某品牌数据采集
采集需求
地址:http://www.winshangdata.com/brandList
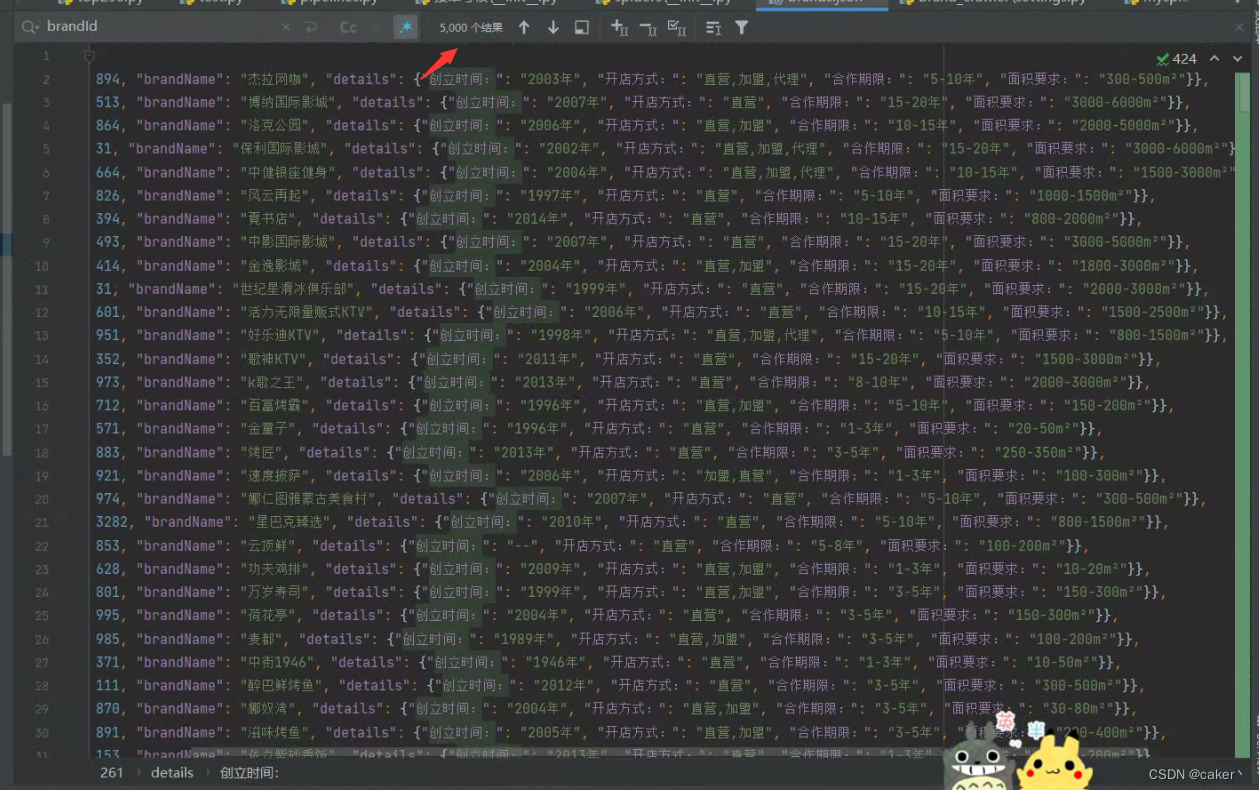
需求:用scrapy框架采集本站数据,至少抓取5个分类,数据量要求5000以上
采集字段:标题、创建时间、开店方式、合作期限、面积要求
网页分析
进入网站后页面如下
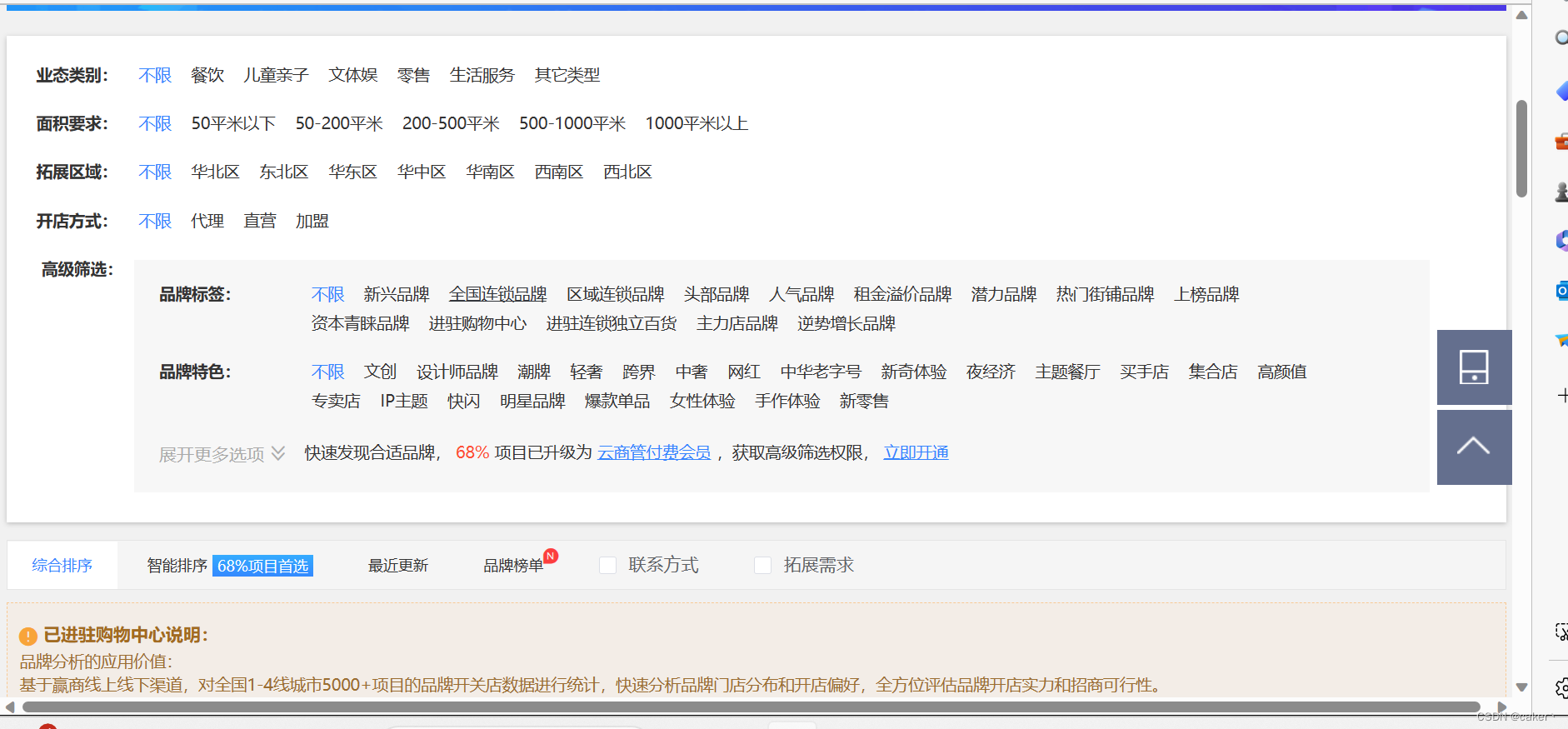

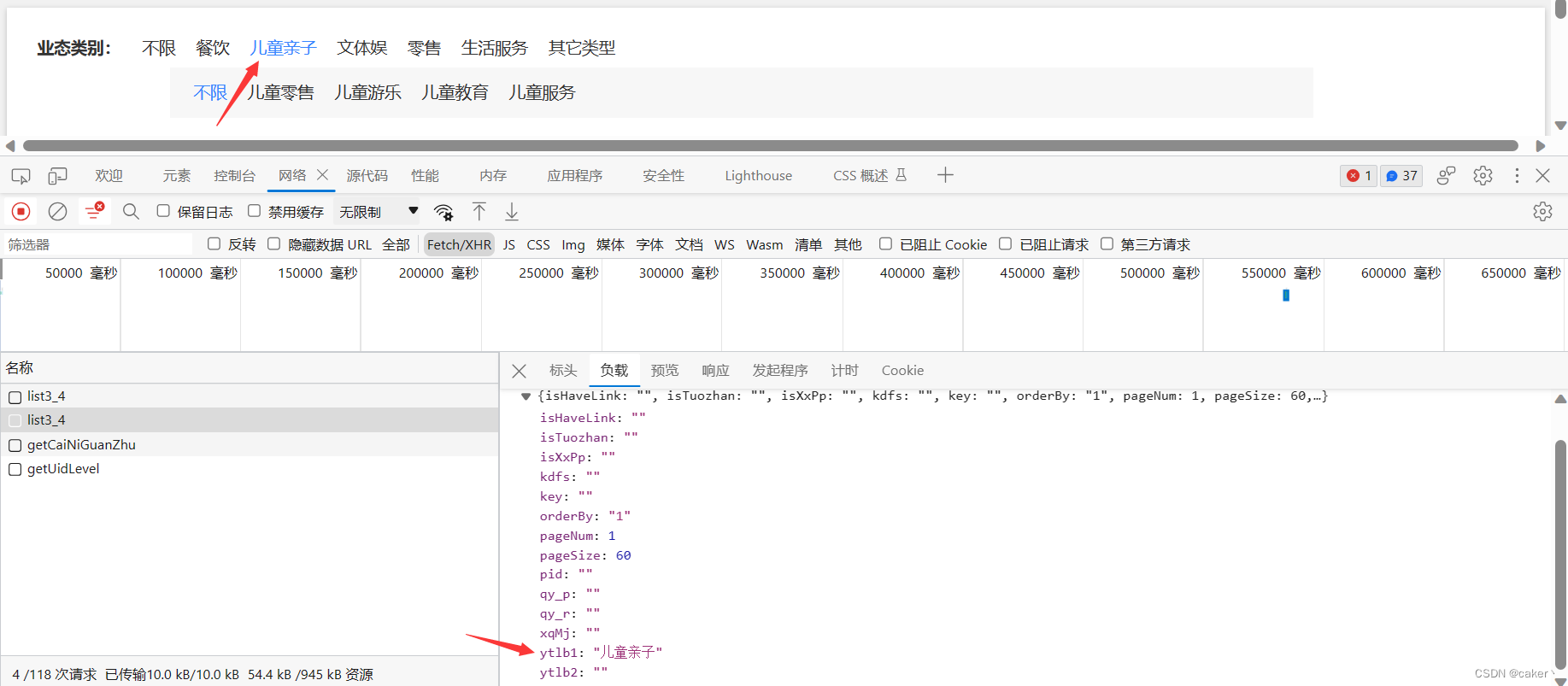
打开f12切换到网络这一栏,刷新网页或者点击下一页抓取请求

分析返回的json数据发现,只能获取到我们需要的标题、面积要求
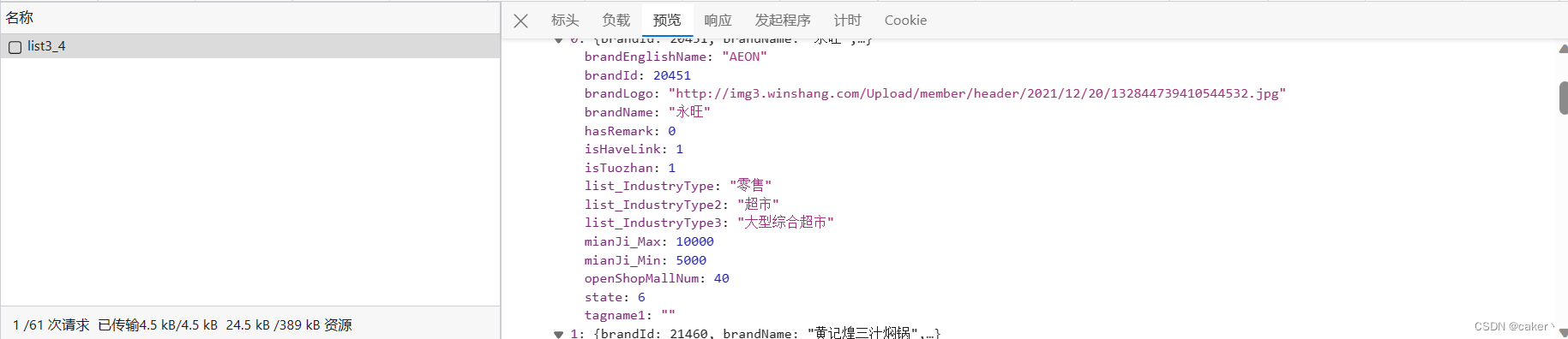
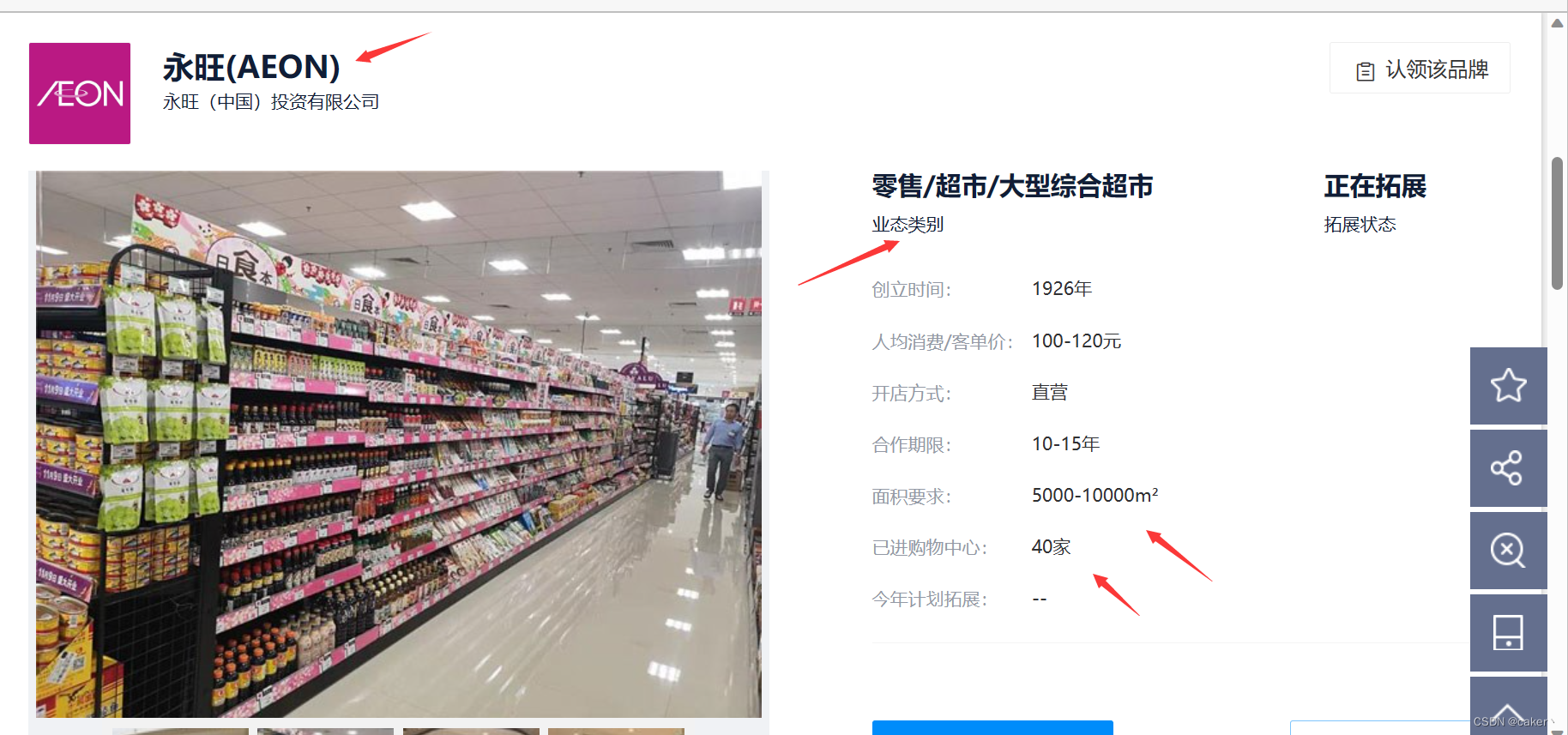
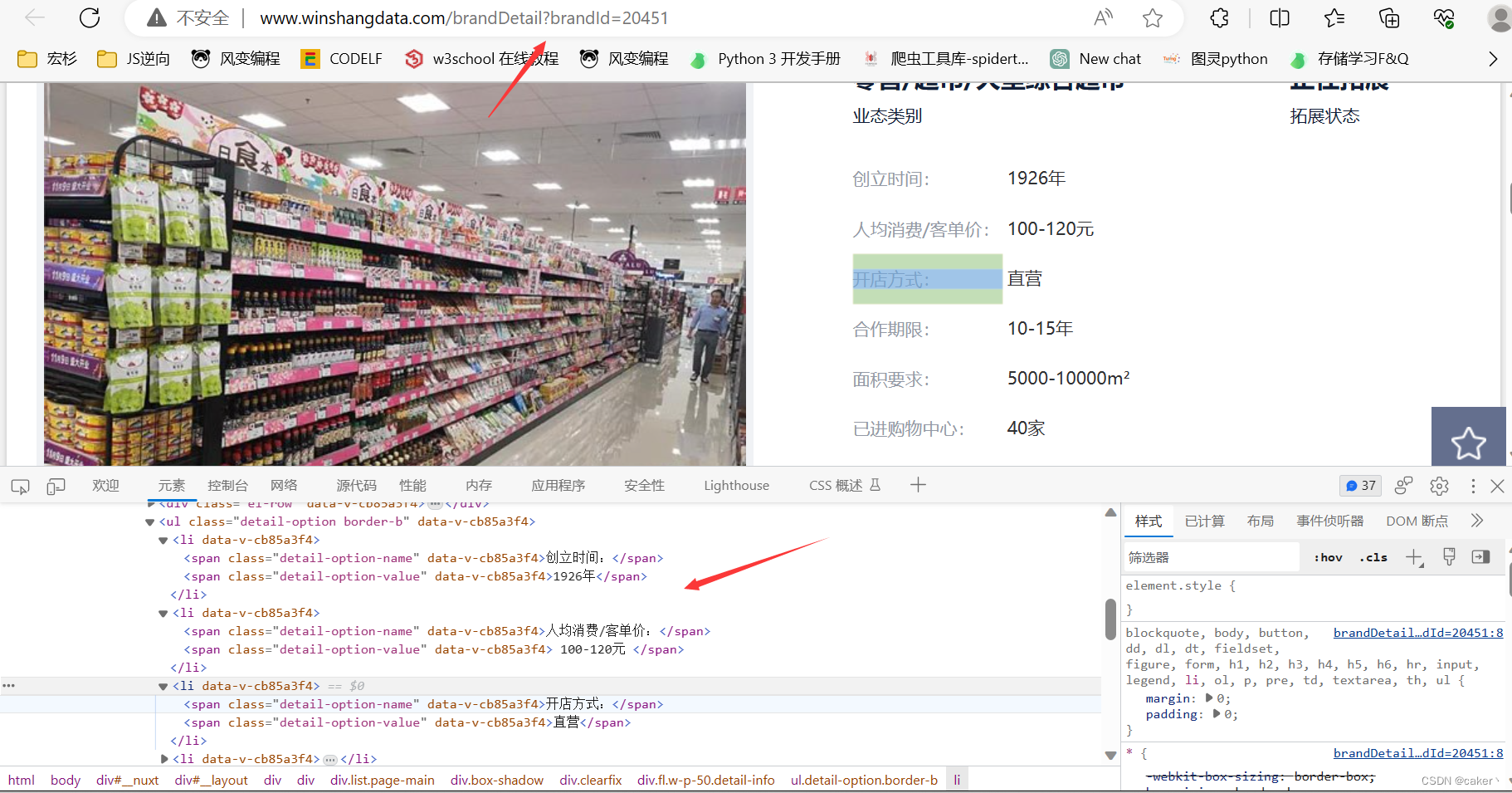
所以我们需要进入网页详情页面进行分析,进入详情页面后发现我们剩下所需的参数都是在网页的li标签中,所以我们可以通过xpath等方式获取,而网页跳转的brandId参数在我们之前获取的json包中可以获取
由于题目要求需要抓取5个分类,接下来再分析业务类别是怎么实现的
点击不同类别的标签分析xhr请求发现,分类主要通过ytlb1参数进行实现,而翻页则通过pageNum进行实现,pageSize参数可以选择一页可以爬取多少元素
到此我们网页基本分析完毕,爬虫的大致流程为
- 先爬取http://www.winshangdata.com/wsapi/brand/list3_4,获取返回包中的
brandId,brandName两个参数 - 将获取的brandId参数,重新构造url:http://www.winshangdata.com/brandDetail?brandId=,然后通过构造Xpath语句获取li标签中的span标签中的我们需要的数据
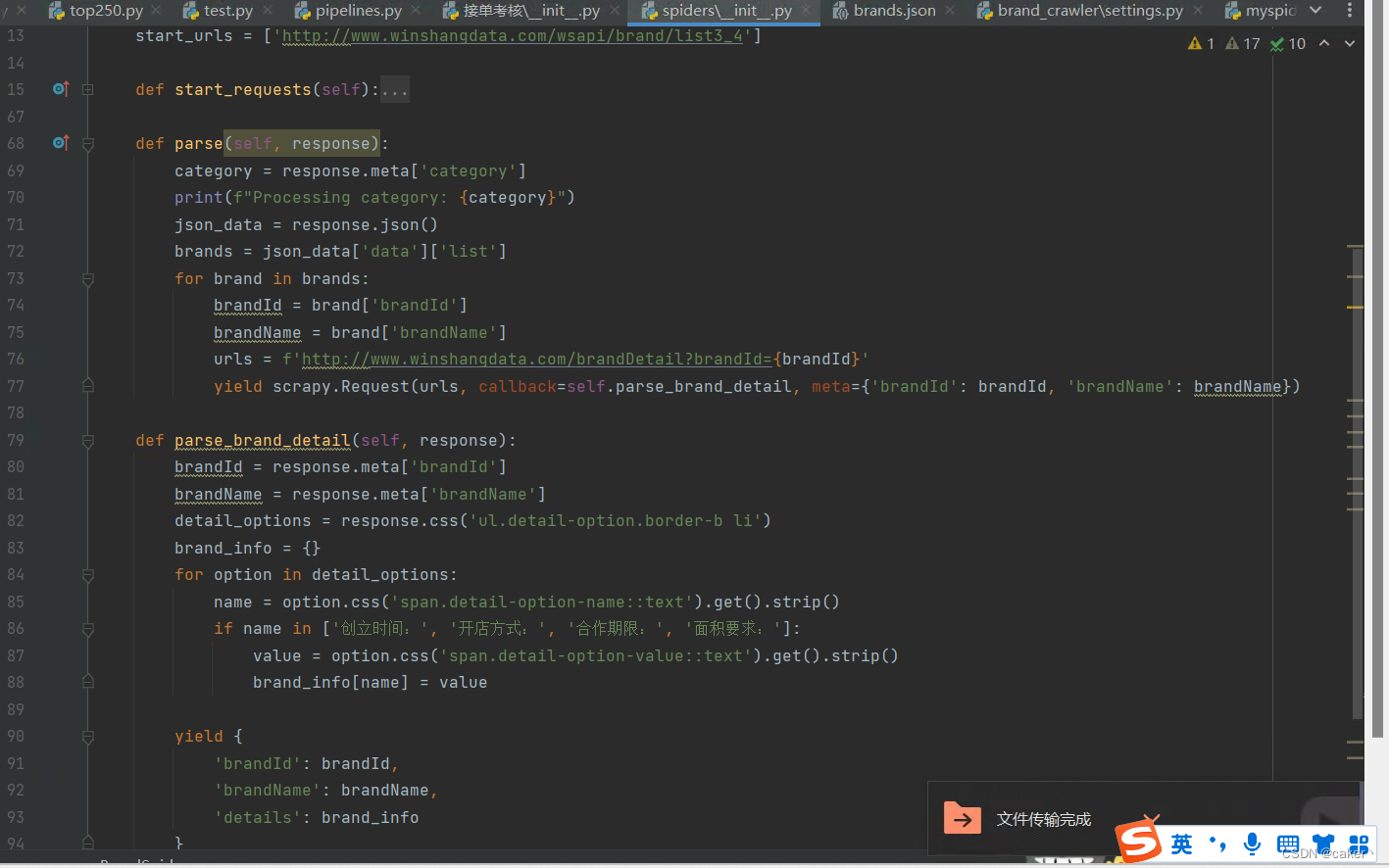
代码实现
全部代码这里就不展示了,这里只展示核心代码,有需要的可以私信找我。
结果展示

)










)

函数,格式(CAST AS decimal))




