一、为什么需要隔离级别?——图书馆的借阅危机
想象小明的图书馆只有一本《MySQL索引优化》,三位读者同时操作:
读者A:查库存(1本),准备借走(未登记)
读者B:见库存未减,也申请借阅
读者C:仅查询库存
若无规则约束:A和B同时借书 → 库存变为-1(数据错乱)
事务隔离级别就是数据库的“借阅规则”,通过控制事务间的可见性与相互影响,在数据一致性与并发性能间取得平衡:
规则越严(如串行化):数据安全,但性能下降
规则越松(如读未提交):性能高,但可能读到“假数据”
二、四大隔离级别深度剖析
2.1 读未提交(Read Uncommitted)——草稿随便看
图书馆规则
读者C能直接看到A写在草稿纸上的“借走1本,库存0”(未提交修改),即使A后续划掉草稿(回滚)。
⚠️ 数据风险
脏读:读到未确认的修改(如C误判库存为0)
不可重复读:两次查询结果不同(A的草稿被登记后库存突变)
幻读:范围查询结果行数变化(A插入新书未保存)
⚙️ 底层实现
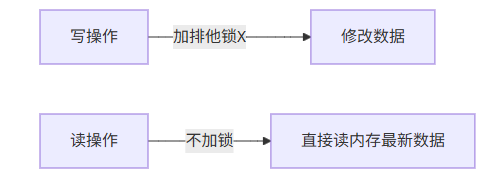
锁策略:写加X锁,读不加锁
无MVCC:不生成ReadView,直接读未提交数据
适用场景
几乎不用!仅适用于实时显示“谁在编辑”等非精确统计场景。
2.2 读已提交(Read Committed)——只看正式登记
图书馆规则
读者C仅当A在台账正式登记(提交事务)后,才能看到库存变为0。若A划掉草稿(回滚),台账不变。
✅ 解决问题
脏读:屏蔽未提交修改
⚠️ 仍存问题
不可重复读:同一事务内多次读取结果不同
-- 事务A首次查询:库存=1
SELECT stock FROM books WHERE id=1;
-- 事务B提交UPDATE stock=0
UPDATE books SET stock=0 WHERE id=1; COMMIT;
-- 事务A再次查询:库存=0(不可重复读)
SELECT stock FROM books WHERE id=1;幻读:范围查询结果行数变化
⚙️ 底层实现(MVCC核心)
每次SELECT生成新ReadView:
struct ReadView {trx_ids_t m_ids; // 活跃事务ID列表trx_id_t min_trx_id; // 最小活跃事务IDtrx_id_t max_trx_id; // 下一个待分配事务IDtrx_id_t creator_trx_id; // 创建者事务ID
};可见性判断:
trx_id < min_trx_id→ 已提交,可见trx_id在活跃列表中 → 不可见否则 → 已提交且可见
适用场景
读多写少系统(如新闻评论区)。Oracle/PostgreSQL默认级别。
2.3 可重复读(Repeatable Read)——我的台账我锁定
图书馆规则
读者C开始查询时,管理员给其一份专属台账副本(快照)。后续无论A如何修改正式台账,C的副本始终是初始值。
✅ 解决问题
脏读(同读已提交)
不可重复读:事务内多次读取结果一致
⚠️ 幻读问题(标准SQL允许)
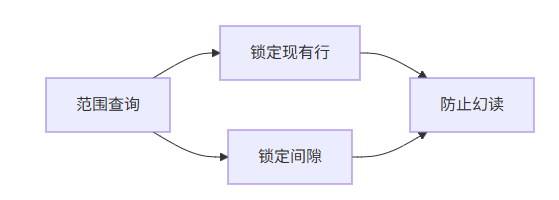
MySQL的增强方案:通过Next-Key Lock(行锁+间隙锁)锁定查询范围,阻止新行插入
-- 锁定(10, +∞)区间的行和间隙
SELECT * FROM books WHERE id>10 FOR UPDATE;⚙️ 底层实现事务启动时生成唯一ReadView:整个事务复用该快照
Next-Key Lock机制:
适用场景
大多数业务系统(如电商下单)。MySQL InnoDB默认级别。
2.4 串行化(Serializable)——一次只许一人操作
图书馆规则
读者A进入借阅室(开启事务)后锁门,其他读者需在门外等待。A登记完成(提交)后,下一位才能进入。
✅ 解决问题
脏读、不可重复读、幻读全解决
⚠️ 代价
性能极差:事务串行执行,并发度为1
⚙️ 底层实现
严格两阶段锁(Strict 2PL):读加共享锁(S锁),写加排他锁(X锁)事务结束时一次性释放所有锁
范围锁:锁定整个查询区间(甚至表锁)
适用场景
强一致性场景(如银行转账核心逻辑)。
三、Undo Log的生死簿:Insert Undo vs Update Undo
3.1 两类Undo Log的使命
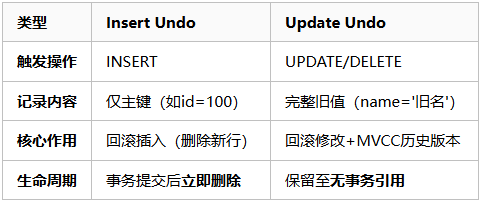
3.2 为何区别对待?
Insert Undo:仅用于回滚插入操作提交后无残留价值(新行已可见)不包含MVCC所需历史版本
Update Undo:承载MVCC版本链(通过
roll_ptr指针链接)可能被长事务跨事务回滚引用由Purge线程异步清理(当无事务引用时)
关键案例:RC级别下长事务回滚依赖Update Undo
-- 事务A(长事务)首次查询:name='李四'
SELECT name FROM users WHERE id=1;
-- 事务B提交UPDATE:name='王五'(生成Update Undo)
UPDATE users SET name='王五' WHERE id=1; COMMIT;
-- 事务A再次查询:RC级别下读新值'王五'(生成新ReadView)
SELECT name FROM users WHERE id=1;
-- 事务A回滚:需通过Update Undo恢复'李四'(若未被Purge)
ROLLBACK;四、数据库实现差异与选择策略
4.1 主流数据库实现对比
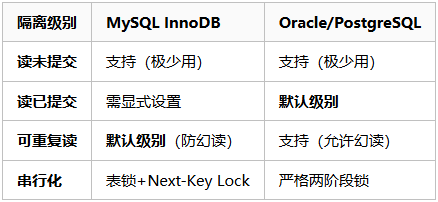
4.2 隔离级别选择黄金法则
1、优先使用默认级别:MySQL → RR(平衡安全与性能)Oracle/PG → RC(读多写少优化)
2、按场景选择:
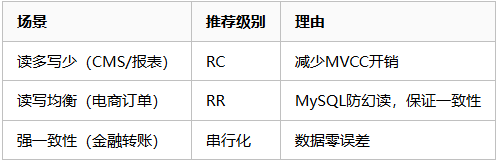
3、避坑指南:禁止生产环境使用读未提交非核心操作(如日志)可用REQUIRES_NEW独立事务
五、总结:隔离级别的本质是权衡艺术
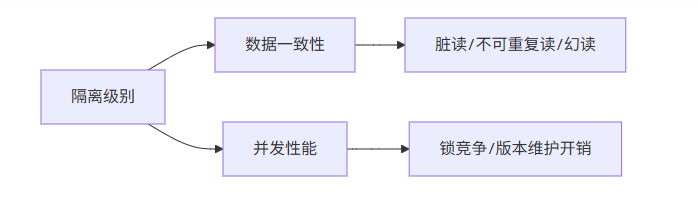
读未提交:裸奔模式,性能最高,数据最不可靠
读已提交:折中方案,屏蔽脏读,允许不可重复读
可重复读:主流选择,事务内视图稳定(MySQL防幻读)
串行化:绝对安全,性能代价高昂
核心口诀:
RC:每次查询刷新快照("喜新厌旧")
RR:事务启动锁定快照("从一而终")
Undo Log:Insert Undo用完即焚,Update Undo留作史册
四大事务隔离级别与数据风险关系总结
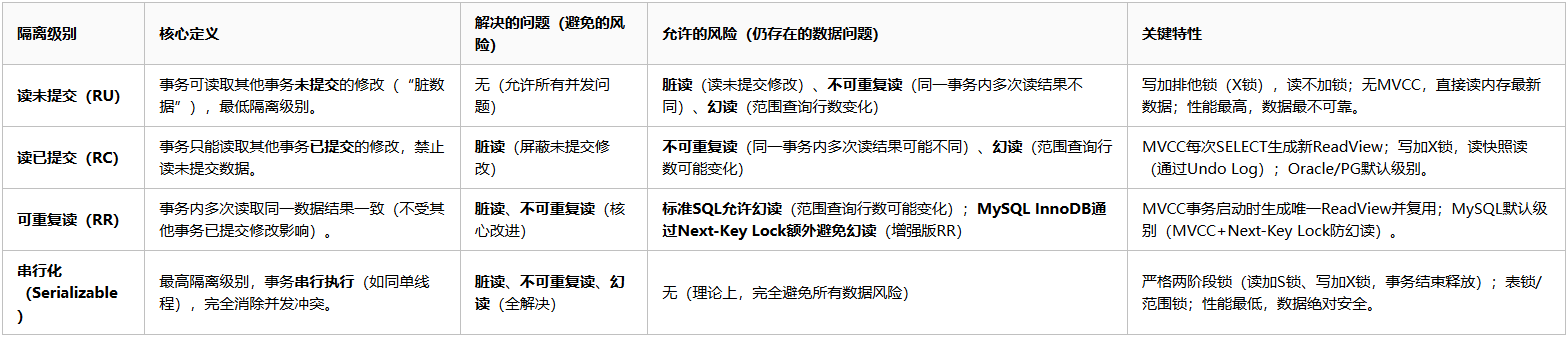
核心结论:
隔离级别与数据风险呈“级别↑→风险↓→性能↓”的反向关系:
级别越低(RU):允许脏读、不可重复读、幻读全风险,性能最高(无隔离开销);
级别越高(Serializable):彻底消除所有风险,性能最低(串行执行+严格锁);
RC/RR为平衡之选:RC屏蔽脏读(读多写少场景),RR保证事务内视图稳定(MySQL防幻读,多数业务默认)。
本质是数据一致性与并发性能的量化权衡——无“最好”级别,只有“最适合业务场景”的选择。
理解隔离级别,就是掌握在数据正确与系统高效间走钢丝的艺术。根据业务场景理性选择,方能构建高可靠应用!
文章转载自:佛祖让我来巡山
原文链接:https://www.cnblogs.com/sun-10387834/p/19246724
体验地址:http://www.jnpfsoft.com/?from=001YH





)








 - lscpu)




