一、说明
自动编码器是一种无监督学习的神经网络模型,主要用于降维或特征提取。常见的自动编码器包括基本的单层自动编码器、深度自动编码器、卷积自动编码器和变分自动编码器等。
其中,基本的单层自动编码器由一个编码器和一个解码器组成,编码器将输入数据压缩成低维数据,解码器将低维数据还原成原始数据。深度自动编码器是在单层自动编码器的基础上增加了多个隐藏层,可以实现更复杂的特征提取。卷积自动编码器则是针对图像等数据特征提取的一种自动编码器,它使用卷积神经网络进行特征提取和重建。变分自动编码器则是一种生成式模型,可以用于生成新的数据样本。
总的来说,不同类型的自动编码器适用于不同类型的数据和问题,选择合适的自动编码器可以提高模型的性能。
二、在Minist数据集实现自动编码器
2.1 概述
本文中的代码用于在 MNIST 数据集上训练自动编码器。自动编码器是一种旨在重建其输入的神经网络。在此脚本中,自动编码器由两个较小的网络组成:编码器和解码器。编码器获取输入图像,将其压缩为 64 个特征,并将编码表示传递给解码器,然后解码器重建输入图像。自动编码器通过最小化重建图像和原始图像之间的均方误差来训练。该脚本首先加载 MNIST 数据集并规范化像素值。然后,它将图像重塑为一维表示,以便可以将其输入神经网络。之后,使用tensorflow.keras库中的输入层和密集层创建编码器和解码器模型。自动编码器模型是通过链接编码器和解码器模型创建的。然后使用亚当优化器和均方误差损失函数编译自动编码器。最后,自动编码器在归一化和重塑的MNIST图像上训练25个epoch。通过绘制训练集和测试集在 epoch 上的损失来监控训练进度。训练后,脚本绘制一些测试图像及其相应的重建。此外,还计算了原始图像和重建图像之间的均方误差和结构相似性指数(SSIM)。
下图显示了模型的良好拟合,可以看到模型的良好拟合。
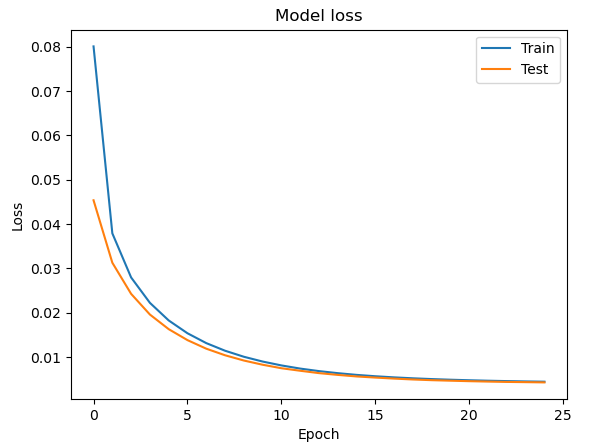
该代码比较两个图像,一个来自测试集的原始图像和一个由自动编码器生成的预测图像。它使用该函数计算两个图像之间的均方误差 (MSE),并使用 scikit-image 库中的函数计算两个图像之间的结构相似性指数 (SSIM)。根据 mse 和 ssim 代码检索test_labels以打印测试图像的值。msessim
2.2 代码实现
import numpy as np
import tensorflow
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Flatten
from tensorflow.keras.layers import Layer
from skimage import metrics
## import os can be skipped if there is nocompatibility issue
## with the OpenMP library and TensorFlow
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"# Load the MNIST dataset
(x_train, train_labels), (x_test, test_labels) = mnist.load_data()# Normalize the data
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.# Flatten the images
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))# Randomize both the training and test
permutation = np.random.permutation(len(x_train))
x_train, train_labels = x_train[permutation], train_labels[permutation]
permutation = np.random.permutation(len(x_test))
x_test, test_labels = x_test[permutation], test_labels[permutation]
# Create the encoderlist_xtest = [ [x_test[i], test_labels[i]] for i in test_labels]
print(len(list_xtest)) encoder_input = Input(shape=(784,))
encoded = Dense(64, activation='relu')(encoder_input)
encoder = Model(encoder_input, encoded)# Create the decoder
decoder_input = Input(shape=(64,))
decoded = Dense(784, activation='sigmoid')(decoder_input)
decoder = Model(decoder_input, decoded)# Create the autoencoder
autoencoder = Model(encoder_input, decoder(encoder(encoder_input)))lr_schedule = tensorflow.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate = 5e-01, decay_steps = 2500, decay_rate = 0.75,staircase=True)
tensorflow.keras.optimizers.Adam(learning_rate = lr_schedule,beta_1=0.95,beta_2=0.99,epsilon=1e-01)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')# Train the autoencoder
history = autoencoder.fit(x_train, x_train,epochs=25,batch_size=512,shuffle=True,validation_data=(x_test, x_test))# Plot the training history
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()# Plot the test figures vs. predicted figures
decoded_imgs = autoencoder.predict(x_test)def mse(imageA, imageB):err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)err /= float(imageA.shape[0])return errdef ssim(imageA, imageB):return metrics.structural_similarity(imageA, imageB,channel_axis=None)decomser = []
decossimr = []
n = 10
list_xtestn = [ [x_test[i], test_labels[i]] for i in range(10)]
print([list_xtestn[i][1] for i in range(n)])
plt.figure(figsize=(20, 4))
for i in range(n):# Display originalax = plt.subplot(2, n, i + 1)plt.imshow(x_test[i].reshape(28, 28))plt.gray()ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)# Display reconstructionax = plt.subplot(2, n, i + 1 + n)plt.imshow(decoded_imgs[i].reshape(28, 28))plt.gray()ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)if mse(list_xtestn[i][0],decoded_imgs[i]) <= 0.01: msel = mse(list_xtestn[i][0],decoded_imgs[i])decomser.append(list_xtestn[i][1]) if ssim(list_xtestn[i][0],decoded_imgs[i]) > 0.85:ssiml = ssim(list_xtestn[i][0],decoded_imgs[i])decossimr.append(list_xtestn[i][1]) print("mse and ssim for image %s are %s and %s" %(i,msel,ssiml))
plt.show() print(decomser)
print(decossimr)
三、实验的部分结果示例
该模型可以预测手写数据,如下所示。

此外,使用MSE和ssim方法将预测图像与测试图像进行比较,可以访问test_labels并打印预测数据。

此代码演示如何使用自动编码器通过图像比较教程来训练和建立手写识别网络。一开始,训练和测试图像是随机的,因此每次运行的图像集都不同。
在另一篇文章中,我们将展示如何使用 Padé 近似值作为自动编码器 (link.medium.com/cqiP5bd9ixb) 的激活函数。
引用:
- 原始的MNIST数据集:LeCun,Y.,Cortes,C.和Burges,C.J.(2010)。MNIST手写数字数据库。AT&T 实验室 [在线]。可用: http://yann。莱昆。com/exdb/mnist/
- 自动编码器概念和应用:Hinton,G.E.和Salakhutdinov,R.R.(2006)。使用神经网络降低数据的维数。科学, 313(5786), 504–507.
- 使用自动编码器进行图像重建:Masci,J.,Meier,U.,Cireşan,D.和Schmidhuber,J.(2011年52月)。用于分层特征提取的堆叠卷积自动编码器。在人工神经网络国际会议(第 59-<> 页)中。施普林格,柏林,海德堡。
- The tensorflow.keras library: Chollet, F. (2018).使用 Python 进行深度学习。纽约州谢尔特岛:曼宁出版公司
- 均方误差损失函数和亚当优化器:Kingma,D.P.和Ba,J.(2014)。Adam:一种随机优化的方法。arXiv预印本arXiv:1412.6980。
- 结构相似性指数(SSIM):Wang,Z.,Bovik,A.C.,Sheikh,H.R.和Simoncelli,E.P.(2004)。图像质量评估:从错误可见性到结构相似性。IEEE图像处理事务,13(4),600-612。
-
弗朗西斯·贝尼斯坦特
·












)




串口中断接收)

