介绍
Elasticsearch , 简称 ES ,它是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。 es 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
Elasticsearch 是面向文档 (document oriented) 的,这意味着它可以存储整个对象或文档 。然而它不仅仅是存储,还会索引 (index) 每个文档的内容使之可以被搜索。在 Elasticsearch 中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
安装
安装 Elasticsearch
# 添加仓库秘钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# 上边的添加方式会导致一个 apt-key 的警告,但是不影响# 添加镜像源仓库
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elasticsearch.list
# 更新软件包列表
sudo apt update
# 安装 es
sudo apt-get install elasticsearch=7.17.21
# 启动 es
sudo systemctl start elasticsearch
# 安装 ik 分词器插件
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21
重新启动 elasticsearch,查看其是否正常运行
sudo systemctl start elasticsearch
sudo systemctl status elasticsearch.service
设置外网访问:如果新配置完成的话,默认只能在本机进行访问。
sudo vim /etc/elasticsearch/elasticsearch.yml 新增配置
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"] 浏览器访问 http://自己主机的ip:9200/
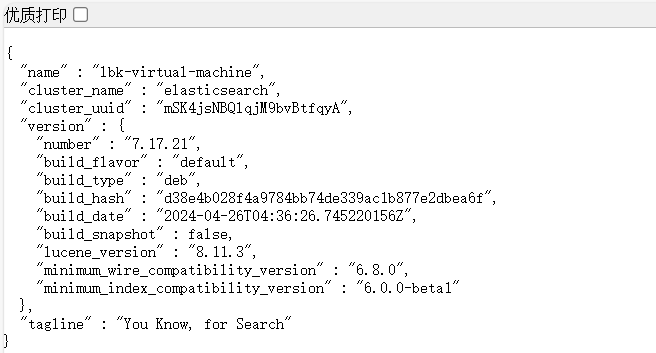
安装 Kibana
Kibana 是 Elasticsearch 的官方数据可视化和管理工具,通常与 Elasticsearch 配合使用。以下是关于它的核心解释和常见使用场景:
Kibana 的核心作用
-
数据可视化:通过图表、仪表盘(Dashboards)展示 Elasticsearch 中的索引数据,支持柱状图、折线图、地图、词云等多种可视化形式。
-
数据探索:使用 Discover 功能直接搜索和过滤 Elasticsearch 中的数据,支持全文搜索、字段过滤、时间范围筛选等。
-
索引管理:在 Management 中管理 Elasticsearch 的索引、设置索引生命周期(ILM)、定义字段映射(Mapping)等。
-
监控与告警:监控 Elasticsearch 集群的健康状态(如节点状态、分片分布),配置告警规则(Alerting),例如磁盘空间不足时触发通知。
-
开发工具:内置 Dev Tools,可直接编写和执行 Elasticsearch 的 REST API 请求(如
GET /_cat/indices)。
使用 apt 命令安装 Kibana 。
sudo apt install kibana 配置 Kibana (可选):
根据需要配置 Kibana。配置文件通常位于 /etc/kibana/kibana.yml。可能需要设置如服务器地址、端口、Elasticsearch URL 等。
sudo vim /etc/kibana/kibana.yml
#添加以下配置
elasticsearch.host: "http://localhost:9200"
server.port: 5601
server.host: "0.0.0.0"
重新启动 Kibana
sudo systemctl restart kibana
sudo systemctl enable kibana
sudo systemctl status kibana 访问 Kibana :
在浏览器中访问 Kibana ,通常是 http://<your-ip>:5601
ES 客户端的安装
代码: https://github.com/seznam/elasticlient
官网: https://seznam.github.io/elasticlient/index.html
ES C++ 的客户端选择并不多, 我们这里使用 elasticlient 库 , 下面进行安装。
# 克隆代码
git clone https://github.com/seznam/elasticlient
# 切换目录
cd elasticlient
# 更新子模块
git submodule update --init --recursive
# 编译代码
mkdir build
cd build
# 需要安装 MicroHTTPD 库
sudo apt-get install libmicrohttpd-dev
cmake -DCMAKE_INSTALL_PREFIX=/usr ..
make
# 安装
make install
ES 核心概念
索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合,类似数据库中的“库” 。比如说,你可以有一个客户数据的索引,一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
类型(Type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定,类似数据库中的“表” 。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,为评论数据定义另一个类型。不过在 7.x 版本后已弃用。
字段(Field)
字段相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。

| 分类 | 类型 | 备注 |
| 字符串 | text, keyword | text 会被分词生成索引,keyword 不会被分词生成索引,只能精确值搜索 |
| 整形 | integer, long, short, byte | |
| 浮点 | double , float | |
| 逻辑 | boolean | true 或 false |
| 日期 | date, date_nanos | “2018-01-13” 或 “2018-01-13 12:10:30” 或者时间戳,即 1970 到现在的秒数 / 毫秒数 |
| 二进制 | binary | 二进制通常只存储,不索引 |
| 范围 | range |
映射(mapping)
映射是在处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理 es 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
| 名称 | 数值 | 备注 |
| enabled | true(默认) | false | 是否仅作存储,不做搜索和分析 |
| index | true( 默认 ) | false | 是否构建倒排索引(决定了是否分词,是否被索引) |
| index_option | ||
| dynamic | true(默认)| false | 控制 mapping 的自动更新 |
| doc_value | true(默认) | false | 是否开启 doc_value ,用户聚合和排序分析,分词字段不能使用 |
| fielddata | fielddata: {"format": "disabled"} | 是否为 text 类型启动 fielddata,实现排序和聚合分析。针对分词字段,参与排序或聚合时能提高性能,不分词字段统一建议使用 doc_value。 |
| store | true | false(默认) | 是否单独设置此字段的存储而从 _source 字段中分离,只能搜索,不能获取值 |
| coerce | true(默认) | false | 是否开启自动数据类型转换功能,比如:字符串转数字,浮点转整型 |
| analyzer | "analyzer": "ik" | 指定分词器,默认分词器为 standard analyzer |
| boost | "boost": 1.23 | 字段级别的分数加权,默认值是 1.0 |
| fields | "fields": { "raw": { "type":"text", "index":"not_analyzed" } } | 对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词 |
| data_detection | true( 默认 ) | false | 是否自动识别日期类型 |
文档 (document)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档或者某个订单的一个文档。文档以 JSON ( Javascript Object Notation)格式来表示,而 JSON 是一个到处存在的互联网数据交互格式。在一个 index/type 里面,你可以存储任意多的文档。一个文档必须被索引或者赋予一个索引的 type 。
Elasticsearch 与传统关系型数据库相比如下:
ES 客户端的使用示例
在浏览器中访问 Kibana,通常是 http://<your-ip>:5601,在工具页面进行编码,使用以下语句:
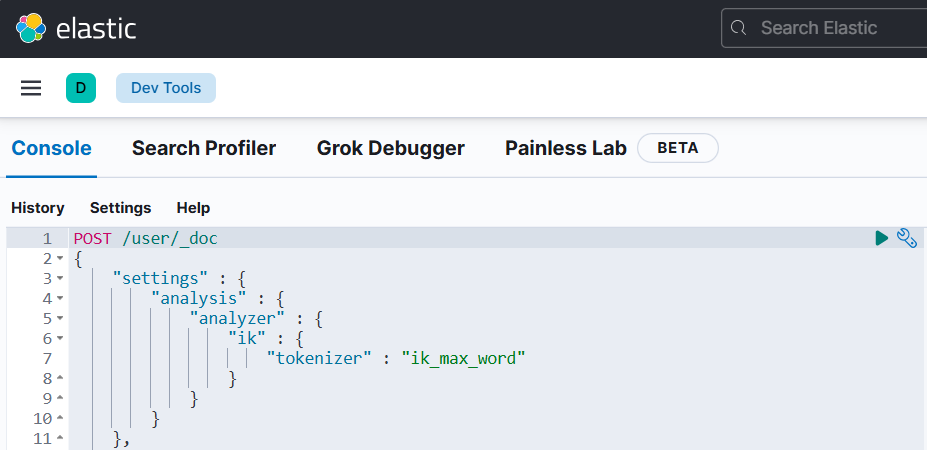
#创建索引并配置字段和映射
POST /user/_doc
{"settings" : {"analysis" : {"analyzer" : {"ik" : {"tokenizer" : "ik_max_word"}}}},"mappings":{"dynamic" : true,"properties":{"nickname" : {"type" : "text","analyzer" : "ik_max_word"},"user_id" : {"type" : "keyword","analyzer" : "standard"},"phone" : {"type" : "keyword","analyzer" : "standard"},"description" : {"type" : "text","enabled" : false},"avatar_id":{"type" : "keyword","enabled" : false}}}
}#新增数据
POST /user/_doc/_bulk
{"index":{"_id":"1"}}
{"user_id" : "USER4b862aaa-2df8654a-7eb4bb65-e3507f66","nickname" : "昵称 1","phone" : "手机号 1","description" : "签名 1","avatar_id" : "头像 1"}
{"index":{"_id":"2"}}
{"user_id" : "USER14eeeaa5-442771b9-0262e455-e4663d1d","nickname" : "昵称 2","phone" : "手机号 2","description" : "签名 2","avatar_id" : "头像 2"}
{"index":{"_id":"3"}}
{"user_id" : "USER484a6734-03a124f0-996c169d-d05c1869","nickname" : "昵称 3","phone" : "手机号 3","description" : "签名 3","avatar_id" : "头像 3"}
{"index":{"_id":"4"}}
{"user_id" : "USER186ade83-4460d4a6-8c08068f-83127b5d","nickname" : "昵称 4","phone" : "手机号 4","description" : "签名 4","avatar_id" : "头像 4"}
{"index":{"_id":"5"}}
{"user_id" : "USER6f19d074-c33891cf-23bf5a83-57189a19","nickname" : "昵称 5","phone" : "手机号 5","description" : "签名 5","avatar_id" : "头像 5"}
{"index":{"_id":"6"}}
{"user_id" : "USER97605c64-9833ebb7-d0455353-35a59195","nickname" : "昵称 6","phone" : "手机号 6","description" : "签名 6","avatar_id" : "头像 6"}
main.cc
#include <elasticlient/client.h>
#include <cpr/cpr.h>
#include <iostream>
int main()
{// 1. 构建ES客户端elasticlient::Client client({"http://127.0.0.1:9200/"});// 2. 发起搜索请求try{auto rsp = client.search("user", "_doc", "{\"query\":{\"match_all\":{}}}");std::cout << rsp.status_code << std::endl;std::cout << rsp.text << std::endl;}catch (const std::exception &e){std::cerr << "请求失败:" << e.what() << '\n';return -1;}return 0;
}makefile
main : main.ccg++ -o $@ $^ -std=c++17 -lcpr -lelasticlientES 客户端 API 二次封装
封装客户端 api 主要是因为,客户端只提供了基础的数据存储获取调用功能,无法根据我们的思想完成索引的构建,以及查询正文的构建,需要使用者自己组织好 json 进行序列化后才能作为正文进行接口的调用。而封装的目的就是简化用户的操作,将索引的 json 正文构造,以及查询搜索的正文构造操作给封装起来,使用者调用接口添加字段就行,不用关心具体的 json 数据格式。
封装内容:
- 索引构造过程的封装:索引正文构造过程,大部分正文都是固定的,唯一不同的地方是各个字段不同的名称以及是否只存储不索引这些选项,因此重点关注以下几个点即可:
- 字段类型:type : text / keyword (目前只用到这两个类型)
- 是否索引:enable : true/false
- 索引的话分词器类型: analyzer : ik_max_word / standard
- 新增文档构造过程的封装:新增文档其实在常规下都是单条新增,并非批量新增,因此直接添加字段和值就行
- 文档搜索构造过程的封装:搜索正文构造过程,我们默认使用条件搜索,我们主要关注的两个点:
- 应该遵循的条件是什么:should 中有什么
- 条件的匹配方式是什么:match 还是 term/terms,还是 wildcard
- 过滤的条件字段是什么:must_not 中有什么
- 过滤的条件字段匹配方式是什么:match 还是 wildcard,还是 term/terms
整个封装的过程其实就是对 Json::Value 对象的一个组织的过程,并无太大的难点。
#pragma once
#include <elasticlient/client.h>
#include <json/json.h>
#include <iostream>
#include <memory>
#include <sstream>
#include <cpr/cpr.h>
#include "logger.hpp"bool Serialize(const Json::Value &val, std::string &dst)
{// 先定义Json::StreamWriter 工厂类 Json::StreamWriterBuilderJson::StreamWriterBuilder swb;swb.settings_["emitUTF8"] = true;std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());// 通过Json::StreamWriter中的write接口进行序列化std::stringstream ss;int ret = sw->write(val, &ss);if (ret != 0){std::cout << "Json反序列化失败!\n";return false;}dst = ss.str();return true;
}
bool UnSerialize(const std::string &src, Json::Value &val)
{Json::CharReaderBuilder crb;crb.settings_["emitUTF8"] = true;std::unique_ptr<Json::CharReader> cr(crb.newCharReader());std::string error;bool ret = cr->parse(src.c_str(), src.c_str() + src.size(), &val, &error);if (ret == false){std::cout << "json反序列化失败: " << error << std::endl;return false;}return true;
}
class ESIndex
{
public:ESIndex(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type = "_doc") : _name(name), _type(type), _client(client){Json::Value analysis;Json::Value analyzer;Json::Value ik;Json::Value tokenizer;tokenizer["tokenizer"] = "ik_max_word";ik["ik"] = tokenizer;analyzer["analyzer"] = ik;analysis["analysis"] = analyzer;_index["settings"] = analysis;}ESIndex &append(const std::string &key, const std::string &type = "text",const std::string &analyzer = "ik_max_word", bool enabled = true){Json::Value fields;fields["type"] = type;fields["analyzer"] = analyzer;if (enabled == false)fields["enabled"] = false;_properties[key] = fields;return *this;}bool create(const std::string &index_id = "default_index_id"){Json::Value mappings;mappings["dynamic"] = true;mappings["properties"] = _properties;_index["mappings"] = mappings;std::string body;bool ret = Serialize(_index, body);if (ret == false){LOG_ERROR("索引序列化失败!");return false;}LOG_DEBUG("{}", body);try{auto rsp = _client->index(_name, _type, index_id, body);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("创建ES索引{}失败,响应状态码异常:{}", _name, rsp.status_code);return false;}}catch (const std::exception &e){LOG_ERROR("创建ES索引{}失败:{}", _name, e.what());return false;}return true;}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;Json::Value _index;Json::Value _properties;
};class ESInsert
{
public:ESInsert(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type = "_doc") : _name(name), _type(type), _client(client){}template <typename T>ESInsert &append(const std::string &key, const T &val){_item[key] = val;return *this;}bool insert(const std::string id = ""){std::string body;bool ret = Serialize(_item, body);if (ret == false){LOG_ERROR("索引序列化失败!");return false;}LOG_DEBUG("{}", body);try{auto rsp = _client->index(_name, _type, id, body);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("新增数据{}失败,响应状态码异常:{}", body, rsp.status_code);return false;}}catch (const std::exception &e){LOG_ERROR("新增数据{}失败:{}", body, e.what());return false;}return true;}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;Json::Value _item;
};class ESRemove
{
public:ESRemove(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type= "_doc"): _client(client), _name(name), _type(type){}bool remove(const std::string &id){try{auto rsp = _client->remove(_name, _type, id);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("删除数据{}失败,响应状态码异常:{}", id, rsp.status_code);return false;}}catch (const std::exception &e){LOG_ERROR("删除数据{}失败:{}", id, e.what());return false;}return true;}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;
};class ESSearch
{
public:ESSearch(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type= "_doc"): _client(client), _name(name), _type(type){}ESSearch &append_must_not_terms(const std::string &key, const std::vector<std::string> &vals){Json::Value fields;for (const auto &val : vals){fields[key].append(val);}Json::Value terms;terms["terms"] = fields;_must_not.append(terms);return *this;}ESSearch &append_must_term(const std::string &key, const std::string &val){Json::Value field;field[key] = val;Json::Value term;term["terms"] = field;_must.append(term);return *this;}ESSearch &append_must_match(const std::string &key, const std::string &val){Json::Value field;field[key] = val;Json::Value match;match["match"] = field;_must.append(match);return *this;}ESSearch &append_should_match(const std::string &key, const std::string &val){Json::Value field;field[key] = val;Json::Value match;match["match"] = field;_should.append(match);return *this;}Json::Value search(){Json::Value cond;if (_must_not.empty() == false)cond["must_not"] = _must_not;if (_must.empty() == false)cond["must"] = _must;if (_should.empty() == false)cond["should"] = _should;Json::Value query;query["bool"] = cond;Json::Value root;root["query"] = query;std::string body;bool ret = Serialize(root, body);if (ret == false){LOG_ERROR("索引序列化失败!");return Json::Value();}LOG_DEBUG("{}", body);cpr::Response rsp;try{rsp = _client->search(_name, _type, body);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("检索数据{}失败,响应状态码异常:{}", body, rsp.status_code);return Json::Value();}}catch (const std::exception &e){LOG_ERROR("删除数据{}失败:{}", body, e.what());return Json::Value();}LOG_DEBUG("检索响应正文:{}", rsp.text);Json::Value json_rsp;ret = UnSerialize(rsp.text, json_rsp);if (ret == false){LOG_ERROR("检索数据 {} 结果反序列化失败", rsp.text);return Json::Value();}return json_rsp["hits"]["hits"];}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;Json::Value _must_not;Json::Value _must;Json::Value _should;
};makefile
main : main.cc g++ -std=c++17 $^ -o $@ -lcpr -lelasticlient -lspdlog -lfmt -lgflags -ljsoncpp

深度学习中的损失函数优化技巧)
















