目录
Softmax函数
定义
输入输出
例子
总结
Layernorm
定义
输入输出
Sigmoid函数
定义
Tanh函数
定义
Relu函数
定义
Elu函数
定义
Gelu函数
定义
总结
Softmax函数
定义
softmax函数又称归一化指数函数,其作用是将一个 n 维的实值向量转换为概率分布。其数学公式如下:
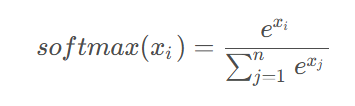
-
是输入向量的第 i 个元素
-
是向量维度
-
是自然对数的底数,
-
是归一化因子,即所有类别原始得分指数化的总和。它确保了所有输出概率的总和为1。
由于是e指数,并且是归一化操作,因此我们可以得出Softmax的特性。
- 非负性。指数函数
总是为正数。
- 归一化。所有输出概率的总和为1。
- 范围。每个概率都严格在[0,1]之间。
输入输出
输入:是一个实数n维向量,其中每个元素可以是任意实数,代表了模型对不同类别的原始倾向性。
输出:是一个概率分布向量,其中每个元素都是一个介于0到1之间的实数,表示输入样本属于对应类别的概率,并且所有元素的和为1。
例子
假设我们有一个3分类问题(猫、狗、鸟),神经网络的最后一层输出为Z=[z猫,z狗,z鸟]=[2.0,1.0,0.1],当应用Softmax函数时,其计算过程如下:

因此,经过Softmax归一化后的输出为P=[0.659,0.242,0.099],从这个输出向量中,我们可以看到这个向量对预测这个样本是“猫”的概率最高(约65.9%),其次是“狗”(约24.2%),最后是“鸟”(约9.9%)。
总结
- Softmax的输入和输出都是n维向量,输出是针对输入进行归一化操作,来将实值向量转换为概率分布向量。
Layernorm
定义
一种在神经网络中对单个训练样本的所有特征进行归一化的技术。对于一个输入样本,LayerNorm 会在每个特征维度上进行归一化,使得每个特征的均值为0,方差为1,通过解决“内部协变量偏移”问题,来提高模型的训练效果和泛化能力。数学公式如下:
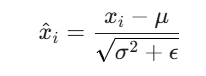
表示均值
表示方差
一个很小是参数如
,用于数值稳定性,防止分母为0
为了保留模型的表达能力,LayerNorm引入了两个可学习的参数:
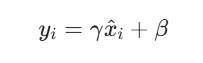
缩放因子,用于缩放归一化后的值
偏移因子,用于平移归一化后的值。
内部协变量偏移特指在深度神经网络的训练过程中,由于前一层参数的变化,导致后一层的输入数据分布发生变化的现象。简单来说,当你在训练一个深度神经网络时,每一层的参数都在不断更新。当前一层的参数更新后,它会产生新的输出。这个新的输出,对于紧随其后的下一层来说,就是它的“输入”。由于前一层的输出分布(即下一层的输入分布)发生了变化,这就像下一层在不断面对一个“移动的目标”或“变化的输入数据分布”。
以传话这个例子举例,比如一句话“小明爱吃苹果”,一个好的模型应该在将这句话传达给最后一个人时,最后一个人仍能理解原来说的是“小明爱吃苹果”,但如果发生内部协变量偏移,比如第一个人传递是对的,且队伍前面的人为了让最终信息传递更准确,会不断调整自己的传话方式,你(中间的层)会发现,你从前面那人听到的“口音”和“风格”总在变(比如可能是用粤语传递,可能是用潮汕话传递等)。你得不断适应这种变化的“输入”,导致自己很难稳定地学习如何把话传好。因此,就出现了内部协变量偏移,而LayerNorm就相当于一个标准翻译员,无论前面的人怎么说,他总能把话翻译成你熟悉的、统一的格式。这样,你就能专心把自己的部分做好,而不用担心前面的人不断改变“口音”了。
输入输出
- 输入:n 维向量
- 输出:n维归一化向量
LayerNorm是对单个数据的指定维度进行Norm处理,与batch无关,因此意味着在LayerNorm中,每个样本都有自己的均值和方差;与Batch Norm相比,体现在方向的不同,LayerNorm是横向归一化,Batch Norm是纵向归一化,具体区别如下:

Sigmoid函数
定义
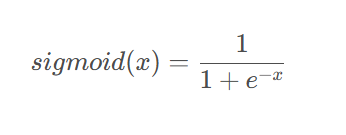
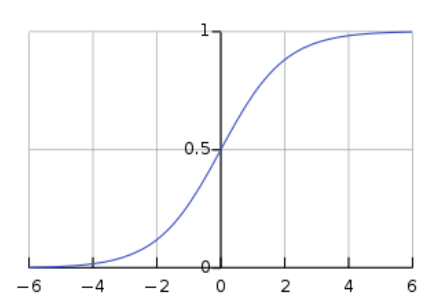
图像是一个S形的曲线,目的是将输入向量进行归一化。早期使用的激活函数,目前较少使用。
特点
- 将输出映射到概率空间,很适合作为二分类问题的输出层激活函数(因为可以解释为概率)。
- 平滑性:可微分,方便反向传播
- 非线性函数
缺点
- 梯度消失。当输入 x 的值非常大或非常小(负数)时,函数的梯度会非常接近于0(微分趋于0。)。这意味着在反向传播时,梯度会变得非常小,导致网络权重更新缓慢,深层网络难以训练。
- 非零中心输出。输出总是正的。这会导致下一层神经元的输入总是同号,从而在权重更新时引起“锯齿”效应,减慢收敛速度。
- 计算成本高。需要进行指数运算,计算量较大。
补充解释:
- 在深度神经网络中,梯度的计算是通过链式法则从输出层向输入层逐层反向传播的。当梯度通过多个层时,如果每一层的梯度(来自激活函数的导数)都小于1(尤其是接近0),那么这些小数相乘的结果会迅速变得极小,甚至趋近于0。这导致越靠近输入层的权重,接收到的梯度信号就越微弱,从而无法有效地学习。(因为要根据输出层的梯度来更新输入层的权重)
- 锯齿效应是指在优化神经网络权重时,优化器的更新路径不是直接沿着最快下降的方向走向损失函数的最小值,而是来回震荡(呈现锯齿状),从而大大减缓了收敛速度。锯齿效应体现在对权重的梯度影响,由于激活函数输出非负,因此上一层所有神经元的输出 = 当前的神经元的输入 都是正数,那么在反向传播时,计算当前神经元权重的梯度时,通常会涉及到当前神经元输入
的乘积。这意味着,所有权重的梯度
(损失函数对当前神经元某个权重的梯度)将同时具有相同的符号(要么全正,要么全负)。而当所有权重梯度符号相同时,它们的更新方向也是一致的(要么全部增加,要么全部减少)。你可以想象你在走路下山时,在左脚往前的过程中,右脚也必须往前。实际上,为达到最优解,某些权重需要增加,而另一些权重需要减少。但如果所有权重的梯度总是同向的,那么就无法实现这一点。我们要实现的是螺旋式上升的效果,要有所上升就必须要在这过程中有所下降,下降和上升的配合是为了更好地上升。
Tanh函数
定义
Tanh函数的图像与 Sigmoid 函数类似,都是一个S形曲线。不同的是,Sigmoid函数输出范围是(0,1),Tanh函数输出范围是(-1,1)。当输入 x 趋近于正无穷时,输出趋近于 1;当输入 x 趋近于负无穷时,输出趋近于 -1;当 x=0 时,输出为 0。
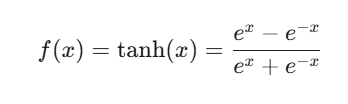
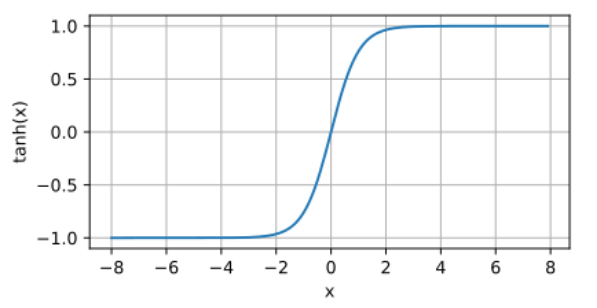
特点:
- 零中心化输出 :Tanh 的输出以 0 为中心(即均值为 0),这是它相对于 Sigmoid 的一个显著优势,Tanh函数激活后有正有负。零中心化的输出有助于缓解“锯齿效应”问题,因为它可以使下一层神经元的输入均值更接近零,从而可能加快梯度下降的收敛速度。
- 比 Sigmoid 梯度更强:体现在曲线的中间部分(非饱和区)坡度更陡了,这通常意味着更强的梯度信号,有助于更快的学习。
- 可微分:处处可导,方便反向传播
缺点:
- 梯度消失问题: 尽管比 Sigmoid 稍好,但 Tanh 仍然存在梯度消失问题。当输入 x 的绝对值很大时(即处于饱和区),其导数仍然会非常接近 0。在深层网络中,这会导致靠近输入层的梯度非常小,使得这些层难以学习。
- 计算成本相对较高:设计到指数运算。
用途:在 ReLU 激活函数出现之前,Tanh 常常被用作循环神经网络 (RNN) 的隐藏层的默认激活函数,以及作为普通神经网络隐藏层的激活函数(如用于BERT的pooler层),因为它比 Sigmoid 表现更好。
Relu函数
定义
Relu函数相当于一个分段函数,在x大于0的部分采用线性函数,没有采用指数进行运算,降低了计算成本。
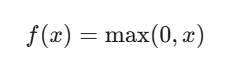
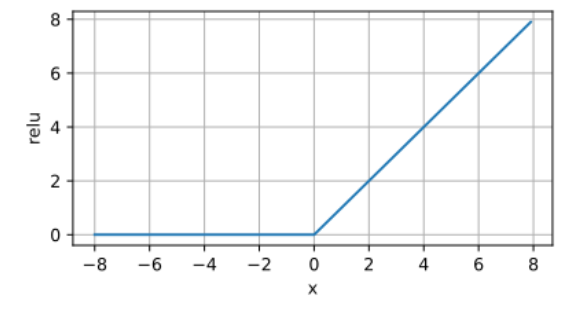
函数的做法是在0和x取最大值,这意味着当 x>0 时,输出为 x;当 x≤0 时,输出为 0。因此Relu函数输出范围是[0, +∞),x=0处有一个拐点。
特点:
- 解决了梯度消失问题(针对正区间):在x>0处,Relu函数的导数恒为1。这意味着在正区间,梯度不会随着层数的加深而衰减,从而有效缓解了深度网络中的梯度消失问题,使得深层网络能够更快地学习。而在Sigmoid和Tanh函数中,当x位于饱和区时,函数的导数值很小,从而出现梯度消失。[ 你的目的是下山(梯度下降),导数值相当于下山速度,如果下山深度太慢,是不是就相当于你停留在山上了(梯度消失)]。
- 计算效率高:没有指数运算,ReLU 的计算非常简单,只需进行一个简单的阈值判断。
- 稀疏性:对于负输入,ReLU 的输出为 0(你在迈出左脚时,可以保持右脚不动),这导致神经元的激活是稀疏的(即并非所有神经元都会被激活)。稀疏性有助于提高模型的泛化能力,并减少过拟合。
- 加速收敛:与使用 Sigmoid 或 Tanh 相比,网络收敛速度更快。
缺点:
- 死亡 ReLU 问题 : 当输入 x≤0 时,ReLU 的导数为 0。这意味着如果一个神经元在训练过程中,其输入总是负数,那么它的梯度将永远为 0,导致该神经元的权重永远不会被更新,这个神经元就“死亡”了,不再学习。这可能会减少网络的有效容量。
- 非零中心输出: 和 Sigmoid 一样,ReLU 的输出是非零中心化的(总是非负),这可能导致训练过程中出现“锯齿效应”,从而略微减慢收敛速度。(仍然会出现迈出左脚时,需要右脚也同步迈出)
- 不可微性: 在 x=0 处不可导。但在实际应用中,这通常不是问题,因为我们可以使用次梯度(subgradient)或者简单地将 x=0 处的导数定义为 0 或 1。
用途:ReLU 及其各种变体(如 Leaky ReLU, PReLU, ELU, GELU 等)是目前卷积神经网络 (CNN) 和普通前馈神经网络隐藏层中最常用、默认的激活函数。
Elu函数
定义
ELU 函数旨在结合 ReLU 的优点,并解决其“死亡 ReLU”问题,同时使激活值的均值更接近零,从而加快学习速度。具体地,对于x < 0的部分采用指数函数来进行优化。
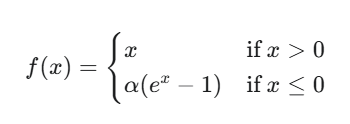
α 是一个超参数,通常设置为正数,比如 1.0。如下图所示

- 当 x>0 时,ELU 的行为与 ReLU 相同,输出就是输入 x。
- 当 x≤0 时,ELU 的输出是一个指数衰减的曲线,平滑地趋近于 −α
- 输出范围是 (−α,+∞)
特点:
- 解决了“死亡 ReLU”问题:死亡Relu问题是由于Relu函数负区间导数为0,而Elu函数由于在负区间有一个非零的输出,并且梯度不为零(导数为
),因此即使输入为负,神经元也能持续学习和更新,避免了 ReLU 的“死亡”问题。
- 使激活值均值更接近零: ELU 允许输出为负值,这有助于将激活值的均值推向零。均值接近零的激活值可以使梯度更接近单位自然梯度,从而减少内部协变量偏移的影响,并可能加速学习。
- 平滑的负区间: 在负区间的曲线是平滑的, 有助于减少梯度下降的震荡,可能带来更好的泛化能力。
- 保留 ReLU 优点: 在正区间不饱和,梯度不会消失,计算相对高效
缺点:
- 计算成本较高:涉及指数运算。
- 超参数α。需要手动设置α这个超参数,超参的不同可能会影响模型的性能,不够统一。
用途:在某些任务和网络架构中被证明比 ReLU 具有更好的性能和更快的收敛速度,尤其是在更深的网络中。它常常被用作 ReLU 的一个替代品。
Gelu函数
定义
Gelu全称Gaussian Error Linear Unit / 高斯误差线性单元,其函数是近年来在大型预训练模型中变得非常流行的一种激活函数,特别是在 Transformer 架构中。它旨在以一种更平滑、更随机的方式引入非线性。Gelu是目前基于Transformer架构下的模型常用的激活函数,比如BERT和ViT。
公式:
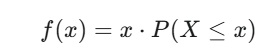
其中 是一个标准正态分布的随机变量, P(
) 是标准正态分布的累积分布函数 (CDF)
。更简洁的公式如下:
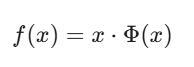
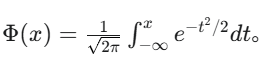
在实际实现中,通常使用其近似公式(因为它包含 erf 误差函数):
![]()
GELU 可以被看作是一种结合了 ReLU 的非线性和 Dropout 的随机正则化效果的激活函数。它不是简单地通过阈值来“门控”输入(如 ReLU 对负值直接置零),而是根据输入值在标准正态分布中的百分位数来“权重”输入。从图片我们可以看出在[-2,0]区间是与Relu函数最大的不同之处。
- 当 x 越大,Φ(x) 越接近 1,输出越接近 x。
- 当 x 越小,Φ(x) 越接近 0,输出越接近 0。
- 由于 Φ(x) 是平滑的,GELU 在 x=0 附近比 ReLU 更平滑,提供了更柔和的梯度。
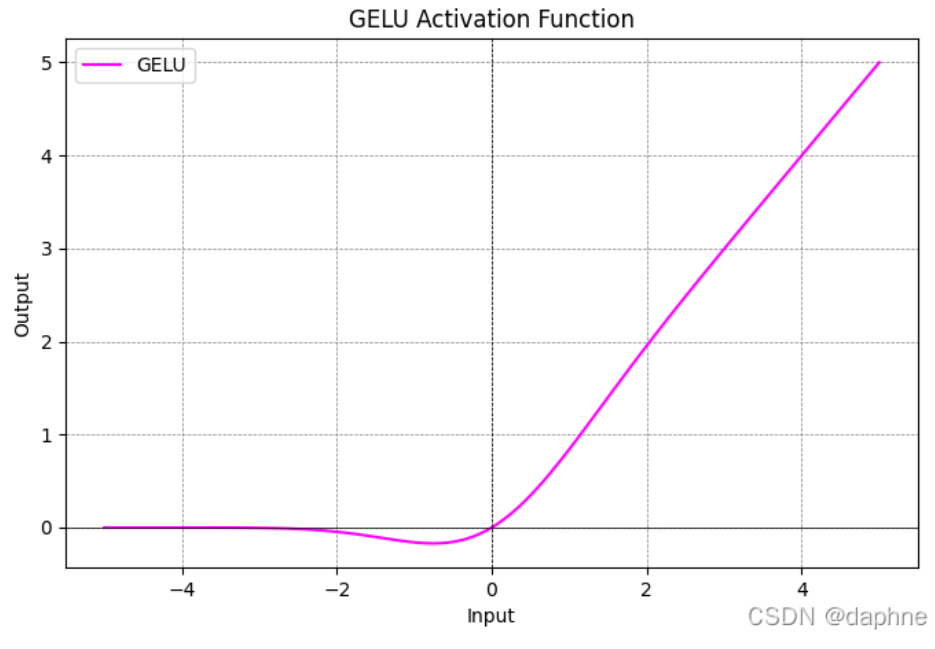
特点:
- 性能卓越:在许多最先进的大型模型(特别是 Transformer 架构)中,GELU 已经显示出比 ReLU 和 ELU 更好的性能。
- 平滑性:相比 ReLU 的硬性阈值(小于0区域统一取值为0,因此导数为0),GELU 的平滑特性使其在梯度计算时更稳定(在小于0的部分可以求导,且曲线平滑),减少了训练过程中的震荡
- 输出负值: 允许输出负值,这有助于激活值的均值更接近零,从而可能减少内部协变量偏移的影响。
- 非单调性:其独特的非单调性(在负区间有一个小“凹陷”)被认为有助于模型捕捉更复杂的模式。
- 与 Dropout 兼容: 设计思想上融合了随机性,与 Dropout 等正则化技术有内在联系
缺点:
- 计算复杂度高: 包含指数函数或误差函数(及其近似),计算成本高于 ReLU,但现代深度学习框架通常有高效的实现。
总结
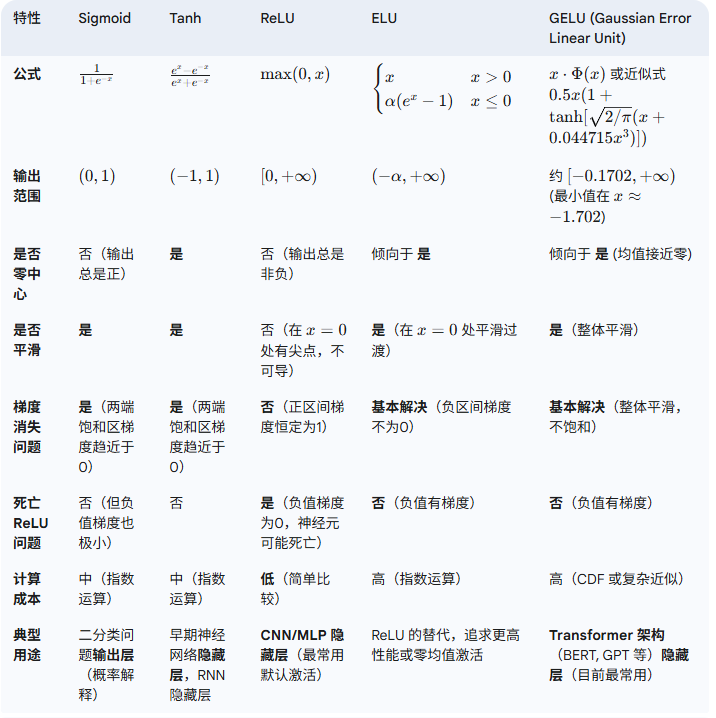







 接口)



:数据流图)







