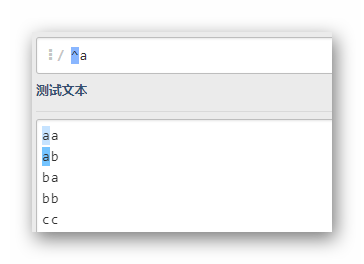
a$
匹配最后一个字母为a的一行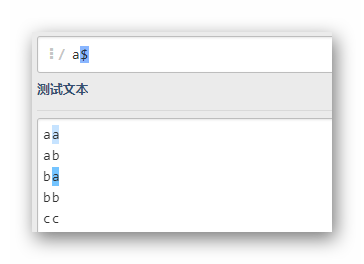
^a$
匹配只有一个字母a的一行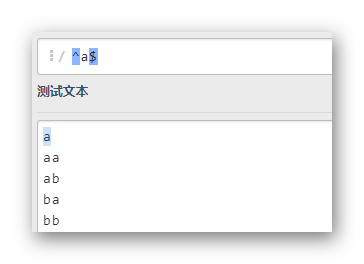
bStr
匹配以Str为开头的单词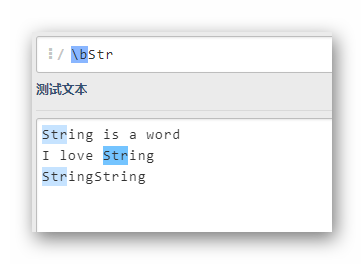
ingb
匹配以ing为结尾的单词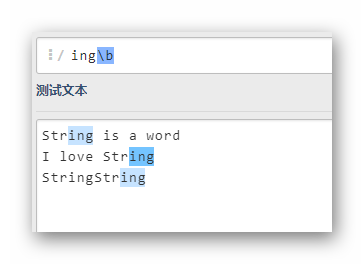
bStringb
仅匹配String这个单词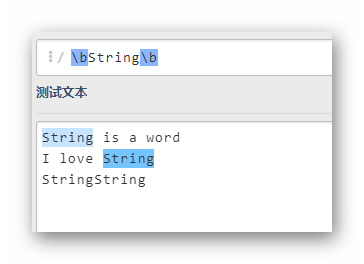
b字符如何识别哪个是单词呢?
以标点符号或空格分隔的字符串将被识别为单词,而且 b只能用于英文,不能用于中文
匹配字符的元字符
元字符都是按照单个字符进行匹配
测试
.
全部字符匹配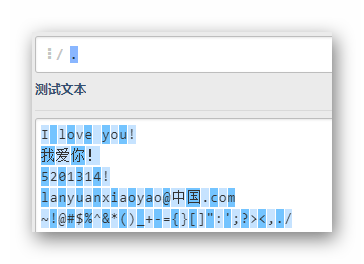
w
匹配了全部的单词字符,除了下划线之外的标点符号和汉字都被排除在外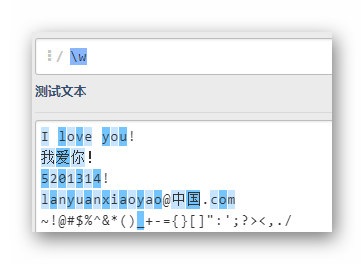
W
匹配结果和w刚好相反,注意那个下划线是属于单词字符的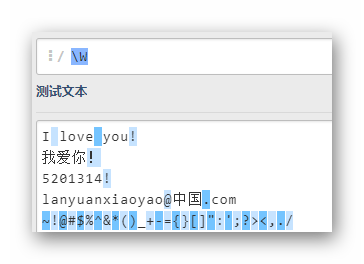
s
有2个空格被匹配,注意!这里总共有6个符号被匹配了,除了两个空格还有1~4行末的换行符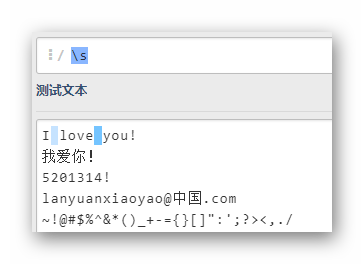
S
除了2个空格和4个换行符,其余字符全部匹配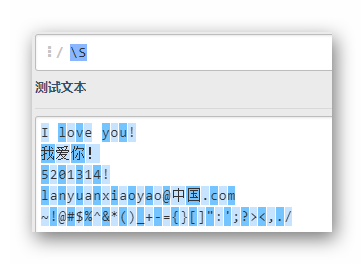
d
匹配所有的数字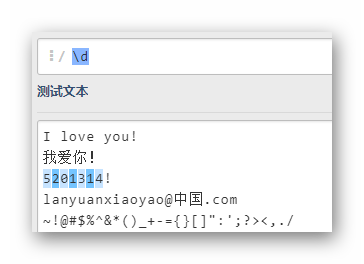
D
匹配所有数字之外的字符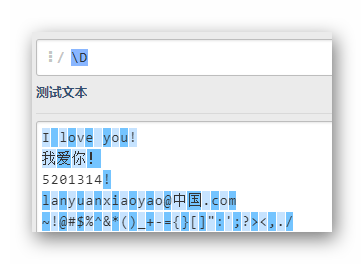
元字符组合
仅仅是元字符就可以自由组合来实现不同的匹配效果
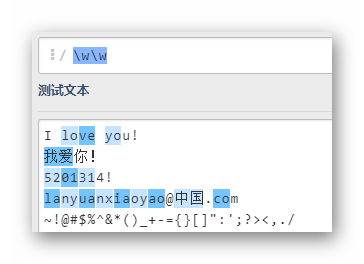
ww
匹配连续的两个单词字符
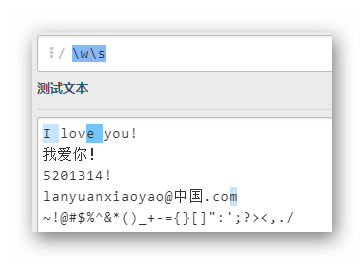
ws
注意第三行最后匹配的m是和行末的换行符一起匹配成功的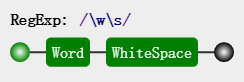
文字匹配
字符类
字符类是一个字符集合,如果该字符集合中的任何一个字符被匹配,则它会找到该匹配项。
[]
字符类使用中括号作为标志,字符集合写在中括号里面,意为匹配中括号中的任意一个字符-- 当
-符号不是第一个字符的时候表示定义字符的范围*,例如[1-3]表示[123],[a-z]表示匹配任意小写字母,如果-放在第一位,那就仅表示自己,这个范围的顺序和两个字符间的内容是按照ASCII表的顺序决定的,例如[9-1]是违反ASCII表顺序的一个表达式,这会报错 ^
如果放在字符类第一个,表示该字符类的否定,[^123]表示匹配1、2、3之外的所有数字- 元字符在字符类中不做任何特殊处理,仅仅表示他们自身
测试
[aeiou]
匹配元音字母[a-z]
匹配从小写字母a到z之间的所有字母[^aeiou]
匹配元音字母之外的所有字符(包括任意符号)[^a-z]
匹配小写字母a到z之间的所有字母之外的所有字符[0-9]
匹配从0到9之间的任意一个数字[ao-u]
匹配a和o到u之间的所有字母,可以看到只要在连个字符之间使用连接符-就会判断为一个区间[!-?]
匹配从!到?之间的任意一个符号,可以看到因为是按照ASCII表顺序来判断-连接的字符集合,所以这样写也是没有问题的[a^-]
匹配字符a、^和-三个字符,只要^符号不在第一位,-符号不在两个字符中间,那么它们就只表示自身a[no]
匹配字符串an或ao,这是字符类和元字符的组合
字符转义
之前介绍的元字符非常好用,但是这又引出了一个问题,如果我们想在正常的表达式里面使用元字符本身这个符号怎么办呢?难道每次都要写在字符类里面吗?
当然不,这里就引出了我们的字符转义
正则表达式定义了一些特殊的元字符,如^、$、.等。由于这些字符在正则表达式中被解释成其他指定的含义,如果需要匹配这些字符,则需要使用字符转义来解决这个问题。转义字符使用符号(反斜杠),它可以取消这些字符(如^、$、.等)在表达式中具有的特殊意义。
.
匹配字符.*
匹配字符*
匹配字符www.lanyuanxiaoyao.com
匹配字符串www.lanyuanxiaoyao.com,网址中的dot符号也是需要转义的
常用转义字符
限定符
这是一个重要的知识点限定符用于指定允许特定字符或字符集自身重复出现的次数。
测试
a{3}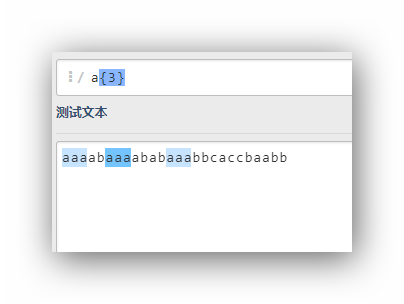
a{2,}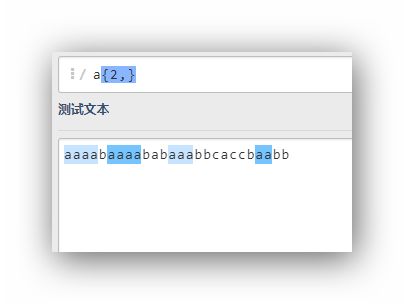
a{2,3}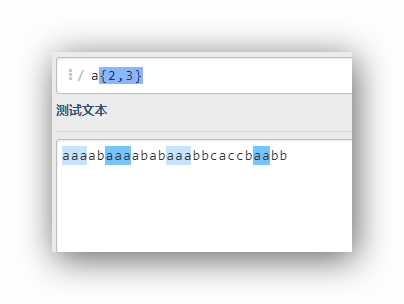
ab+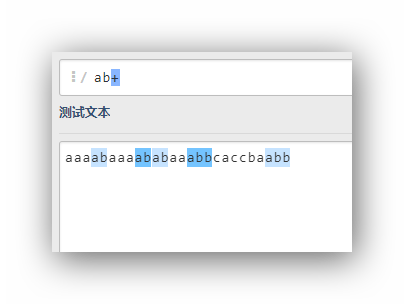
ab?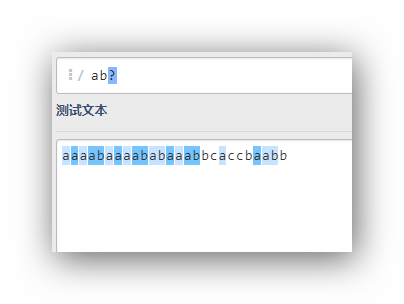
ab*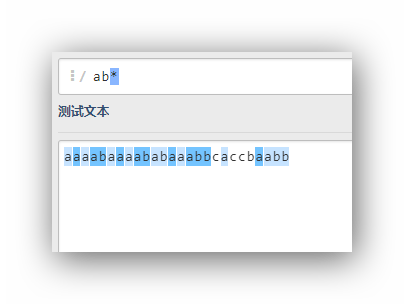
ab+?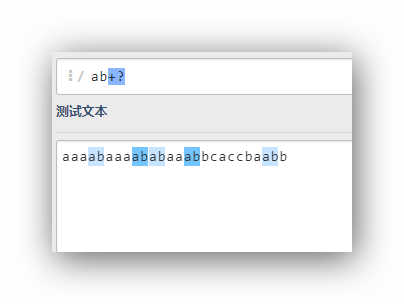
ab??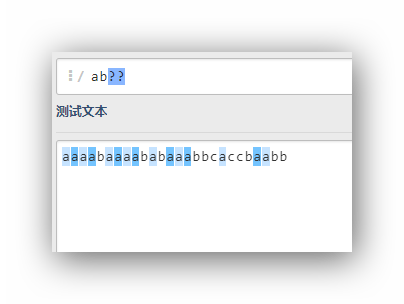
ab*?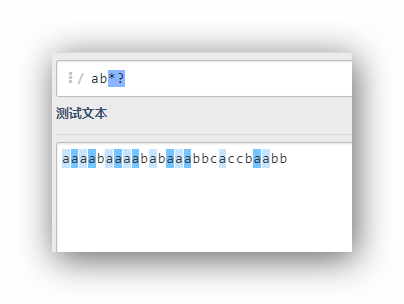
贪婪模式与懒惰模式
如果在限定符*、+、?、{n}、{n,}和{n,m}之后再添加一个字符 ? ,则表示 尽可能少地重复字符?之前的限定符号的重复次数,这种匹配方式称为懒惰匹配,与之相对的,如果没有字符 ? ,仅仅使用单个限定符*、+、?、{n}、{n,}和{n,m}的匹配,就称为贪婪匹配。 看起来好像很复杂,但是理解历来并不难,即懒惰匹配模式只匹配最短符合表达式的字符串,贪婪匹配模式只匹配最长符合表达式的字符串。这里的贪婪模式和懒惰模式在不同的教程或者说明里面都有不同的叫法,所以可以理解意思就行了,大同小异
测试
- 贪婪模式
a.*b
可以看到这里只有一个匹配,就是整个字符串,因为这是最长的匹配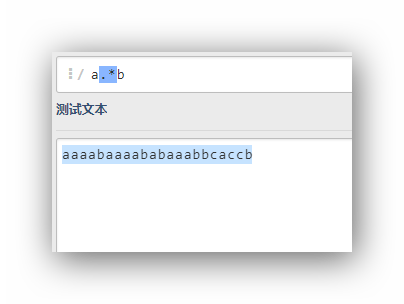
- 懒惰模式
a.?b
这里一旦发现一个匹配立刻就完成当前的匹配,然后从下一个字符开始新的匹配,所以这里会有4个匹配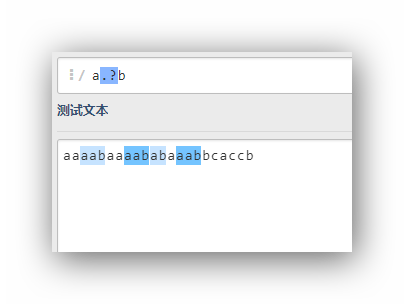
字符的运算
替换
替换使用字符|来表示,表示如果某一个字符串匹配了表达式中字符|左边或者右边的规则,那么这个字符串就匹配了这个表达式|表示“或”的意思,这个符号和代码中的“逻辑或”相同,比较好理解匹配是根据左边优先的原则,即从左往右,当左边的表达式不满足的时候,才会去尝试右边的表达式
测试
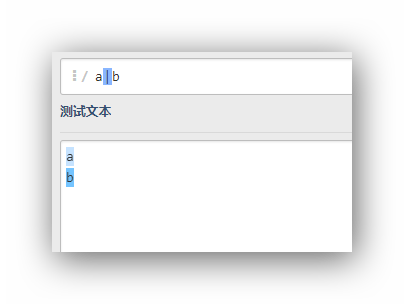
a|b
可以看到不管是字符a还是b都可以匹配这个表达式,它等同于[ab]
分组
分组又被称为子表达式,即把一个正则表达式的全部或部分分成一个或多个组,分组使用()来表示,括号中的表达式就是一个组,一个组就是一个整体
要注意和字符类[]区分开来,[123]是表示匹配字符1或2或3,而(123)就是匹配123这个字符串
反向引用
组号
当一个正则表达式被分组之后,默认从左到右每一个分组都会自动被赋予一个组号,以左括号(为分界从1开始自增,第一个组的组号是1,第二个组的组号是2,以此类推,在后面的表达式,使用组号的方式来引用前面的组,例如b(w)1b这个表达式中,后面的1就是对前面(w)组的引用 自定义组号
分组不止会自动使用数字作为组号,还可以手动命名,形式为(?<name>),(?<word>w)和(?'word'w)都是把w+匹配到的字母保存到名为word的分组,自定义命名的分组使用k<name>的方式使用 ,如b(?<word>w)k<word>b是匹配连续的相同的两个字母的单词 反向引用
提供了查找重复字符组的简便方法,可以认为是再次匹配同一个字符组的快捷指令反向引用引用的是前面的表达式匹配到的字符串,而不是前面的表达式
例如,b(w)1b 这个表达式中的1表示的是前面w匹配到的字符,前面匹配到字母a那么1处也必须替换为字母a,而不是任意一个字母 所以这个表达式匹配的是两个完全相同的字母 而如果是b(w)wb 则是表示两个允许不相同的字母
测试
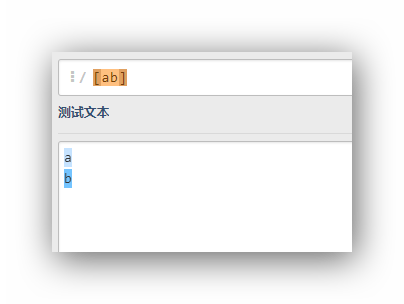
(ab)ab就是一个整体看待,和单独的字符串ab没有区别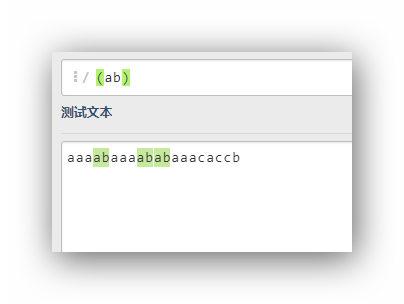
(?<word>ab)k<word>
把ab这个组命名为word,然后在后面调用前面命名的这个组匹配的字符,即这个表达式相当于(ab)ab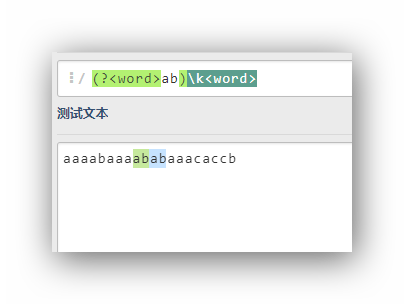
(?:a)(b)1
前面的组被取消命名,所以自动命名从(b)开始,所以后面的1匹配的是(b)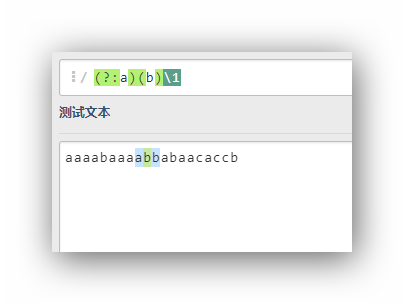
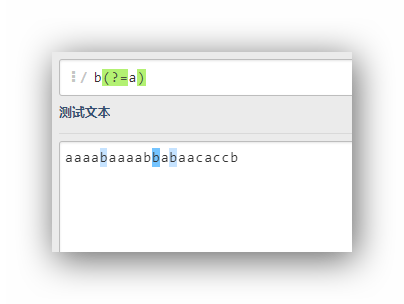
b(?=a)
这个表达式的意思是,匹配字符b,这个字符b的后面紧跟着一个a
b(?!a)
这个表达式的意思是,匹配字符b,这个字符b的后面不是a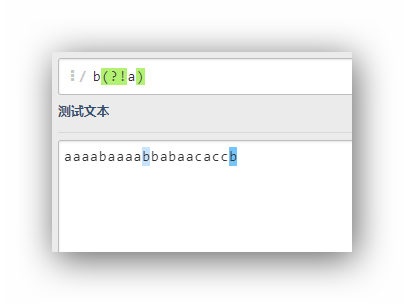
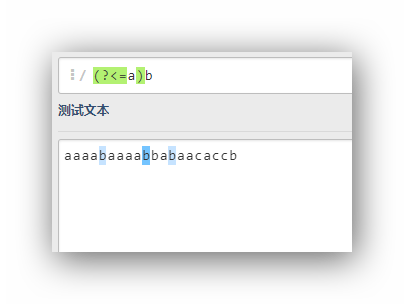
(?<=a)b
这个表达式的意思是,匹配字符b,这个字符b的前面是a
(?<!a)b
这个表达式的意思是,匹配字符b,这个字符b的前面不是a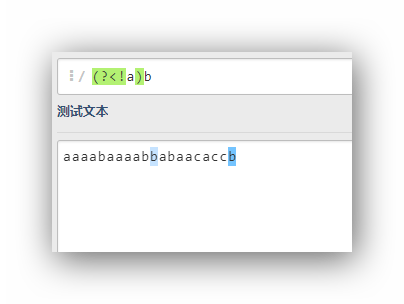
(?>a)b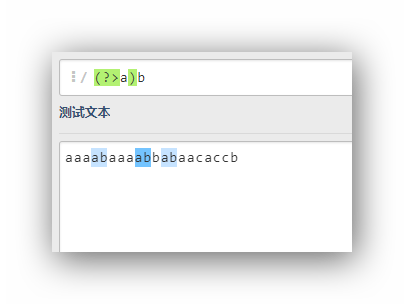
参考
- 王蕾. 神奇的匹配 正则表达式求精之旅[M]. 北京:电子工业出版社, 2014.
- 文中使用的正则表达式测试工具:正则表达式测试工具在线调试与分享-Zjmainstay
- 文中使用的正则表达式可视化生成工具:Regulex JavaScript Regular Expression Visualizer.






Nacos 服务中心初探)


)




)


安装Oracle 11g(32位)全过程以及几乎所有问题的解决办法)

