本文是实验设计与分析(第6版,Montgomery著傅珏生译)第7章2k析因的区组化和混区设计第7.4节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
许多问题中,在一个区组中进行一析因设计的完全重复是不可能的。混区设计(confounding)是一种设计方法,它将一个完全的析因设计安排在多个区组之内,区组的大小比一次重复中的处理组合的个数要小。这一方法使得关于特定处理效应(通常是高阶的交互作用)的信息与来自区组的信息不可区分或者说混杂。本章集中讨论2k析因设计的混区设计。即使是由于每一区组不包含所有的处理或处理组合而出现不完全区组设计,但是对于2k析因系统的特殊结构,也将有简化的分析方法。
我们考虑有2p个不完全区组的2k析因设计的结构和分析方法,其中p<k。因此,这些设计将实在两个区组内(p=1),4个区组内(p=2)、8个区组内(p=3),等等。
假定要实施一个单次重复的22设计。比如说,22=4个处理组合的每一个需用一定量的原材料,而每批原材料只够供给两个处理组合去试验。这样一来,就需要两批原材料。如果把原材料的批次看作区组,则我们必须把这4种处理组合中的两种分派给每个区组。
图7.1表示对此问题的一种可能设计。图7.1(b)是几何观点,表示把相反对角线上的处理组合分派给不同的区组。图7.1(b)中,区组1包含处理组合(1)和ab。区组2包含a和b。当然,在同一区组内的个处理组合的实施顺序是随机确定的。先实施哪一区组的试验也是随机决定的。假定没有划分区组而来估计A和B的主效应。由(6.1)式和6.2)式得
![]()
因为每一估计量都有来自每个区组的一个加号的处理组合和一个减号的处理组合,所以A和B都不受划分区组的影响.也就是说,区组1和区组2之间的差异抵消了。
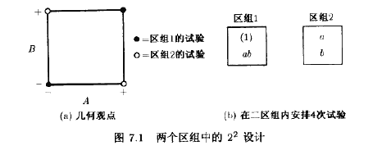
今考忠AB的交互作用
![]()
因为两个带加号的处理组合[ab和(1)]都在区组1,两个带减号的处理组合(a和b)都在区组2,所以区组数应和AB的交互作用是一致的,也就是说,AB与区组混杂了。
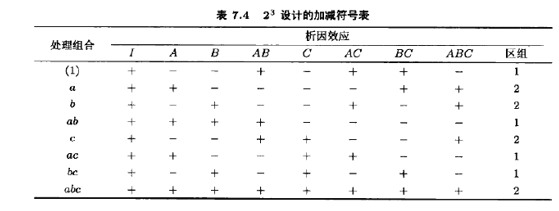
这一点可以从22设计的加减符号表中容易看出。此表原先在表6.2中给出,为方便起见,重列于表7.3。由此表可见,AB上带加号的处理组合都安排在区组1,而AB上带减号的处理组合都安排在区组2。这种方式可用来把任一效应(A,B,AB)与区组相混。例如,如果(1)和b安排到区组1,a和ab安排到区组2,则主效应A与区组相混。通常的实践是把高阶交互作用与区组相混。

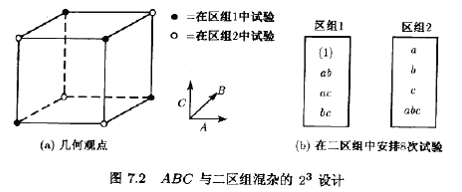
这个方案可用来混杂任意二区组中的2k设计。作为第二个例子,考虑二区组的23设计。设我们想把三因子交互作用ABC与区组相混。由表7.4的加减符号表,我们把ABC中带碱号的处理组合分在区组1,ABC中带加号的处理组合分在区组2。所得的设计如图7.2所示。我们再次强调,在一区组内的处理组合的试验顺序是随机的
- 构造区组的其他方法
2.误差的估计
当变量的个数较小时,比方说k=2或3,通常必须进行重复以求得误差的估计量。例如,假定需要进行有两个区组的ABC被混杂的23析因实验,实验者决定进行4次里复。设计如图7.3所示。在每次重复中ABC都被混杂。
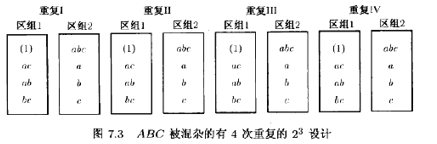
此设计的方差分析见表7.5,有32个观测值和31个总的自由度。又因为有8个区组,所以和这些区组有关的必须是7个自由度。7个自由度的一种分解如表7.5所示。误差平方和实际上由重复和每个效应(A,B,C,AB,AC,BC)之间的二因子交互作用所组成。将交互作用看作为零,并把它们的均方值看作为误差的估计量通常是不会有问题的。主效应和二因子交互作用都是相对均方误差进行检验的。Cochran and Cox(1957)指出,区组或ABC均方可以和由ABC提供的均方误差进行比较,它实际上是由重复×区组提供的。这一检验法通常是很不灵敏的。
如果资源充足,允许混区设计做重复,则一般说来,在每次重复时采用稍有不同的设计区组方法会较好一些。这一处理方法是在各次重复中泡杂不同的效应,以便求得关于所有效应的一些信息。这样的方法称为部分混区设计,7.7节会给予讨论。如果k适当大,比方说k≥4,则经常只数一次重复就行了,实验者通常假定高阶交互作用可被忽略并将它们的平方和组合起来作为误差。因子效应的正态概率图对这一点十分有帮助。
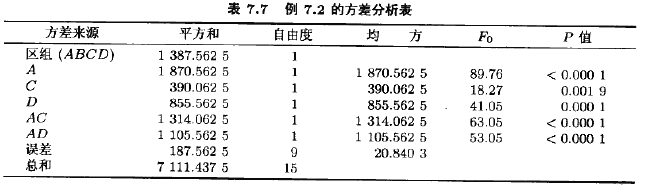
例7,2考忠例6.2描述的情况。回想4个因子:温度(A),压强(B)、甲醛的浓度(G)和境排速度(D)。在试验性工厂中研究这些因子:以确定影响产品渗透率的效应。我们用这个实验来说明在一个无重复设计中区组化和混杂的思想。我们对最初的实验作了两处修改。首先,假定一批原材料不能进行全部24=16个处理组合的试验。一批原材料只能进行8个处理组合的试验,所以,采用二区组的2混区设计看来是恰当的。将高阶交互作用ABCD与区组混杂也是很自然的,定义对照是
L=x1十x2+x3+x4
容易证明,此设计如图7.4所示。另外,可以检在表6.12。观测被安排到区组1的ABCD列中的标为“+”的处理组合,以及区组2的ABCD列中的标为“一”的处理组合。
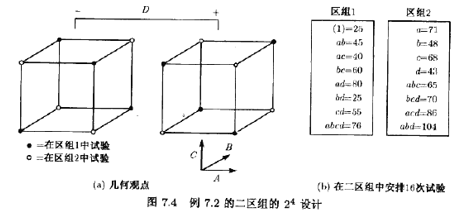
我们作的第二处修改是引入区组效应,以说明区组的作用。假定我们选择两批原材料来进行实验,其中之一质量较差,因此,用这批材料得到的平均啊应低于那些用好的质量的材料20个单位。质量差的批次为区组L,质量好的批次为区组2(哪个批次为区组1,哪个批次为区组2无关紧要)。先做区组1的试验(当然,区组里的8个试验是按随机次序进行的),但是,响应低于那些用好的质量材料的20个单位,图7.4b显示了响应的结果--注意到它们是可以由例6.2给出的原始观测减去区组效应得到的。即,处理组合(1)的原始响应为45,图7.4b中报告为(1)=25(=45-20)。该区组的其地响应也可以类似得到。做完区组1的试验后,接着做区组2的8个试验,这个批次的原材料没有问题,所以,响应和它们最初在例6.2中的非常一致。
表7.6所列的是例6.2的“修改”观点的效应估计。注意到4个主效应,6个二因子交互作用、4个三因子交互作用的估计和没有区组效应的例6.2得到的效应估计一样。计算效应估计的通常比例后,可以看出因子A,C,D和AC交互作用以及AD交互作用是重要效应,与原始实验一样。(读者应当确认这一点)
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
import pandas as pd
import statsmodels.api as sm
from sklearn import linear_model
import seaborn as sns
import matplotlib.pyplot as plt
import mistat
from scipy import special
from scipy.stats import ncx2
x5 = [1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1,-1]
x1 = [-1,-1,-1,-1,1,1,1,1, -1,-1,-1,-1,1,1,1,1]
x2 = [-1,-1,1,1,-1,-1,1,1,-1,-1,1,1,-1,-1,1,1]
x3 = [-1,1,-1,1,-1,1,-1,1,-1,1,-1,1,-1,1,-1,1]
x4 = [1,-1,-1,1,-1,1,1,-1,-1,1,1,-1,1,-1,-1,1]
y1 = [43,68,48,70,71,86,104,65,25,55,25,60,80,40,45,76]
data = {"y1":y1,"x1":x1,"x2":x2,"x3":x3,"x4":x4,"x5":x5}
data=pd.DataFrame(data)
model1 = smf.ols(formula='data.y1 ~ C(data.x5)+data.x1+data.x2+data.x3+data.x4+data.x1*data.x2+data.x1*data.x3+data.x1*data.x4+data.x2*data.x3+data.x2*data.x4+data.x3*data.x4+data.x1*data.x2*data.x3+data.x1*data.x2*data.x4+data.x1*data.x3*data.x4+data.x2*data.x3*data.x4', data=data).fit()
print(model1.summary2())
Results: Ordinary least squares
====================================================================
Model: OLS Adj. R-squared: nan
Dependent Variable: data.y1 AIC: -920.6635
Date: 2024-04-25 10:16 BIC: -908.3021
No. Observations: 16 Log-Likelihood: 476.33
Df Model: 15 F-statistic: nan
Df Residuals: 0 Prob (F-statistic): nan
R-squared: 1.000 Scale: inf
--------------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
--------------------------------------------------------------------
Intercept 50.7500 inf 0.0000 nan nan nan
C(data.x5)[T.1] 18.6250 inf 0.0000 nan nan nan
data.x1 10.8125 inf 0.0000 nan nan nan
data.x2 1.5625 inf 0.0000 nan nan nan
data.x3 4.9375 inf 0.0000 nan nan nan
data.x4 7.3125 inf 0.0000 nan nan nan
data.x1:data.x2 0.0625 inf 0.0000 nan nan nan
data.x1:data.x3 -9.0625 inf -0.0000 nan nan nan
data.x1:data.x4 8.3125 inf 0.0000 nan nan nan
data.x2:data.x3 1.1875 inf 0.0000 nan nan nan
data.x2:data.x4 -0.1875 inf -0.0000 nan nan nan
data.x3:data.x4 -0.5625 inf -0.0000 nan nan nan
data.x1:data.x2:data.x3 0.9375 inf 0.0000 nan nan nan
data.x1:data.x2:data.x4 2.0625 inf 0.0000 nan nan nan
data.x1:data.x3:data.x4 -0.8125 inf -0.0000 nan nan nan
data.x2:data.x3:data.x4 -1.3125 inf -0.0000 nan nan nan
--------------------------------------------------------------------
Omnibus: 4.847 Durbin-Watson: 1.389
Prob(Omnibus): 0.089 Jarque-Bera (JB): 2.523
Skew: -0.927 Prob(JB): 0.283
Kurtosis: 3.589 Condition No.: 3
====================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors
is correctly specified.
anova_table = sm.stats.anova_lm(model1, typ=2)
anova_table
model1 = smf.ols(formula='data.y1 ~ C(data.x5)+data.x1*data.x2*data.x3*data.x4', data=data).fit()
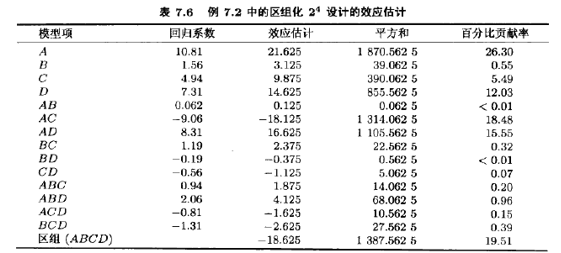
ABCD的交互效应是怎样的用?原始实验(例6.2)中该效应估计为ABCD=1.375。而在目前的例子中,ABCD交互效应的估计为ABCD=-18.625。因为ABCD与区组混杂了,用原始交互五效应(1.375)加上区组效应(-20)估计ABCD交互作用。所以ABCD=1.375+(-20)=-18.625。(你是否明白,为什么区组效应为-20?)区组效应可以用两区组平均响应间的差直接计算。即
![]()
当然,这个效应确实估计了区组十ABCD
表7.7描述了该实验的方差分析表。模型中包含了大的估计的效应。区组平方和为
![]()
该实验的结论十分符合没有区组效应的例6.2的结论。如果没有在区组中进行实验,且如果大小为-20的效应影响了前面的8个试验(它们可能按照随机方式进行的,因为16个试验在区组设计中是按照随机次序进行的),结果可能就不同。