文章目录
- Oracle 的分组排序
- MySQL 的分组排序
- 分析需求
- 创建模拟数据
- SQL 实现
- 结果演示
Oracle 的分组排序
Oracle 的分组排序函数的语法格式如下:
ROW_NUMBER() OVER([PARTITION BY column_1, column_2,…][ORDER BY column_3,column_4,…]
)
说明:表示根据 column_1, column_2,... 分组,在分组内部根据再根据 column_3,column_4,... 排序。
例如有下面这张员工表:
DROP TABLE IF EXISTS employee;create table employee(empid int,deptid int,salary decimal(10,2)
);insert into employee values(1,10,5500.00);
insert into employee values(2,10,4500.00);
insert into employee values(3,20,1900.00);
insert into employee values(4,20,4800.00);
insert into employee values(5,40,6500.00);
insert into employee values(6,40,14500.00);
insert into employee values(7,40,44500.00);
insert into employee values(8,50,6500.00);
insert into employee values(9,50,7500.00);
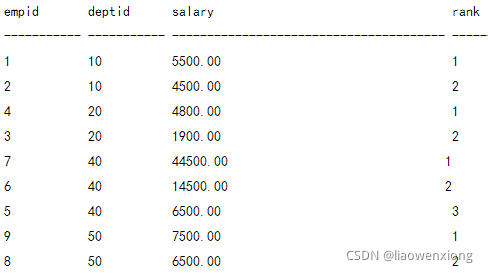
执行下面的分组排序语句:
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank
FROMemployee;
得到的查询结果如下:
MySQL 的分组排序
由于 MySQL 没有提供类似 Oracle 中的类似 OVER() 这样丰富的分析函数,所以在 MySQL 里需要实现这样的功能,我们只能用一些灵活的办法。
分析需求
根据部门来分组,显示各员工在部门里按薪水排名名次。
显示结果预期如下:
+——-+——–+———-+——+
| empid | deptid | salary | rank |
+——-+——–+———-+——+
| 1 | 10 | 5500.00 | 1 |
| 2 | 10 | 4500.00 | 2 |
| 4 | 20 | 4800.00 | 1 |
| 3 | 20 | 1900.00 | 2 |
| 7 | 40 | 44500.00 | 1 |
| 6 | 40 | 14500.00 | 2 |
| 5 | 40 | 6500.00 | 3 |
| 9 | 50 | 7500.00 | 1 |
| 8 | 50 | 6500.00 | 2 |
+——-+——–+———-+——+
创建模拟数据
drop table if exists employee;
create table employee (empid int ,deptid int ,salary decimal(10,2) );insert into employee values
(1,10,5500.00),
(2,10,4500.00),
(3,20,1900.00),
(4,20,4800.00),
(5,40,6500.00),
(6,40,14500.00),
(7,40,44500.00),
(8,50,6500.00),
(9,50,7500.00);
SQL 实现
SELECTempid,deptid,salary,rank, rownum
FROM(SELECTemployee_tmp.empid,employee_tmp.deptid,employee_tmp.salary,@rownum := @rownum + 1 as rownum,IF( @pdept = employee_tmp.deptid, @rank := @rank + 1, @rank := 1 ) AS rank,@pdept := employee_tmp.deptid FROM( SELECT empid, deptid, salary FROM employee ORDER BY deptid ASC, -- 按部门升序salary DESC -- 按工资降序) employee_tmp,( SELECT @rownum := 0, -- 声明定义用户变量rownum@pdept := NULL, -- 声明定义用户变量pdept@rank := 0 -- 声明定义用户变量rank) a ) result;
执行结果如下:

上述语句可以改成:
SET @ROW = 0; -- 声明定义用户变量row
SET @pdept = ''; -- 声明定义用户变量pdept
SET @rownum = 0; -- 声明定义用户变量rownumSELECTa.empid,a.deptid,a.salary,a.rank,a.rownum
FROM(SELECTempid,deptid,salary,@rownum := @rownum + 1 AS rownum,CASEWHEN @pdept = deptid THEN@ROW := @ROW + 1 ELSE @ROW := 1 END rank,@pdept := deptid
FROMemployee
ORDER BYdeptid,salary DESC ) a
结果演示
MySQL > select empid,deptid,salary,rank from (-> select employee_tmp.empid,employee_tmp.deptid,employee_tmp.salary,@rownum:=@rownum+1 ,-> if(@pdept=employee_tmp.deptid,@rank:=@rank+1,@rank:=1) as rank,-> @pdept:=employee_tmp.deptid-> from (-> select empid,deptid,salary from employee order by deptid asc ,salary desc-> ) employee_tmp ,(select @rownum :=0 , @pdept := null ,@rank:=0) a ) result-> ;
+——-+——–+———-+——+
| empid | deptid | salary | rank |
+——-+——–+———-+——+
| 1 | 10 | 5500.00 | 1 |
| 2 | 10 | 4500.00 | 2 |
| 4 | 20 | 4800.00 | 1 |
| 3 | 20 | 1900.00 | 2 |
| 7 | 40 | 44500.00 | 1 |
| 6 | 40 | 14500.00 | 2 |
| 5 | 40 | 6500.00 | 3 |
| 9 | 50 | 7500.00 | 1 |
| 8 | 50 | 6500.00 | 2 |
+——-+——–+———-+——+
9 rows in set (0.00 sec)

启动和停止 MySQL 数据库服务)


使用命令来访问本地/远程的 Oracle 数据库呢?)
 - Ubuntu问答)












)
