MySQL中的两种排序方式
- .通过有序索引顺序扫描直接返回有序数据
因为索引的结构是B+树,索引中的数据是按照一定顺序进行排列的,所以在排序查询中如果能利用索引,就能避免额外的排序操作。EXPLAIN分析查询时,Extra显示为Using index。MySQL会结合SQL中的where、order by中的字段去选择索引。 - .Filesort排序即对返回的数据进行排序
所有不是通过索引直接返回排序结果的操作都是Filesort排序,也就是说进行了额外的排序操作。EXPLAIN分析查询时,Extra显示为Using filesort。
无法使用索引排序的情况
首先要注意:
MySQL一次查询只能使用一个索引,如果要对多个字段使用索引,建立复合索引。
注:下列key指代索引,key_part1、key_part2…指代索引中的顺序字段
- 排序字段在不同的索引中,无法使用索引排序:
SELECT * FROM t1 ORDER BY key1_part1, key2_part1;
- 对关键字的非连续元素使用ORDER BY,order by 使用索引除了前导列为常量时可以不满足最左前缀原则,其他时候都需要满足最左前缀原则
//跳过了key_part1,不满足最左前缀不使用索引
SELECT * FROM t1 ORDER BY key_part2;//前导列为常量,此时可以不满足最左前缀,使用索引
SELECT * FROM t1 WHERE key_part1=常量 ORDER BY key_part2;
- 混合ASC和DESC:
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
- 用于查询行的索引与ORDER BY中所使用的索引不相同:
SELECT * FROM t1 WHERE key2=constant ORDER BY key1;
- 有不同的ORDER BY和GROUP BY表达式。
SELECT * FROM t1 WHERE key_part1=constant ORDER BY key_part2 group by key_part3;
通过B+Tree结构判断索引是否能用于排序
索引是B+Tree的结构,能否使用某个索引来避免排序可以通过数据在B+Tree中的是否有序判断,下文有具体例子。
InnoDB的聚簇索引结构如下:
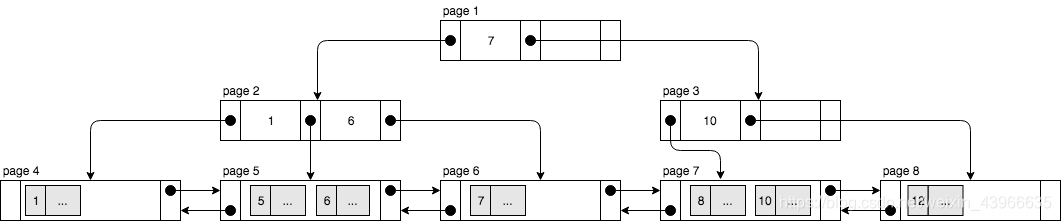
由此可知道,聚簇索引可以用于主键的排序,即order by 主键。
InnoDB的二级索引结构如下:
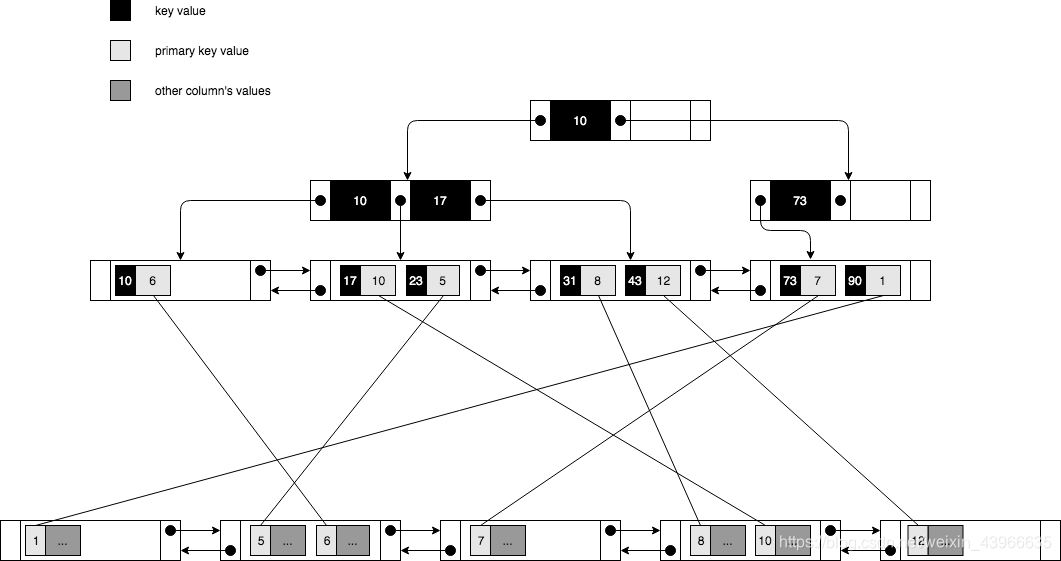
(1)二级索引的叶节点并不包含行记录的全部数据,仅包含索引中的所有键和一个用于查找对应行记录的主键值。(非叶子节点不包含主键)
(2)Innodb二级索引,索引列值全相同的情况下,节点按主键值排序。
(3)二级索引键值的顺序和聚簇索引键值顺序通常不同,所以二级索引做范围查询读取记录的性能通常不如聚簇索引高效(查询的列不存在二级索引时需要回表,回表操作会有大量的随机IO)。
是否使用索引排序取决于使用索引的成本
在满足了使用索引排序的条件(上文提及不可用索引排序的情况)的前提下,是否使用索引、使用哪个索引取决于使用索引的成本。
设有表 t(id, create_at),主键为id,同时有索引 index(create_at)。不同查询索引 index(create_at) 的使用情况:
(1)SELECT id FROM t WHERE create_at='2019年10月15日' ORDER BY id 和 SELECT create_at FROM t WHERE create_at='2019年10月15日' ORDER BY id

等值查询,create_at='2019年10月15日'的节点在 索引 index(create_at)结构中按主键(id)的顺序存储,因此使用index(create_at)可以避免排序,同时因为覆盖了所有列,无需回表(Extra 出现 Using index)
(2)SELECT * FROM t WHERE create_at='2019年10月15日' ORDER BY id

等值查询,create_at='2019年10月15日'的节点在 索引 index(create_at)结构中按主键(id)的顺序存储,因此使用index(create_at)可以避免排序,虽然需要回表但是通过索引可以过滤大部分的数据,成本低于使用聚簇索引
(3)SELECT * FROM t WHERE create_at>'2019年10月15日' ORDER BY id

索引 index(create_at) 不包含所有数据,因此使用 index(create_at)做范围查询,每读取每条记录都需要回表查询,会有大量的随机IO,同时,此时在index(create_at)上id是无序的,所以性能不如直接使用聚簇索引。所以该查询使用主键,通过对主键的聚簇索引进行扫描,只需要过滤掉不满足条件的值而不需要排序
范围查询,需要回表,回表操作会有大量的随机IO
(4)SELECT create_at FROM t WHERE create_at>'2019年10月15日' ORDER BY id
SELECT id FROM t WHERE create_at>'2019年10月15日' ORDER BY id

此查询因为索引 index(create_at) 包含所需列,不需要回表查询,因此使用index(create_at) 可以扫描更少的行,成本低于使用主键索引。
参考
- 推荐阅读:浅谈InnoDB中的聚簇索引和二级索引[译]
- order by 原理以及优化
- MySQL——优化ORDER BY语句
- MySQL官网



















