一、介绍
分类问题在机器学习领域很常见。正如我们所知,在分类问题中,我们试图通过研究输入数据或预测变量来预测类标签,其中目标或输出变量本质上是分类变量。
如果您已经处理过分类问题,那么您一定遇到过以下情况:其中一个目标类标签的观察数明显低于其他类标签。这种类型的数据集称为不平衡类数据集,在实际分类场景中非常常见。解决此类机器学习问题的任何常用方法通常都会产生不适当的结果。
在本文中,我将讨论不平衡的数据集、有关其预测的问题,以及如何比传统方法更有效地处理此类数据。本文作为数据科学博客马拉松的一部分发布。
目录
- 介绍
- 什么是不平衡数据以及如何处理它?
- 处理不平衡数据分类时出现的问题
- 处理数据集不平衡问题的方法
- 1. 选择合适的评估指标
- 2. 重采样(过采样和欠采样)
- 3. 斯莫特
- 4. 平衡dBagging分类器
- 5. 阈值移动
- 从网格中搜索最佳值
- 结论
- 常见问题解答
二、什么是不平衡数据以及如何处理它?
不平衡数据是指目标类的观测值分布不均匀的数据集类型,即一个类标签的观测值数量非常多,而另一个类标签的观测值数量非常少。
我们可以通过一个例子来更好地理解不平衡的数据集处理。
假设 XYZ 是一家向客户发行信用卡的银行。现在,银行担心一些欺诈易正在发生,当银行检查他们的数据时,他们发现每笔2000笔交易只有30个欺诈记录。因此,每 100 笔交易的欺诈数量不到 2%,或者我们可以说超过 98% 的交易本质上是“无欺诈”。在这里,“无欺诈”类称为多数类,而规模小得多的“欺诈”类称为少数类。

更多这样的不平衡数据的例子是:
- 疾病诊断
- 客户流失预测
- 欺诈检测
- 自然灾害
在分类问题中,类不平衡通常是正常的。但是,在某些情况下,这种不平衡非常严重,因为多数阶级的存在率远高于少数阶级。
三、处理不平衡数据分类时出现的问题
如果我们用非常简单的方式解释它,不平衡数据集预测的主要问题是我们实际上预测多数和少数阶级的准确性如何?让我们用疾病诊断的例子来解释它。假设我们将从现有数据集预测疾病,其中每 100 条记录中只有 5 名患者被诊断出患有该疾病。因此,多数阶层是 95% 没有疾病,少数阶层只有 5% 患有疾病。现在,假设我们的模型预测 100 名患者中有 100 名没有疾病。
有时,当某个类的记录比另一个类多得多时,我们的分类器可能会偏向于预测。在这种情况下,分类问题的混淆矩阵显示了我们的模型对目标类别的分类程度,并且我们从混淆矩阵得出了模型的准确性。它是根据模型正确预测的总数除以预测总数计算得出的。在上述情况下,它是 (0+95)/(0+95+0+5)=0.95 或 95%。这意味着该模型无法识别少数类别,但模型的准确率得分为 95%。因 这样,我们传统的分类和模型精度计算方法在不平衡数据集的情况下没有用处。

四、处理数据集不平衡问题的方法
在欺诈检测或疾病预测等极少数情况下,正确识别少数群体至关重要。因此,模型不应该偏向于只检测多数阶级,而应该对少数阶级给予同等的权重或重要性。在这里,我将讨论一些可以处理此问题的少数技术。这没有正确的方法或错误的方法,不同的技术可以很好地解决不同的问题。
1 . 选择合适的评估指标
分类器的准确度是分类器正确预测的总数除以预测的总数。对于一个平衡良好的类来说,这可能足够好,但对于不平衡的类问题来说并不理想。其他指标(如 precision)是衡量分类器对特定类的预测的准确性的度量,召回率是衡量分类器识别类的能力。
对于不平衡的类数据集,F1 分数是更合适的指标。它是精确度和召回率的调和平均值,表达式是——

因此,如果分类器预测了少数类,但预测是错误的,并且误报增加,则精度指标将较低,因此 F1 分数。此外,如果分类器对少数类的识别能力很差,即该类中更多人被错误地预测为多数类,那么假阴性将会增加,因此召回率和 F1 分数会降低。只有当预测的数量和质量都得到提高时,F1 分数才会增加。
F1 分数保持精确率和召回率之间的平衡,并且仅当分类器正确识别特定类的更多内容时才提高分数。
2 重采样(过采样和欠采样)
此技术用于对少数类或多数类进行上采样或下采样。当我们使用不平衡的数据集时,我们可以使用替换对少数类进行过采样。这种技术称为过采样。同样,我们可以从多数类中随机删除行,以将它们与少数类匹配,这称为欠采样。对数据进行采样后,我们可以得到多数类和少数类的平衡数据集。因此,当两个类在数据集中具有相似数量的记录时,我们可以假设分类器将对这两个类给予同等的重要性。

为了说明目的,下面显示了使用 sklearn 库的 resample() 的该技术的示例。在这里,Is_Lead 是我们的目标变量。让我们看看目标中类的分布。
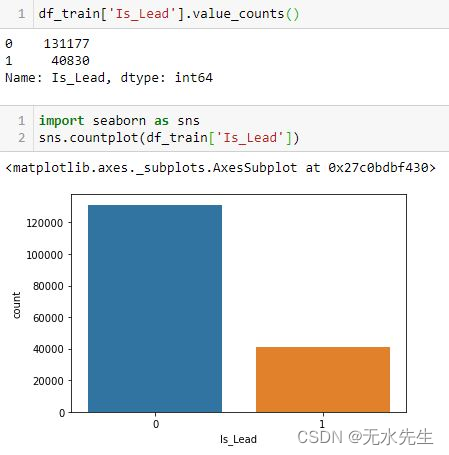
据观察,我们的目标类别存在不平衡。因此,我们将尝试对数据进行上采样,以便少数类与多数类匹配。
from sklearn.utils import resample
#create two different dataframe of majority and minority class
df_majority = df_train[(df_train['Is_Lead']==0)]
df_minority = df_train[(df_train['Is_Lead']==1)]
# upsample minority class
df_minority_upsampled = resample(df_minority, replace=True, # sample with replacementn_samples= 131177, # to match majority classrandom_state=42) # reproducible results
# Combine majority class with upsampled minority class
df_upsampled = pd.concat([df_minority_upsampled, df_majority])上采样后,类的分布平衡如下:
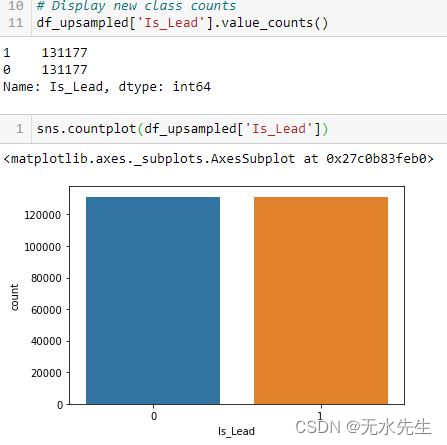
Sklearn.utils 重采样可用于对多数类实例进行欠采样和过采样少数类实例。
3. 斯莫特
合成少数族裔过采样技术或 SMOTE 是对少数族裔类别进行过采样的另一种技术。简单地添加少数类的重复记录通常不会向模型添加任何新信息。在 SMOTE 中,新实例是从现有数据合成的。如果我们用简单的话来解释,SMOTE研究少数类实例,并使用k最近邻来选择一个随机的最近邻,并在特征空间中随机创建一个合成实例。
我将在下面展示相同的代码示例:
from imblearn.over_sampling import SMOTE
# Resampling the minority class. The strategy can be changed as required.
sm = SMOTE(sampling_strategy='minority', random_state=42)
# Fit the model to generate the data.
oversampled_X, oversampled_Y = sm.fit_sample(df_train.drop('Is_Lead', axis=1), df_train['Is_Lead'])
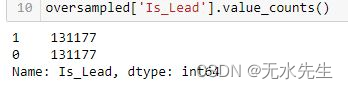
oversampled = pd.concat([pd.DataFrame(oversampled_Y), pd.DataFrame(oversampled_X)], axis=1)现在,该类已平衡如下
4. 平衡dBagging分类器
当我们尝试使用通常的分类器对不平衡的数据集进行分类时,该模型偏爱多数类,因为它的体积更大。BalancedBaggingClassifier 与 sklearn 分类器相同,但具有额外的平衡。它包括一个额外的步骤,用于在拟合给定采样器时平衡训练集。此分类器采用两个特殊参数“sampling_strategy”和“替换”。sampling_strategy决定所需的重采样类型(例如,“多数”——仅对多数类进行重采样,“所有”——对所有类进行重采样等),替换决定它是否将是带有替换的样本。
下面给出一个说明性的例子:
from imblearn.ensemble import BalancedBaggingClassifier
from sklearn.tree import DecisionTreeClassifier
#Create an instance
classifier = BalancedBaggingClassifier(base_estimator=DecisionTreeClassifier(),sampling_strategy='not majority',replacement=False,random_state=42)
classifier.fit(X_train, y_train)
preds = classifier.predict(X_test)5. 阈值移动
在我们的分类器中,很多时候分类器实际上预测了类成员资格的概率。我们根据通常为 0.5 的阈值将这些预测的概率分配给某个类别,即如果概率< 0.5,则它属于某个类别,如果不是,则属于另一个类别。
对于不平衡的类问题,此默认阈值可能无法正常工作。我们需要将阈值更改为最佳值,以便它可以有效地分离两个类。此外,我们还可以使用 ROC 曲线和精确召回率曲线来找到分类器的最佳阈值。我们还可以使用网格搜索方法或在一组值中搜索来识别最佳值。
五、从网格中搜索最佳值
在这种方法中,我们将首先找到类标签的概率,然后我们将找到将概率映射到其正确类标签的最佳阈值。预测概率可以通过使用 sklearn 的 predict_proba() 方法从分类器中获得。
rom sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier()
rf_model.fit(X_train,y_train)
rf_model.predict_proba(X_test) #probability of the class label
Output:array([[0.97, 0.03],[0.94, 0.06],[0.78, 0.22],...,[0.95, 0.05],[0.11, 0.89],[0.72, 0.28]])
After getting the probability we can check for the optimum value.step_factor = 0.05
threshold_value = 0.2
roc_score=0
predicted_proba = rf_model.predict_proba(X_test) #probability of prediction
while threshold_value <=0.8: #continue to check best threshold upto probability 0.8temp_thresh = threshold_valuepredicted = (predicted_proba [:,1] >= temp_thresh).astype('int') #change the class boundary for predictionprint('Threshold',temp_thresh,'--',roc_auc_score(y_test, predicted))if roc_score<roc_auc_score(y_test, predicted): #store the threshold for best classificationroc_score = roc_auc_score(y_test, predicted)thrsh_score = threshold_valuethreshold_value = threshold_value + step_factor
print('---Optimum Threshold ---',thrsh_score,'--ROC--',roc_score)输出:
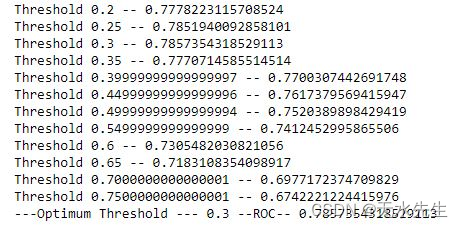
在这里,我们得到 0.3 中的最佳阈值,而不是默认的 0.5。
六、结论
总之,有效解决不平衡的数据对于分析中的准确分类至关重要。所讨论的这五种技术可以大大提高模型性能。对于那些希望提高分析技能并深入研究数据科学的人,可以考虑注册 Analytics Vidhya 的 BB+ 计划,这是一个面向有抱负的数据科学家的综合学习平台。
常见问题解答
一个。处理不平衡数据集的三种方法是:
a) 重采样:对少数类别进行过采样,对多数类别进行过采样不足,或生成合成样本。
b) 使用不同的评估指标:F1 分数、AUC-ROC 或精确召回。
c) 算法选择:选择专为不平衡而设计的算法,如 SMOTE 或集成方法。
一个。有几种算法能够有效地处理不平衡的数据。例如,Random Forest 可以通过装袋和特征选择来管理类的不平衡。SVM 可以通过分配类权重来调整,以惩罚少数类中的错误。 SMOTE 为少数类生成合成样本,有助于平衡数据集并提高模型性能。
一个。当数据集不平衡时,可能会出现几个问题。模型可能会表现出对多数类的偏向,从而导致对少数类的预测不佳。作为评估指标的准确性可能会产生误导,因为它可能看起来很高,而模型在少数群体上的表现却不足。在实际应用中,处理不平衡的数据可能会带来重大挑战,可能会影响决策,尤其是在必须准确预测的关键领域。
参考资料:
What is Imbalanced Data | Techniques to Handle Imbalanced Data (analyticsvidhya.com)



)


)



)








