基础
SparkContext是什么?有什么作用?
https://blog.csdn.net/Shockang/article/details/118344357
- SparkContext 是什么?
SparkContext 是通往 Spark 集群的唯一入口,可以用来在 Spark 集群中创建 RDDs 、累加和广播变量( BroadcastVariables )。
SparkContext 也是整个 Spark 应用程序( Application )中至关重要的一个对象,可以说是整个 Application 运行调度的核心(不是指资源调度)。
- SparkContext 的作用是什么?
SparkContext 的核心作用是初始化 Spark 应用程序运行所需要的核心组件,包括高层调度器( DAGScheduler )、底层调度器( TaskScheduler )和调度器的通信终端( SchedulerBackend ),同时还会负责 Spark 程序向 Master 注册程序等。
只可以有一个 SparkContext 实例运行在一个 JWM 内存中,所以在创建新的 SparkContext 实例前,必须调用 stop 方法停止当前 JVM 唯一运行的 SparkContext 实例。
SparkContext的重要性体现在哪些方面?
Spark 程序在运行时分为 Driver 和 Executor 两部分, Spark 程序编写是基于 SparkContext 的,具体包含。
1)Spark 编程的核心基础 RDD 是由 SparkContext 最初创建的(第一个 RDD 一定是由 SparkContext 创建的)
2)Spark 程序的调度优化也是基于 SparkContext ,首先进行调度优化。
3)Spark 程序的注册是通过 SparkContext 实例化时生产的对象来完成的(其实是 SchedulerBackend来注册程序)。
4)Spark 程序在运行时要通过 ClusterManager 获取具体的计算资源,计算资源获取也是通过 SparkContext 产生的对象来申请的(其实是 SchedulerBackend 来获取计算资源的)。
5)SparkContext 崩溃或者结束的时候,整个 Spark 程序也结束。
Spark Master\Worker、Driver\Executor、Job\Stage\Task等概念与关系
https://blog.csdn.net/bocai8058/article/details/119300432

Spark 内存管理
https://mp.weixin.qq.com/s/H0bN00fyxevB6vV6RAdWqQ
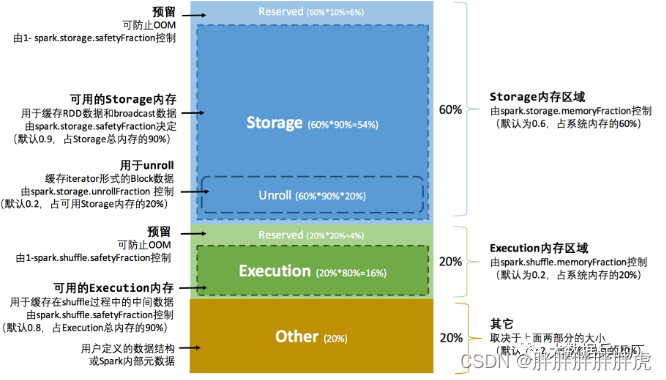
Spark堆内内存主要分为Storage(存储内存)、Execution(执行内存)和Other(其他) 几部分。
Storage用于缓存RDD数据和broadcast广播变量的内存使用
Execution仅提供shuffle过程的内存使用
Other提供Spark内部对象、用户自定义对象的内存空间
Shuffle
参数 spark.sql.shuffle.partitions 默认并行度200
分区与并行度
https://mp.weixin.qq.com/s/luji-mMQoXiHZanQiKxgww


 -(上))













场:郑州轻工业大学C-数位dp)


)