参考《DAX 权威指南 第二版》
文章目录
- 二、DAX简介
- 2.1 理解 DAX 计算
- 2.2 计算列和度量值
- 2.3 变量
- 2.3.1 VAR简介
- 2.3.2 VAR的特性
- 2.4 DAX 错误处理
- 2.4.1 DAX 错误类型
- 2.4.1.1 转换错误
- 2.4.1.2 算术运算错误
- 2.4.1.3 空值或 缺失值
- 2.4.2 使用IFERROR函数拦截错误
- 2.4.2.1 安全地进行除法运算
- 2.4.2.2 拦截其它错误
- 2.4.2.3 使用建议
- 2.4.4 使用ERROR函数生成错误
- 2.5 格式化
- 2.6 常见函数
- 2.6.1 聚合函数
- 2.6.2 迭代函数
- 2.6.3 逻辑函数
- 2.6.3.1 常见逻辑函数
- 2.6.3.2 SWITCH
- 2.6.3.3 计算组:参数化计算的首选
- 2.6.4 信息函数
- 2.6.5 数学与三角函数
- 2.6.6 文本函数
- 2.6.7 转换函数
- 2.6.8 日期和时间函数
- 三、表函数
- 3.1 简介
- 3.2 DAX查询
- 3.2.1 DAX 查询的关键字
- 3.2.1.1 EVALUATE(必须)
- 3.2.1.2 ORDER BY(可选)
- 3.2.1.3 START AT(可选)
- 3.2.1.4 DEFINE(可选)
- 3.2.2 DAX 查询中的参数化与应用示例
- 3.3 FILTER
- 3.3.1 基本用法
- 3.3.2 嵌套使用
- 3.3.3 性能优化
- 3.4 ALL 、 ALLEXCEPT、ALLSELECTED
- 3.4.1 ALL :清除筛选
- 3.4.2 ALLEXCEPT :清除指定列之外的筛选
- 3.4.3 ALLSELECTED 只保留外部(报表)筛选器
- 3.5 VALUES 与 DISTINCT
- 3.5.1 语法
- 3.5.2 空白行的产生
- 3.5.3 处理无效关系
- 3.6 单个值的表
- 3.6.1 使用IF...VALUES组合
- 3.6.2 使用HASONEVALUE...VALUES组合
- 3.6.3 使用SELECTEDVALUE函数
- 3.6.4 使用CONCATENATEX,连接所有表值
- 四、计算上下文
- 4.1 筛选上下文与行上下文
- 4.1.1 筛选上下文的定义与作用
- 4.1.2 行上下文
- 4.2 计算上下文的常见误区
- 4.2.1 在计算列中使用聚合函数
- 4.2.2 在度量值中使用列
- 4.3 迭代与行上下文
- 4.3.1 使用迭代函数创建行上下文
- 4.3.2 不同表上的嵌套行上下文(`RELATED` 和 `RELATEDTABLE` )
- 4.3.3 同一表上的嵌套行上下文(使用变量处理)
- 4.3.4 EARLIER
- 4.4 多表数据模型中的上下文
- 4.4.1 行上下文与关系
- 4.4.2 筛选上下文与关系
- 4.6 SUMMARIZE
- 4.6.1 SUMMARIZE语法
- 4.6.2 案例:计算所有客户购买产品时的平均年龄
- 4.6.3 匿名表与模型表
- 4.6.4 数据沿袭(Data Lineage)
二、DAX简介
2.1 理解 DAX 计算
2.2 计算列和度量值
| 特性 | 计算列 | 度量值 |
|---|---|---|
| 定义 | 通过 DAX 公式创建而非从数据源直接加载的 | 通过DAX创建,用于聚合表中的数据 |
| 计算上下文 | 依赖于当前行进行计算(行上下文),无法直接访问其他行的值。 | 查询上下文,依赖于用户选择和筛选器 |
| 存储方式 | 在数据加载时存储在模型中,占用内存空间 数据刷新时而非查询时计算,从而提高用户体验 | 在查询时才进行计算,不占用额外内存 |
| 适用场景 | 当需要将计算结果作为筛选器、行或列显示在报表中时 | 聚合计算时,如计算利润百分比、产品相对比率等 |
| 总计计算 | 逐行计算的结果直接聚合(如求和或平均),可能导致错误 | 根据聚合值动态计算,结果正确 |
| 依赖关系 | 依赖于表中的列,不能直接引用其他行的值 | 可以引用表中的列或其他度量值,依赖于上下文 |
| 使用建议 | 仅在需要逐行计算或作为报表元素时使用 | 每当你可以用计算列和度量值来表达同一个计算时,优先使用度量值 |
创建复杂计算列时,虽然计算时间是在数据处理阶段(而非查询阶段),能够提升用户体验,但计算列会占用宝贵的内存空间。因此,将复杂公式拆分为多个中间列的做法虽然有助于开发,却会导致内存浪费,不是一个好的习惯。 每当你可以用计算列和度量值来表达同一个计算时,优先使用度量值(不占内存)。计算列的使用应该严格限制在少数需要它们的情况
强烈建议使用 := 来创建度量值公式,使用 = 创建计算列或计算表公式,以便进行更好的区分。
初学者常常问的问题是:什么时候需要创建计算列?只有一个正确答案,那就是你需要用手把某列从某表中拖出来作图表而该表列却不存在时。这句话不是让你现在理解的,而是让你记录并在未来不断体会的。
计算列是在行级别上逐行计算的,适用于需要对每一行进行简单计算的场景,比如,您可以使用以下公式创建计算列来计算销售额的毛利率:
Sales[SalesAmount] = Sales[Quantity] * Sales[Net Price]Sales[TotalCost] = Sales[Quantity] * Sales[Unit Cost]Sales[GrossMargin] = Sales[SalesAmount] – Sales[TotalCost]Sales[GrossMarginPct] = Sales[GrossMargin] / Sales[SalesAmount]这种方式在行级别上计算是正确的,但在总计级别上会出错:

这里毛利率的总计结果是每行毛利率的简单相加(46.34%+51.58%+…),这个逻辑显然是错的。GrossMarginPct (毛利率) 的正确实现是写一个度量值:
GrossMarginPct := SUM ( Sales[GrossMargin] ) / SUM (Sales[SalesAmount] )

计算列的聚合结果是逐行计算的总和,而度量值的聚合结果是基于聚合值的比率计算。这就是前面说的,如果需要进行聚合计算,而不是逐行计算,则必须创建度量值。
2.3 变量
2.3.1 VAR简介
使用 VAR 关键字可以定义变量,避免在表达式中重复相同的计算,提高代码的可读性和可维护性。定义一个变量之后,需要提供 RETURN 部分来定义表达式的结果值。例如上一节毛利率的计算公式可改写为:
VAR TotalSales = SUM ( Sales[SalesAmount] )
VAR TotalCosts = SUM ( Sales[TotalProductCost] )
VAR GrossMargin = TotalSales - TotalCosts
RETURN
GrossMargin / TotalSales
我们强烈建议尽可能使用变量,因为它们使代码更易于阅读。例如下述代码,遍历Sales表,仅计算 Quantity 大于 1 的行的销售额:
Sales Amount Multiple Items :=
SUMX (FILTER (Sales,Sales[Quantity] > 1),Sales[Quantity] * Sales[Net Price]
)
我们使用变量存储表,将公式进行改写,使其更易于理解:
Sales Amount Multiple Items :=
VARMultipleItemSales = FILTER ( Sales, Sales[Quantity] > 1 )
RETURNSUMX (MultipleItemSales,Sales[Quantity] * Sales[Unit Price])
2.3.2 VAR的特性
- 作用域:变量仅在定义它们的表达式内部有效,不能在表达式外部使用,不存在全局变量。
- 上下文:变量在定义时捕获计算上下文,而不是在使用时。这意味着一旦变量的值被计算出来,它在当前上下文中就会保持不变,不会因为上下文的变化而重新计算。
- 延迟计算:变量只有在被使用时才会被计算,如果未被使用,则不会计算。如果多次使用同一个变量,计算只会发生一次,后续使用会直接读取已计算的值。
下面举一个使用VAR的常见误区进行具体的说明。我们可与使用常规方式定义同比增长率(与去年相比):
[Sales] := SUM(销售表[销售额])
[Saleslastyear] := CALCULATE([Sales], SAMEPERIODLASTYEAR(日期表[日期]))
[YoY%] := DIVIDE([Sales] - [Saleslastyear], [Saleslastyear])
使用 VAR 定义变量时,可以在一个度量值中完成所有计算:
[YoY% 1] :=
VAR Sales = SUM('订单'[销售额])
VAR Saleslastyear =CALCULATE(SUM('订单'[销售额]),SAMEPERIODLASTYEAR('日期表'[日期]))
RETURN
DIVIDE(Sales - Saleslastyear, Saleslastyear)
如果CALCULATE函数的第一个参数使用Sales变量,则会计算错误:
[YoY% 2] :=
VAR Sales = SUM('订单'[销售额])
VAR Saleslastyear =CALCULATE(Sales,SAMEPERIODLASTYEAR('日期表'[日期]))
RETURN
DIVIDE(Sales - Saleslastyear, Saleslastyear)

Sales 是一个变量,它的值在定义时不会立即计算,而是等到整个表达式需要使用它时才会计算。计算时,是根据其定义的上下文进行计算,并在之后调用时保持不变,即使后面调用时使用CALCULATE函数修改上下文,也不会因为上下文的变化而重新计算。所以[YoY% 2]中,Saleslastyear = Sales,最终得到的结果就是0。
2.4 DAX 错误处理
现在您已经了解了语法的一些基本知识,接下来应该学习如何优雅地处理错误(无效的计算)。
2.4.1 DAX 错误类型
2.4.1.1 转换错误
DAX 会在运算需要时自动尝试将字符串和数字进行转换,比如以下DAX表达式都是有效的:
"10" + 32 = 42"10" & 32 = "1032"10 & 32 = "1032"DATE (2010,3,25) = 3/25/2010DATE (2010,3,25) + 14 = 4/8/2010DATE (2010,3,25) & 14 = "3/25/201014"
但如果无法将某些内容转换为适合运算的类型,就会发生转换错误。例如:
"1 + 1" + 0 // 无法将文本类型的值"1 + 1"转换为数字类型DATEVALUE ("25/14/2010") // 无效日期格式,无法转换
解决办法是在 DAX 表达式中添加错误检测逻辑,以拦截错误条件并返回有意义的结果。
2.4.1.2 算术运算错误
除零错误:当你把一个数除以零时,DAX 会返回一个无穷大的特殊值 Infinity。此外,在 0 除以 0 或无穷大除以无穷大的特殊情况下,DAX 返回特殊的 NaN(而不是数字值) :

其它算术错误(如负数的平方根)会导致计算错误。可以使用 ISERROR 函数检查表达式是否导致错误(下文介绍)。
在 Power BI 中,特殊值如
NaN(“非数字”)会正常显示,但在 Excel 数据透视表中可能会显示为错误。此外,错误检测函数也会将这些特殊值识别为错误。
2.4.1.3 空值或 缺失值
空值的定义:DAX中使用空值(BLANK)来表示缺失值、空白值或空单元格。空值不是一个真正的值,而是一种特殊的状态,用于识别这些条件。BLANK 本身不是一个错误,它只是显示为空白结果。可以通过调用BLANK()函数来显式地返回一个空值:
= BLANK ()
-
空值的运算规则:BLANK()在加减法中可视为0,但在乘除法中会传播BLANK()
BLANK () + BLANK () = BLANK ()10 * BLANK () = BLANK ()BLANK () / 3 = BLANK ()BLANK () / BLANK () = BLANK ()BLANK () − 10 = −1018 + BLANK () = 184 / BLANK () = Infinity0 / BLANK () = NaN -
空值的逻辑规则:个人感觉BLANK可视为0,而0在很多语言中可视为FALSE,这样理解便于看懂下面的判断结果:
BLANK () || BLANK () = FALSEBLANK () && BLANK () = FALSE( BLANK () = BLANK () ) = TRUE( BLANK () = TRUE ) = FALSE( BLANK () = FALSE ) = TRUEFALSE || BLANK () = FALSEFALSE && BLANK () = FALSETRUE || BLANK () = TRUETRUE && BLANK () = FALSE -
使用ISBLANK函数检查空值:BLANK与0或空字符串""的比较会返回TRUE,因此无法通过简单的相等运算符来区分空值,只能使用ISBLANK函数进行区分。
BLANK () = 0 // 隐式转换规则,始终返回 TRUEBLANK () = "" // 隐式转换规则,始终返回 TRUEISBLANK ( BLANK() ) = TRUEISBLANK ( 0 ) = FALSEISBLANK ( "" ) = FALSE
比如下面的表达式计算销售交易的总折扣,如果折扣为 0,则单元格为空:
=IF (Sales[DiscountPerc] = 0,-- 确认是否有折扣BLANK (),-- 如果不存在折扣,返回空值Sales[DiscountPerc] * Sales[Amount]
)
因此,如果 Sales[DiscountPerc] 或 Sales[Clerk] 为空,则即使分别针对 0 和空字符串做测试,以下条件也会返回 TRUE:
Sales[DiscountPerc] = 0 // 如果 PercSales[DiscountPerc] 为 BLANK 或 0,则返回 TRUESales[Clerk] = " " // 如果 Sales[Clerk] 是 BLANK 或 "",则返回 TRUE
在这种情况下,可以使用 ISBLANK 函数检查值是否为空值:
ISBLANK ( Sales[DiscountPerc] ) //仅当 Sales[DiscountPerc]为空值时才返回 TRUEISBLANK ( Sales[Clerk] ) //仅当 Sales[Clerk] 是空值时才返回 TRUE
- 与其他工具中空值的对比:
- Excel中的空值:在Excel中,空值在求和或乘法运算中被视为
0,但在除法或逻辑表达式中可能会导致错误。 - SQL中的NULL:在SQL中,
NULL在表达式中通常会导致整个表达式计算为NULL,而DAX中的空值并不总是导致空白结果。 - DirectQuery模式:在使用DirectQuery模式时,部分计算在SQL中执行,部分在DAX中执行。由于DAX和SQL对空值的语义不同,可能会导致意外的行为。因此,在使用DirectQuery时,需要特别注意空值的处理。
- Excel中的空值:在Excel中,空值在求和或乘法运算中被视为
2.4.2 使用IFERROR函数拦截错误
IFERROR 是 DAX 中用于错误处理的常用函数,它能够优雅地捕获和处理表达式可能产生的错误,使报表更加健壮和用户友好,其基本语法为:
IFERROR(value, value_if_error)
- value:DAX表达式,计算成功直接返回表达式的结果;
- value_if_error:当表达式出错时返回的替代值
2.4.2.1 安全地进行除法运算
// 传统方法需要嵌套IF检查分母
= IF([Denominator] <> 0,[Numerator] / [Denominator],BLANK()
)// 使用IFERROR更简洁
= IFERROR([Numerator] / [Denominator],BLANK()
)
第一种方式,IF函数需要检查除数是否为零,增加额外计算;使用IFERROR更简洁,但IFERROR 会先完整计算表达式,再判断是否出错。对于安全地进行除法运算,更推荐使用DIVIDE函数 ,其语法为:
DIVIDE(<numerator>, <denominator> [,<alternateresult>])
<numerator>, <denominator>分别是分子和分母,<alternateresult>是可选的备用结果。DIVIDE 函数可自动处理除数为零的情况。如果未传入备用结果,分母为零或 BLANK,则函数将返回 BLANK;如果传入备用结果,则此时返回备用结果。
以下度量值表达式生成安全的除法运算,但它涉及使用四个 DAX 函数:
Profit Margin =
IF(OR(ISBLANK([Sales]),[Sales] == 0),BLANK(),[Profit] / [Sales]
)
直接使用DIVIDE函数可实现相同的结果,且更高效、更优雅:
Profit Margin =
DIVIDE([Profit], [Sales])
2.4.2.2 拦截其它错误
-
处理类型转换:
如果Sales[Quantity]或Sales[Price]是无法转换为数字的字符串,或者它们的乘法运算导致错误(例如,其中一个值为BLANK()),则返回BLANK()。= IFERROR(Sales[Quantity] * Sales[Price], BLANK()) -
计算错误
= IFERROR(SQRT(Test[Omega]), "无效的平方根计算") -
嵌套使用:IFERROR 可以嵌套使用来处理多步计算中可能出现的错误:
= IFERROR(SQRT(IFERROR(VALUE([TextValue]),0 // 如果文本转换失败使用0作为默认值)),"无效的平方根计算" // 如果SQRT失败显示此消息 )
2.4.2.3 使用建议
- 性能影响:
IFERROR会先完整计算表达式,再判断是否出错。对于性能敏感的计算,预先检查条件,比如使用IF进行检查剔除不需要的计算,可能更高效。在大型数据集上,过度使用IFERROR可能影响性能。 - 隐藏潜在问题:虽然IFERROR可以防止错误显示,但它也可能隐藏数据中的潜在问题。因此,在使用IFERROR时,需要确保默认值的使用不会掩盖数据质量问题。
2.4.4 使用ERROR函数生成错误
不是所有错误都需要捕获,有时生成一个明确的错误信息比返回一个默认值更有意义,更有助于发现数据问题。ERROR函数用于生成一个明确的错误信息,以提示用户数据或计算中存在问题,其语法为:
ERROR(error_message)
error_message:要显示的错误信息,通常是一个字符串。
例如在一个计算场景中,需要计算开尔文温度的平方根。因为开尔文温度的最低极限是0(绝对零度),不可能是负数。在这种情况下,如果我们使用IFERROR函数来处理可能的错误,这会导致即使温度是负数,公式也不会报错。这样做虽然避免了错误的显示,但同时也隐藏了数据中的问题。
= IFERROR(SQRT(Test[Temperature]), 0)
正确做法是使用IF函数来检查温度值是否合理(即是否大于或等于0):
= IF(Test[Temperature] >= 0,SQRT(Test[Temperature]),ERROR("温度不能是负数,计算终止")
)
2.5 格式化
DAX是一种函数语言:函数语言是指一种编程范式,其中程序的构建主要依赖于函数的组合和调用。 DAX就是一种函数语言,每个表达式都可以被视为一个函数的调用,例如,SUM(Sales[Amount])是一个函数调用,IF(Condition, TrueValue, FalseValue)也是一个函数调用。
由于DAX是基于函数的,复杂的逻辑可以通过嵌套多个函数来实现,这种嵌套结构使得DAX表达式可以非常强大,但也可能导致表达式变得很长。例如:
IF(CALCULATE(NOT ISEMPTY(Balances), ALLEXCEPT (Balances, BalanceDate)),SUMX (ALL(Balances[Account]),CALCULATE(SUM(Balances[Balance]),LASTNONBLANK(DATESBETWEEN(BalanceDate[Date],BLANK(),MAX(BalanceDate[Date])),CALCULATE(COUNTROWS(Balances))))),BLANK())
以这种格式来理解这个公式的计算内容,几乎是不可能的,不知道哪个是最外层的函数, 也不知道 DAX 如何评估不同的参数来创建完整的执行流程。而通过格式化,我们可以更清楚的理解整个表达式的结构:
IF (CALCULATE (NOT ISEMPTY ( Balances ),ALLEXCEPT (Balances,BalanceDate)),SUMX (ALL ( Balances[Account] ),CALCULATE (SUM ( Balances[Balance] ),LASTNONBLANK (DATESBETWEEN (BalanceDate[Date],BLANK (),MAX ( BalanceDate[Date] )),CALCULATE (COUNTROWS ( Balances ))))),BLANK ()
)
在这个例子中:
- IF是外层函数,有三个参数;
- CALCULATE和SUMX是嵌套在IF中的第二层函数;
- CALCULATE中又嵌套了NOT ISEMPTY、ALLEXCEPT等函数。
- SUMX中嵌套了ALL、CALCULATE、LASTNONBLANK、DATESBETWEEN等函数。
使用变量(VAR)来进一步优化代码的可读性:
IF (CALCULATE (NOT ISEMPTY ( Balances ),ALLEXCEPT (Balances,BalanceDate)),SUMX (ALL ( Balances[Account] ),VAR PreviousDates =DATESBETWEEN (BalanceDate[Date],BLANK (),MAX ( BalanceDate[Date] ))VAR LastDateWithBalance =LASTNONBLANK (PreviousDates,CALCULATE (COUNTROWS ( Balances )))RETURNCALCULATE (SUM ( Balances[Balance] ),LastDateWithBalance)),BLANK ()
)
一些常用的DAX代码格式化规则如下:
- 函数名称:始终使用空格将函数名称(如IF,SUMX和CALCULATE)与参数分开,并使用大写字母。
- 列引用与度量值引用:在代码中引用列时,始终加上表名,表名和左方括号之间不加空格;引用度量值时,不要加上表名。
- 区分计算列和度量值:在定义计算列时使用
=,在定义度量值时使用:=。 - 逗号:在逗号后面加空格,但不在逗号前面加空格。
- 单行公式:如果公式适合单行,则不应用其他规则。
- 多行公式:将函数名称和左括号放在一行上,每个参数占一行,缩进四个空格,最后一个参数后不加逗号,右括号与函数对齐。
CalcCol = SUM ( Sales[SalesAmount] ) // 这是一个计算列
Store[CalcCol] = SUM ( Sales[SalesAmount] ) // 这是一个在 表 Store 中的计算列
CalcMsr := SUM ( Sales[SalesAmount] ) // 这是一个度量值
格式化代码是一个耗时的操作,有一个专门用于格式化 DAX 代码的网站DAXFormatter.com,可自动进行DAX代码格式化。另外,在编辑栏中书写DAX代码时:
- 字体大小:在Power BI、Excel或Visual Studio中,可以通过按住Ctrl键并滚动鼠标滚轮来调整字体大小,以便更清晰地查看代码。
- 换行:按Shift+Enter可以在公式中添加新行。
- 编辑器:如果文本框不适合编辑,可以将代码复制到其他编辑器(如记事本或DAXStudio)中进行编辑,然后再复制回去。
- 智能提示:Power BI自带的DAX公式编辑器已经非常强大,提供了智能提示功能。一个重要的技巧请记住:你能用的,它都提示给你;没提示给你的,都不能用。用,则会报错语法错误。
2.6 常见函数
2.6.1 聚合函数
对表列进行聚合并返回单个值的函数称为聚合函数。聚合是一种思想,将大量数据快速聚合到少量数据,形成价值密度更高的信息。DAX 在执行聚合时不考虑空单元格(准确讲是空值),这与Excel的处理方式不同。
聚合函数大多只对数值或日期进行操作,只有 MIN 和 MAX 可以对文本值进行操作。另外,除了接受表列,MIN 和 MAX还可以接受两个DAX 表达式作为参数,并返回其中的最小值或最大值,这种方式可以简化代码,避免复杂的IF语句,提高可读性和效率。
MAX函数语法:
MAX(<column>)或者MAX(<expression1>, <expression2>)
数据处理方式 :Excel:以单元格为单位处理数据,每个单元格可以包含不同类型的数据(数字、文本、布尔值等)。DAX:以列(字段)为单位处理数据,每列都有明确的数据类型(如数字、文本等),并且列中的所有值必须符合该数据类型。在 Excel 中,函数会逐个单元格计算,而 DAX 中的函数会根据列的数据类型进行整体计算。
- 基础聚合函数:如
SUM,AVERAGE,MIN,MAX,主要用于数字列。 - 扩展聚合函数:DAX 为继承自 Excel 的聚合函数提供了另一种语法,可以对包含数值和非数值的列进行计算。这些函数都带后缀“A”,如 AVERAGEA、
COUNTA、MINA和MAXA。在这些函数中,TRUE和FALSE 分别被计算为 1和0,而文本列(包括空字符串)始终被视为 0。
| 事务 ID | 值 | 结果 |
|---|---|---|
| 0000123 | 1 | 计为 1 |
| 0000124 | 20 | 计为 20 |
| 0000125 | n/a | 计为 0 |
| 0000126 | 计为 0 | |
| 0000126 | TRUE | 计为 1 |
| DAX 的计数函数 | 参数 | 返回结果 |
|---|---|---|
| COUNT | 数字列 | 返回非空值的数量 |
| COUNTA | 任何类型的列 | 返回非空值的数量 |
| COUNTBLANK | 任何列 | 返回空单元格的数量(包括空白和空字符串) |
| COUNTROWS | 表 | 返回表中的行数 |
| DISTINCTCOUNT | 任何列 | 返回列中不同值的数量(包括空白值) |
| DISTINCTCOUNTNOBLANK | 任何列 | 返回列中不同值的数量(不包括空白值) |
- DISTINCTCOUNT:是 2012 版 DAX 引入的函数,用于计算列中不同值的数量,包括空白值。在早期版本中,可通过
COUNTROWS(DISTINCT(table[column]))来实现相同功能。- DISTINCTCOUNTNOBLANK:是 2019 年引入的函数,用于计算列中不同值的数量,但不包括空白值。它简化了 SQL 中的 COUNT DISTINCT 操作,避免了在 DAX 中编写复杂的表达式。
2.6.2 迭代函数
聚合函数都是对表列进行操作,如果要聚合整个表或表中不同的列,或者需要减少计算列的使用是,可以使用迭代函数(迭代器)。迭代函数通常接受至少两个参数:第一个是它们扫描的表,第二个是表中每一行的计算的表达式。迭代函数内部封装了迭代逻辑,用于逐行计算表达式。比如:
SUM ( Sales[Quantity] )
在内部,SUM函数会被转换为:
SUMX ( Sales, Sales[Quantity] )
所以说,聚合函数只是对应迭代器的语法糖版本。使用迭代函数并不会比使用标准聚合函数慢。实际上,迭代函数在内部实现了优化,性能上没有显著差异。
| 特性 | 聚合函数 | 迭代函数 |
|---|---|---|
| 定义 | 对单个列的值进行聚合操作,返回单个值 | 对表中的每一行进行计算,不一定都是聚合效果 |
| 典型函数 | SUM、AVERAGE、MIN、MAX、STDEV | SUMX、AVERAGEX、MINX、MAXX、FILTER、ADDCOLUMNS、GENERATE |
| 参数 | 通常只需要一个参数(列引用) | 至少两个参数:表和每行的计算表达式 |
| 计算方式 | 直接对列进行聚合,不需要逐行计算 | 需要逐行计算表达式,然后聚合结果 |
| 适用场景 | 简单的单列聚合操作 | 复杂的多列计算或需要减少计算列的情况 |
2.6.3 逻辑函数
2.6.3.1 常见逻辑函数
逻辑函数用于在 DAX 表达式中构建逻辑条件,实现不同的计算逻辑。常见的逻辑函数包括:
| 函数名称 | 描述 | 函数名称 | 描述 | 函数名称 | 描述 | 函数名称 | 描述 |
|---|---|---|---|---|---|---|---|
| AND | 逻辑与 | FALSE | 返回逻辑值 FALSE | IF | 条件判断 | IFERROR | 错误处理 |
| NOT | 逻辑非 | TRUE | 返回逻辑值 TRUE | OR | 逻辑或 | SWITCH | 多条件判断 |
例如在之前的章节中,我们使用IFERROR 函数处理表达式中的错误:
Sales[Amount] = IFERROR(Sales[Quantity] * Sales[Price], BLANK())
2.6.3.2 SWITCH
SWITCH 特别适合处理多条件判断,比使用嵌套 IF 函数更加简洁:
'Product'[SizeDesc] =
IF ('Product'[Size] = "S","Small",IF ('Product'[Size] = "M","Medium",IF ('Product'[Size] = "L","Large",IF ('Product'[Size] = "XL","Extra Large","Other")))
)
使用 SWITCH 可以实现同样的功能,且更容易阅读,不过此性能上没有显著差异,因为DAX 内部会将其转换为一组嵌套的 IF 函数。
'Product'[SizeDesc] =
SWITCH ('Product'[Size],"S", "Small","M", "Medium","L", "Large","XL", "Extra Large","Other"
)
SWITCH 可以结合 TRUE() 用于测试多个条件。例如:
SWITCH (TRUE (),Product[Size] = "XL" && Product[Color] = "Red", "Red and XL",Product[Size] = "XL" && Product[Color] = "Blue", "Blue and XL",Product[Size] = "L" && Product[Color] = "Green", "Green and L"
)
2.6.3.3 计算组:参数化计算的首选
SWITCH 通常用于检查参数的值和测量结果。例如,可以创建一个包含 YTD、MTD 和 QTD 的参数表,并让用户从三个可用的聚合中选择在度量中使用哪个聚合。2019年之后由于计算组功能的引进,我们不再需要用到 SWITCH,计算组是参数化计算的首选方法。
2.6.4 信息函数
信息函数用于分析表达式的类型,并返回布尔值,这些函数可以在任何逻辑表达式中使用。常见的信息函数包括:
| 函数名称 | 描述 | 函数名称 | 描述 | 函数名称 | 描述 |
|---|---|---|---|---|---|
| ISBLANK | 检查值是否为空 | ISERROR | 检查表达式是否返回错误 | ISLOGICAL | 检查值是否为逻辑值(TRUE 或 FALSE) |
| ISNONTEXT | 检查值是否为非文本类型 | ISNUMBER | 检查值是否为数字 | ISTEXT | 检查值是否为文本 |
//RETURNS: Is Text
= IF(ISTEXT("text"), "Is Text", "Is Non-Text")//RETURNS: Is Text
= IF(ISTEXT(""), "Is Text", "Is Non-Text")//RETURNS: Is Non-Text
= IF(ISTEXT(1), "Is Text", "Is Non-Text")//RETURNS: Is Non-Text
= IF(ISTEXT(BLANK()), "Is Text", "Is Non-Text")
//RETURNS: Is number
= IF(ISNUMBER(0), "Is number", "Is Not number")//RETURNS: Is number
= IF(ISNUMBER(3.1E-1),"Is number", "Is Not number")//RETURNS: Is Not number
= IF(ISNUMBER("123"), "Is number", "Is Not number")
信息函数的限制:当使用列(而不是单个值)作为参数时,ISNUMBER、ISTEXT 和 ISNONTEXT 函数会根据列的数据类型返回固定值(TRUE 或 FALSE),而不是逐行检查每个单元格的实际内容。这使得这些函数在 DAX 中的实用性有限。例如,如果列是文本类型,ISNUMBER 总是返回 FALSE,即使某些单元格中的文本可以转换为数字。
如果需要检查文本列中的值是否可以转换为数字,使用 ISNUMBER是无效的,例如以下表达式结果始终是 FALSE:
// 文本列,始终返回FALSE
Sales[IsPriceCorrect] = ISNUMBER ( Sales[Price] )
正确的方法是尝试将文本值转换为数字,并捕获转换过程中可能出现的错误,例如:
Sales[IsPriceCorrect] = NOT ISERROR(VALUE(Sales[Price]))
- 如果 VALUE(Sales[Price]) 转换成功,
ISERROR返回 FALSE,因此NOT ISERROR返回 TRUE。 - 如果转换失败(例如,文本值为 “N/A”),
ISERROR返回 TRUE,因此NOT ISERROR返回 FALSE。
2.6.5 数学与三角函数
| 函数 | 说明 | 函数 | 说明 |
|---|---|---|---|
| ABS | 返回数字的绝对值 | CEILING | 向上舍入数字到最接近的整数或指定倍数 |
| CONVERT | 将一种数据类型的表达式转换为另一种数据类型 | CURRENCY | 将结果转为为货币数据类型 |
| DIVIDE | 除法 | EVEN | 向上舍入到最接近的偶数整数 |
| EXP | 返回 e 的给定次幂 | FACT | 返回数字的阶乘 |
| FLOOR | 向下舍入到最接近的指定倍数 | GCD | 返回多个整数的最大公约数 |
| INT | 将数字向下舍入到最接近的整数。 | ISO.CEILING | 向上舍入到最接近的整数或指定倍数 |
| LCM | 返回多个整数的最小公倍数 | MOD | 返回除法结果的余数,始终与除数具有相同的符号。 |
| MROUND | 舍入到指定倍数 | ODD | 向上舍入到最接近的奇数整数 |
| PI | 返回 Pi 的值,3.14159265358979,精确到 15 位 | QUOTIENT | 返回除法的整数部分 |
| RAND | 返回 0 到 1 之间的随机数 | RANDBETWEEN | 返回指定范围内的随机数 |
| ROUND | 舍入到指定的小数位数 | ROUNDDOWN | 向下舍入到指定的小数位数 |
| ROUNDUP | 向上舍入到指定的小数位数 | SIGN | 确定列中数字、计算结果或值的符号 |
| SQRT | 返回数字的平方根。 | TRUNC | 截断数字的小数部分,只保留整数 |
以下是舍入函数的测试结果:
FLOOR = FLOOR ( Tests[Value], 0.01 )TRUNC = TRUNC ( Tests[Value], 2 )ROUNDDOWN = ROUNDDOWN ( Tests[Value], 2 )MROUND = MROUND ( Tests[Value], 0.01 )ROUND = ROUND ( Tests[Value], 2 )CEILING = CEILING ( Tests[Value], 0.01 )ISO.CEILING = ISO.CEILING ( Tests[Value], 0.01 )ROUNDUP = ROUNDUP ( Tests[Value], 2 )INT = INT ( Tests[Value] )FIXED = FIXED ( Tests[Value], 2, TRUE )

除了可以指定要舍入的位数外,FLOOR、TRUNC 和 ROUNDDOWN 是相似的;CEILING 和 ROUNDUP 结果也是相似的; MROUND 和 ROUND 函数结果有一点差异。
- 基本三角函数:如
COS、SIN、TAN等,以及它们的双曲函数和反函数。 - 角度转换:如
DEGREES和RADIANS,用于角度和弧度之间的转换。
2.6.6 文本函数
| 函数 | 说明 | 函数 | 说明 |
|---|---|---|---|
| COMBINEVALUES | 将多个文本字符串合并为一个文本字符串 | CONCATENATE | 将两个文本字符串连接成一个文本字符串 |
| CONCATENATEX | 对表中的每一行计算表达式,并将结果连接成一个文本字符串 | EXACT | 比较两个文本字符串是否完全相同(返回布尔值),区分大小写。 |
| FIND | 返一个文本字符串在另一个一个文本字符串中的起始位置 | FIXED | 将数字舍入到指定的小数位数,并以文本形式返回 |
| FORMAT | 根据指定的格式将值转换为文本。 | LEFT | 从文本字符串的开头返回指定数量的字符 |
| LEN | 返回文本字符串的长度(总字符数) | LOWER 、 UPPER | 将文本字符串中的所有字母转换为小写/大写 |
| MID | 从文本字符串的中间位置返回指定数量的字符 | REPLACE | 替换文本字符串中指定位置的字符 |
| REPT | 重复给定次数的文本。 | RIGHT | 从文本字符串的末尾返回指定数量的字符 |
| SEARCH | 返回特定字符或文本在文本字符串中的位置。 | SUBSTITUTE | 将文本字符串中的某些文本替换为其他文本 |
| TRIM | 删除文本中的多余空格,仅保留单词间的单个空格 | VALUE | 将表示数字的文本字符串转换为数字 |
下图展示了如何从包含姓名的字符串中提取名字和姓氏,这些姓名字符串中可能包含一个或两个逗号,以及可能的Mr。

People[Comma1] =IFERROR ( FIND ( ",", People[Name] ), BLANK () )People[Comma2] =IFERROR ( FIND ( " ,", People[Name], People[Comma1] + 1 ), BLANK () )People[SimpleConversion] =
MID ( People[Name], People[Comma2] + 1, LEN ( People[Name] ) ) & " "& LEFT ( People[Name], People[Comma1] - 1 )People[FirstLastName] =
TRIM (MID (People[Name],IF ( ISNUMBER ( People[Comma2] ), People[Comma2], People[Comma1] ) + 1,LEN ( People[Name] ))
)& IF (ISNUMBER ( People[Comma1] )," "& LEFT ( People[Name], People[Comma1] - 1 ),"")
Comma1,Comma2列:分别计算第一个和第二个逗号的位置;SimpleConversion列:使用 MID 和 LEFT 函数结合逗号位置来提取姓氏和名字。这个公式在字符串中逗号少于两个时可能会返回不准确的值,如果没有逗号,则会引发错误;FirstLastName列:通过 TRIM 和 MID 函数结合 IF 函数来处理不同的情况(首先检查 Comma2 是否为数字,即是否存在第二个逗号),确保即使在缺少逗号的情况下也能正确提取姓名。
2.6.7 转换函数
| 函数名称 | 说明 | 示例 |
|---|---|---|
| CURRENCY | 将表达式转换为货币类型 | CURRENCY(1234.56) |
| INT | 将表达式转换为整数 | INT(1234.56) => 1234 |
| DATE | 返回指定年、月、日的日期值 | DATE(2019, 1, 12) => 2019-01-12 |
| TIME | 返回指定小时、分钟、秒的时间值 | TIME(12, 0, 0) => 12:00:00 |
| VALUE | 将字符串转换为数字格式 | VALUE("1234.56") => 1234.56 |
| FORMAT | 将数值转换为文本字符串,可指定格式 | FORMAT(DATE(2019, 1, 12), "yyyy mmm dd") => "2019 Jan 12" |
| DATEVALUE | 将字符串转换为 DateTime 值,支持不同日期格式 | DATEVALUE("28/02/2018") => 2018-02-28 |
创建一个计算列,使用减法来计算两个日期列的差值,结果也是日期,可用INT函数将其转为数字:
Sales[DaysToDeliver] = INT ( Sales[Delivery Date] - Sales[Order Date] )

2.6.8 日期和时间函数
| 函数名称 | 说明 | 示例 | 返回值 |
|---|---|---|---|
| CALENDAR | 返回包含连续日期集的表 | CALENDAR(DATE(2024,1,1),DATE(2024,12,31)) | 表:Date |
| CALENDARAUTO | 返回包含连续日期集的表,自动处理周末 | CALENDARAUTO(DATE(2024,1,1),DATE(2024,12,31)) | 表:Date |
| DATE | 返回指定年月日的日期 | DATE(2024, 6, 11) | 2024-06-11 |
| DATEDIFF | 返回两个日期之间的天数差异 | DATEDIFF(DATE(2024,1,1), DATE(2024,6,11), DAY) | 162 |
| DATEVALUE | 将文本形式的日期转换为日期类型 | DATEVALUE(2024-06-11) | 2024-06-11 |
| DAY | 返回日期中的天数 | DAY(DATE(2024, 6, 11)) | 11 |
| EDATE | 返回开始日期前或后的指定月份数的日期 | EDATE(DATE(2024, 6, 11), 1) | 2024-07-11 |
| EOMONTH | 返回月份的最后一天或前/后的月份的最后一天 | EOMONTH(DATE(2024, 6, 11), 0) | 2024-06-30 |
| HOUR | 返回时间中的小时数 | HOUR(TIME(12, 30, 45)) | 12 |
| MINUTE | 返回时间中的分钟数 | MINUTE(TIME(12, 30, 45)) | 30 |
| MONTH | 返回日期中的月份 | MONTH(DATE(2024, 6, 11)) | 6 |
| NETWORKDAYS | 返回两个日期之间的工作日数 | NETWORKDAYS(DATE(2024,1,1), DATE(2024,1,31)) | 22 |
| NOW | 返回当前日期和时间 | NOW() | 2024-06-11 12:00:00 |
| QUARTER | 返回日期所在的季度 | QUARTER(DATE(2024, 6, 11)) | 2 |
| SECOND | 返回时间中的秒数 | SECOND(TIME(12, 30, 45)) | 45 |
| TIME | 将小时、分钟和秒转换为时间 | TIME(12, 30, 45) | 12:30:45 |
| TIMEVALUE | 将文本格式的时间转换为时间类型 | TIMEVALUE(12:30:45) | 12:30:45 |
| TODAY | 返回当前日期 | TODAY() | 2024-06-11 |
| UTCNOW | 返回当前UTC日期和时间 | UTCNOW() | 2024-06-11 12:00:00 UTC |
| UTCTODAY | 返回当前UTC日期 | UTCTODAY() | 2024-06-11 UTC |
| WEEKDAY | 返回日期的星期几 | WEEKDAY(DATE(2024, 6, 11)) | 3 |
| WEEKNUM | 返回日期所在的周数 | WEEKNUM(DATE(2024, 6, 11)) | 24 |
| YEAR | 返回日期的年份 | YEAR(DATE(2024, 6, 11)) | 2024 |
| YEARFRAC | 计算两个日期之间的年份分数 | YEARFRAC(DATE(2024,1,1), DATE(2024,6,11)) | 0.4952 |
三、表函数
3.1 简介
表函数:返回表而非标量的函数称为表函数,可代替表作为函数的参数进行传参。比如我们可以遍历 sales 表进行迭代计算:
Sales Amount := SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
我们可以使用表函数生成的表代替SUMX中的第一个参数,进行更更复杂的计算:
Sales Amount Multiple Items :=
VARMultipleItemSales = FILTER ( Sales, Sales[Quantity] > 1 )
RETURNSUMX (MultipleItemSales,Sales[Quantity] * Sales[Unit Price])
表函数嵌套:DAX函数经常嵌套使用,先计算最里面的函数,然后逐层递进到最外层的函数。下式通过 RELATEDTABLE 获取与当前产品相关的销售记录,然后使用 FILTER 筛选出销售数量大于1的记录,最后使用 SUMX 对这些记录的销售额进行求和。
'Product'[Product Sales Amount Multiple Items] =
SUMX (FILTER (RELATEDTABLE ( Sales ),Sales[Quantity] > 1),Sales[Quantity] * Sales[Unit Price]
)
RELATEDTABLE 函数用于获取与当前产品相关的所有销售记录。它返回一个表,其中包含销售表中与当前产品相关联的所有行。
计算表:表函数还可以用来创建计算表( DAX 表达式生成的表,而不是从数据源加载的)。计算表会存储为模型的一部分,常用于中间计算。例如创建一个单价大于3000的产品表:
ExpensiveProducts =
FILTER ('Product','Product'[Unit Price] > 3000
)
3.2 DAX查询
参考《DAX 查询》
DAX查询是一种基于DAX语言的查询方式,是表格模型(如 Power BI、SSAS)底层数据处理的核心框架。无论是将DAX度量值、计算列或计算表拖放到报表中,还是进行筛选、排序等操作,实质上是在调用 DAX 查询来计算和显示结果。这种调用通常是通过工具的引擎自动完成的,用户无需直接编写查询语句。然而,在某些场景下,手动编写DAX查询是非常有用的,例如:
- 动态生成临时分析表,而不修改现有数据模型;
- 测试度量值逻辑,通过DEFINE MEASURE快速验证其准确性;
- 实现复杂的数据透视,替代Power BI可视化控件的默认聚合逻辑;
- 导出特定的计算结果,例如生成报表的底层数据。
与DAX公式(如度量值、计算列)不同,DAX查询独立于数据模型,通过EVALUATE语句等关键字直接动态生成结果。用户可以利用SQL Server Management Studio(SSMS)、Power BI报表生成器以及开源工具(如DAX Studio)等来创建和运行自己的DAX查询。接下来,我们将详细介绍DAX查询语句的编写方式。
3.2.1 DAX 查询的关键字
DAX 查询的语法相对简单,主要包括一个必需关键字 EVALUATE 以及几个可选关键字,每个关键字都定义了一个在查询期间使用的语句。
| 陈述 | 描述 |
|---|---|
| DEFINE | 用于定义查询中使用的变量、度量值或表,这些定义仅在当前查询中有效 |
| EVALUATE | 执行DAX查询的核心部分,返回表表达式的结果 |
| MEASURE | 定义一个度量值,可在查询中多次使用 |
| ORDER BY | 对EVALUATE语句返回的的结果进行排序 |
| START AT | 与ORDER BY配合使用,指定排序结果的起始值 |
| VAR | 定义一个变量,存储中间结果,便于在复杂查询中复用 |
3.2.1.1 EVALUATE(必须)
EVALUATE 是 DAX 查询中最基本的关键字,用于指定一个表表达式。一个 DAX 查询至少需要包含一个 EVALUATE 语句,但也可以包含多个。其语法结构为:
EVALUATE <table>
例如,以下查询将返回 “Internet Sales” 表中的所有行和列:
EVALUATE'Internet Sales'
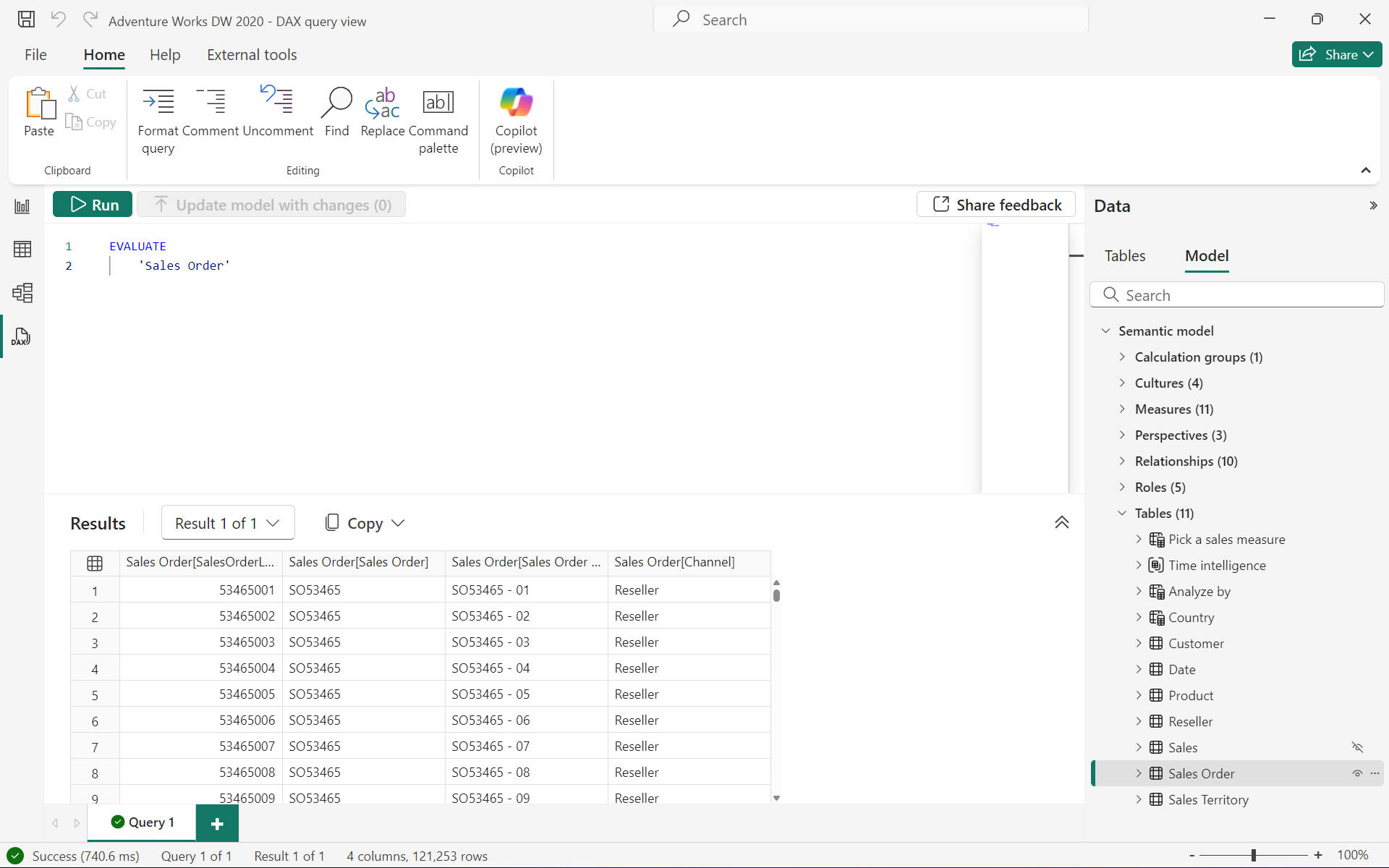
3.2.1.2 ORDER BY(可选)
ORDER BY 关键字用于定义一个或多个表达式(返回标量),以对查询结果进行排序,其语法结构为:
EVALUATE <table>
[ORDER BY {<expression> [{ASC | DESC}]}[, …]]
其中,ASC 表示升序排序(默认值),DESC 表示降序排序。例如以下查询将返回 “Internet Sales” 表中的所有行和列,并按 “Order Date” 升序排序:
EVALUATE'Internet Sales'
ORDER BY'Internet Sales'[Order Date]

3.2.1.3 START AT(可选)
START AT 关键字用于 ORDER BY 子句内,定义查询结果开始的值。START AT 参数必须与 ORDER BY 子句中的列一一对应,其参数数量不能超过 ORDER BY 中的列数量,例如第一个参数定义第一列的起始值,第二个参数定义在第一列值满足第一个参数的情况下,第二列的起始值。,其语法为:
EVALUATE <table>
[ORDER BY {<expression> [{ASC | DESC}]}[, …]
[START AT {<value>|<parameter>} [, …]]]
以下查询将从 “SO7000” 开始返回 “Internet Sales” 表中的所有行和列,并按 “Sales Order Number” 升序排序:
EVALUATE'Internet Sales'
ORDER BY'Internet Sales'[Sales Order Number]
START AT "SO7000"
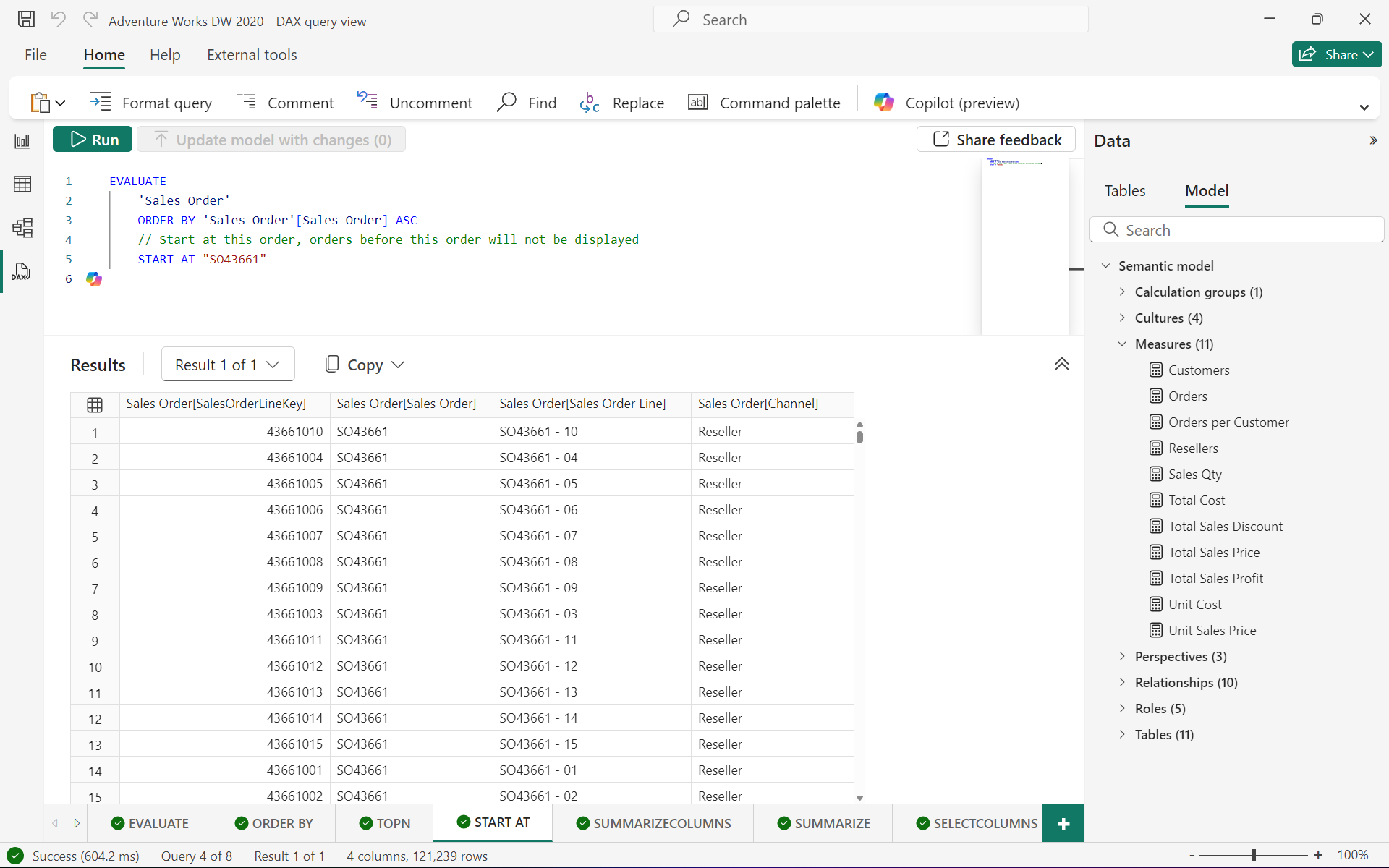
3.2.1.4 DEFINE(可选)
DEFINE 关键字用于在 DAX 查询中定义临时的计算实体(如变量、度量值、表或列),这些定义仅在查询期间有效。它位于 EVALUATE 语句之前,并且对查询中的所有 EVALUATE 语句都有效,其语法为:
[DEFINE ((MEASURE <table name>[<measure name>] = <scalar expression>) | (VAR <var name> = <table or scalar expression>) |(TABLE <table name> = <table expression>) | (COLUMN <table name>[<column name>] = <scalar expression>) | ) +
](EVALUATE <table expression>) +
- 定义的实体:可以是MEASURE、VAR、TABLE或COLUMN
- 名称:定义的实体名称,必须是文本。此名称不必是唯一的,因为仅在查询期间有效。
- 表达式:任何返回表或标量值的 DAX 表达式。如果需要将标量表达式转换为表表达式,请使用大括号
{}将表达式包装在表构造函数中,或使用ROW()函数返回一个具有单行的表。
例如定义临时度量值并计算:
DEFINEMEASURE 'Internet Sales'[Internet Total Sales] =SUM ( 'Internet Sales'[Sales Amount] )EVALUATE
SUMMARIZECOLUMNS ('Date'[Calendar Year],TREATAS ({2013,2014},'Date'[Calendar Year]),"Total Sales", [Internet Total Sales],"Combined Years Total Sales",CALCULATE ([Internet Total Sales],ALLSELECTED ( 'Date'[Calendar Year] ))
)
ORDER BY [Calendar Year]
该查询通过 DEFINE 定义了一个度量值 “Internet Total Sales”,然后使用SUMMARIZECOLUMNS函数对数据进行汇总和分析,计算 2013 年和 2014 年的总销售额,最后将结果按 “Calendar Year” 排序。
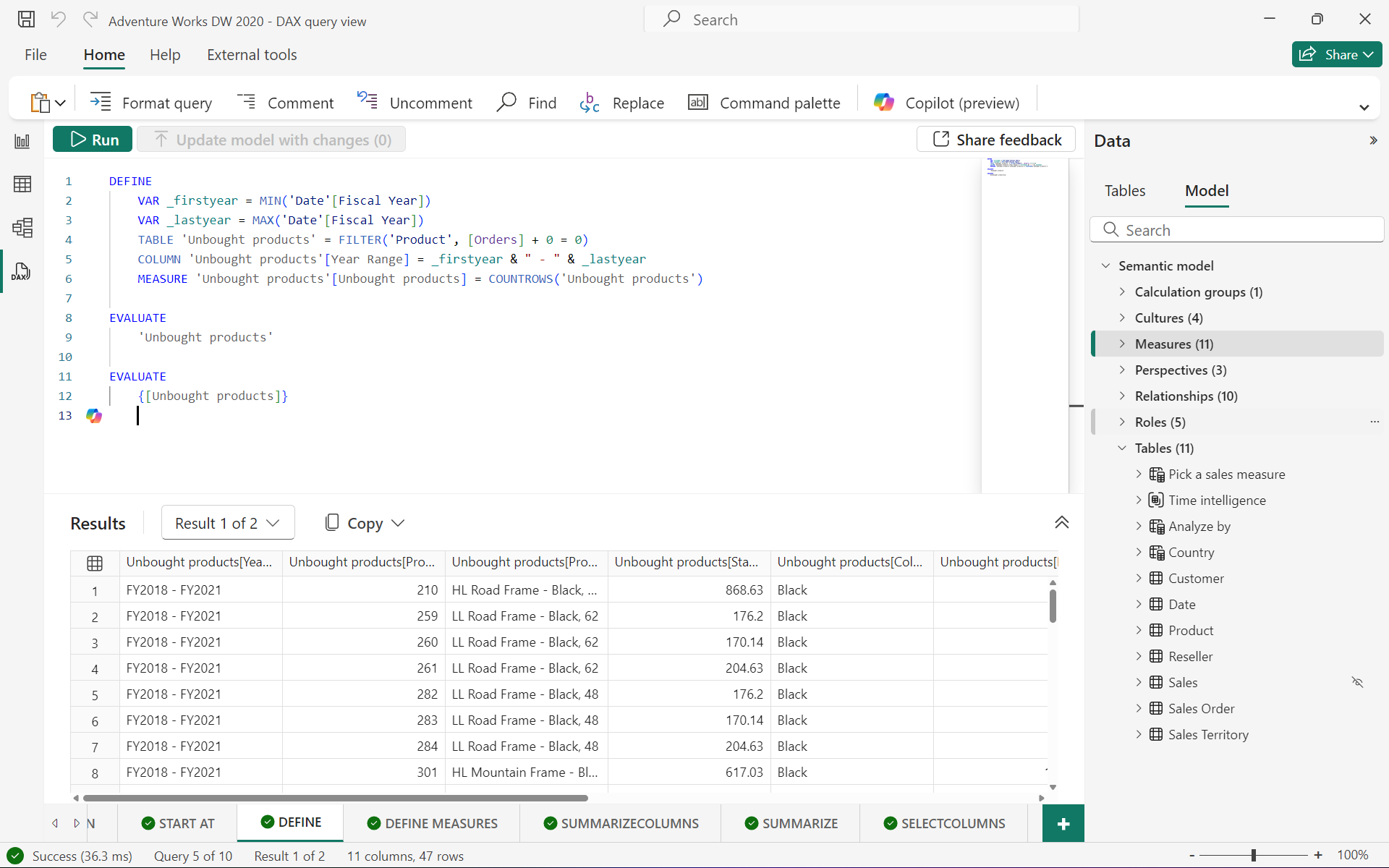
注意事项:
- 查询中只能有一个 DEFINE 语句,但可以包含多个定义;
- 定义临时度量值(
MEASURE):查询中的度量值定义会覆盖同名的模型度量值,但仅在查询内有效,不会修改数据模型。 - 不建议使用 TABLE 和 COLUMN 定义,因为它们可能会导致运行时错误。
- 复杂查询可能导致性能问题,建议先用
SUMMARIZE或GROUPBY减少数据量。 - 避免在查询中使用过多嵌套的
FILTER,改用CALCULATE修改上下文。
以下函数常用于 EVALUATE 块中生成表:
SUMMARIZE:按指定列分组,类似 SQL 的 GROUP BY。ADDCOLUMNS:向现有表添加计算列。FILTER:筛选表中的行。CROSSJOIN:生成多表的笛卡尔积。TOPN:返回前 N 行(如排名分析)
3.2.2 DAX 查询中的参数化与应用示例
DAX 查询支持参数化,用户可以通过 Execute 方法(XMLA)的 Parameters 元素来定义参数并为其分配值。在查询中,可以通过为参数名称加上 @ 字符作为前缀来引用这些参数。参数化查询可以提高查询的灵活性和可重用性,用户只需更改参数值即可重复使用同一个查询语句。
| 应用场景 | 操作 | 说明 |
|---|---|---|
| 数据探索 | 简单查询 | 直接操作物理表,快速提取数据 |
| 动态分析与测试 | 定义临时度量值进行分析 | 1. 临时报表需求:快速生成分享一个临时报表(临时度量值不会污染数据模型) 2. 验证度量逻辑:测试 度量值的逻辑是否正确 ,而不用修改模型 3. 动态参数化查询 |
总结:
- DAX 查询:适合临时性、一次性分析,或需要动态调整逻辑的场景。DAX Studio支持调试查询、查看执行计划和性能分析;SQL Profiler可监控 SSAS 或 Power BI 的查询执行过程。
- 模型度量值:适合重复使用、需要与报表交互的固定逻辑。
3.3 FILTER
3.3.1 基本用法
FILTER 是一个表函数,同时也是迭代器。它的主要作用是从一个表中筛选出满足特定条件的行。其语法如下。其中,两个参数分别代表需要筛选的表以及筛选条件表达式。FILTER 函数会逐行扫描表,并返回满足条件的所有行。
FILTER ( <table>, <condition> )
FILTER 最基本的用途是根据条件筛选数据。例如,如果要计算红色产品的数量,如果不使用表函数,一种可能的实现方式是:
NumOfRedProducts :=
SUMX ('Product',IF ( 'Product'[Color] = "Red", 1, 0 )
)
这段代码的意图不够直观,它没有直接表达“计算红色产品的数量”,而是通过“对每一行判断颜色并累加计数”的方式实现。而且SUMX 是一个迭代函数,它会对表中的每一行进行迭代计算。虽然 IF 函数本身开销不大,但当表非常大时,这种逐行迭代的方式可能会导致性能问题。
更优的方式是使用FILTER 函数先筛选出红色产品,再进行计算:
NumOfRedProducts :=
COUNTROWS (FILTER ( 'Product', 'Product'[Color] = "Red" )
)
这段代码直接表达了“筛选红色产品并计数”的逻辑,可读性强,而且DAX 优化器能够更好地理解其意图,从而生成更高效的查询计划(FILTER 函数在内部进行了优化,能够更高效地处理筛选逻辑,性能通常优于逐行迭代)。
3.3.2 嵌套使用
FILTER 函数可以嵌套使用,以实现更复杂的筛选条件。例如,以下代码筛选出品牌为 Fabrikam 且利润率高于成本3倍的产品:
FabrikamHighMarginProducts =
FILTER (FILTER ('Product','Product'[Brand] = "Fabrikam"),'Product'[Unit Price] > 'Product'[Unit Cost] * 3
)
虽然嵌套 FILTER 可以实现复杂筛选,但也可以使用 AND 来简化代码,并实现相同的功能。例如,上述嵌套 FILTER 可以改写为:
FabrikamHighMarginProducts =
FILTER ('Product',AND ('Product'[Brand] = "Fabrikam",'Product'[Unit Price] > 'Product'[Unit Cost] * 3)
)
3.3.3 性能优化
-
高选择性条件优先:在处理大型表时,
FILTER函数的性能至关重要。如果一个条件比另一个条件更具选择性(即能更快地过滤掉大量行),建议将其放在内层(当存在嵌套调用时,DAX 通常先计算最里面的函数)。例如:// 比起Fabrikam品牌,高于成三倍的产品更少,所以优先筛选 FabrikamHighMarginProducts = FILTER (FILTER ('Product','Product'[Unit Price] > 'Product'[Unit Cost] * 3),'Product'[Brand] = "Fabrikam" ) -
优先使用布尔筛选器:建议尽量使用布尔筛选器,比如直接在 CALCULATE 函数中指定的条件,在在必要时才使用
FILTER函数,比如第一个示例可以写作:NumOfRedProducts := CALCULATE (COUNTROWS ( 'Product' ),'Product'[Color] = "Red" )- 布尔筛选器的优势:布尔筛选器直接作用于列,可以快速地在内部进行筛选。这种筛选方式是高度优化的,因为它直接利用了列存储的索引结构,而表表达式(如
FILTER函数)需要生成一个满足条件的子表,此过程涉及到逐行迭代和条件评估,因此比直接使用布尔筛选器的开销要大。 - 布尔表达式的局限性:布尔筛选器作为筛选器参数使用时,存在一些限制,包括不能引用多个表中的列、不能引用度量值、不能使用嵌套 CALCULATE 函数、不能使用扫描或返回表的函数。表表达式可以满足更复杂的筛选要求,所以建议在必要时才使用
FILTER函数。
- 布尔筛选器的优势:布尔筛选器直接作用于列,可以快速地在内部进行筛选。这种筛选方式是高度优化的,因为它直接利用了列存储的索引结构,而表表达式(如
3.4 ALL 、 ALLEXCEPT、ALLSELECTED
| 函数 | 描述 | 适用场景 |
|---|---|---|
ALL | 清除指定表或列的任何筛选条件。 | 用于计算全局值,忽略当前筛选上下文。 |
ALLEXCEPT | 清除表中指定列之外其他列的所有筛选条件。 | 用于计算全局值,但保留某些关键列的筛选条件。 |
ALLSELECTED | 保留外部筛选器(报表、页面或可视化控件上的筛选器) 忽略内部筛选器 | 根据用户的选择动态调整计算,返回当前报表或可视化中可见的值 |
3.4.1 ALL :清除筛选
ALL 函数用于返回一个表的所有行,或者指定列的所有不同值。它的语法如下:
ALL ( <table> )
ALL ( <column>, [<column>], ... )
- 如果参数是表名,
ALL返回该表的所有行。 - 如果参数是列名,
ALL返回这些列的所有不同值。如果将多个列作为参数传递给ALL,则得到多个列的所有不同值组合
假设我们需要计算销售额占总销售额的百分比,ALL 函数可以帮助我们忽略报表中的筛选器,计算总销售额:
Sales Amount :=
SUMX (Sales,Sales[Quantity] * Sales[Net Price]
)All Sales Amount :=
SUMX (ALL ( Sales ),Sales[Quantity] * Sales[Net Price]
)Sales Pct := DIVIDE ( [Sales Amount], [All Sales Amount] )
在这个例子中,All Sales Amount 使用 ALL ( Sales ) 忽略了报表中的筛选器,计算了所有销售额的总和。这样,即使报表筛选了某个类别,Sales Pct 仍然可以正确计算销售额的百分比。

3.4.2 ALLEXCEPT :清除指定列之外的筛选
ALLEXCEPT 函数用于从指定表的所有列中移除筛选器,除了你明确指定想要保留的那些列。其语法为:它的语法如下:
ALLEXCEPT ( <table>, <column>, [<column>], ... )
- 参数
<table>是要处理的表。 - 参数
<column>是要排除的列。
假设我们有一个包含多列的 Product 表,我们希望生成一个包含所有列的值组合,但排除 ProductKey 和 Color 列:
ALLEXCEPT ( 'Product', 'Product'[ProductKey], 'Product'[Color] )
假设我们想要生成一个仪表板,显示销售金额超过平均销售金额两倍的产品的类别和子类别,代码如下(更好的方式是使用CALCULATE函数):
BestCategories =
// 存储所有类别和子类别的列表
VAR Subcategories =ALL ('Product'[Category],'Product'[Subcategory])
// 计算每个子类别的平均销售额
VAR AverageSales =AVERAGEX (Subcategories,SUMX (RELATEDTABLE ( Sales ),Sales[Quantity] * Sales[Net Price]))
// 使用 FILTER 函数筛选出销售金额超过平均值两倍的子类别
VAR TopCategories =FILTER (Subcategories,VAR SalesOfCategory =SUMX (RELATEDTABLE ( Sales ),Sales[Quantity] * Sales[Net Price])RETURNSalesOfCategory >= AverageSales * 2)
RETURNTopCategories

3.4.3 ALLSELECTED 只保留外部(报表)筛选器
ALLSELECTED只保留用户通过筛选器或交互操作所选择的筛选条件,而忽略当前可视化对象内部的筛选条件,最终根据用户选择,返回当前报表的可见值。
假设我们有一个包含矩阵和切片器的报告,在这个报告中,我们计算了一个名为 Sales Pct 的度量值,表示销售额的百分比。由于使用ALL 函数,不考虑任何我筛选器,所以即使用户在报表上使用切片器进行类别筛选,计算是还是所有类别的销售占比,所以总计结果不是100%。
Sales Pct :=
DIVIDE (SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ),SUMX ( ALL ( Sales ), Sales[Quantity] * Sales[Net Price] )
)

如果使用ALLSELECTED ,计算时只考虑当前用户通过切片器筛选之后的类别数据,总结为100%。报告的数字反映的是与可见总数的百分比,而不是与所有销售总额的百分比。这正是我们期望的结果。
Sales Pct :=
DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), SUMX ( ALLSELECTED ( Sales ), Sales[Quantity] * Sales[Net Price] )
)

ALLSELECTED 是一个强大而有用的 DAX 函数,尤其适用于需要根据用户选择的筛选条件动态调整计算范围的场景。然而,由于其复杂性,ALLSELECTED 有时会返回意外结果(需要动态地根据用户的选择和报表的全局筛选条件来调整筛选范围)。
3.5 VALUES 与 DISTINCT
3.5.1 语法
常规关系中,当关系无效时,DAX 引擎会自动在表中添加一个空白行,以维护引用完整性(简单理解就是即使不匹配的项,也添加一个空白行来匹配它,详见《PowerBI数据建模基础操作1》2.7章节)。 VALUES与 DISTINCT在处理空白行时表现不同:
| 函数 | 返回结果 | 说明 |
|---|---|---|
VALUES(Column) | 返回列的唯一值列表,考虑筛选器和空白行(如果存在) | 如果某列包含关联表中不存在的值 计算引擎会添加一个空白项来表示这种不匹配 |
VALUES(TableName) | 返回表的所有行,再加一个空白行(如果存在不匹配情况) | 仅接受表引用 |
DISTINCT(Column) | 返回唯一值列表,考虑筛选器但不考虑空白行 | 纯粹基于列本身的去重,不检查关联表的有效性。 |
DISTINCT(Table) | 返回表的唯一行,不考虑空白行 | 接受任何有效的表表达式。 |
- 在计算列或计算表中,因为不存在筛选器,
VALUES与DISTINCT和ALL返回的结果是一样的,如果是在度量值中,因为考虑筛选器,结果会不一样。 - 根据经验,
VALUES应该是您的默认选择,只有当您希望显式排除可能的空白值时,才使用 DISTINCT。
3.5.2 空白行的产生
下面演示如何产生空白行。在以下模型中,产品表和销售表以ProductKey键进行一对多连接,其中产品表是“一”方。产品分为不同的种类,每个产品还有不同的颜色,总共16种颜色。

现在删除产品表中所有的银色产品。对于常规关系,为了维护引用完整性,计算引擎会自动为不匹配的关系添加空白行。
- 孤立行:销售表中的银色产品无法在产品表中找到匹配的记录,这些无法匹配的行被称为“孤立行”
- 引入空白行:为了维护引用完整性,即仍然考虑这些孤立行,DAX 引擎会在产品表中自动添加一个空白行。所有孤立行都会链接到这个空白行。
- 空白行的所有列值都是空白(BLANK),且无论销售表有多少孤立行,产品表中也只会添加一个空白行。
- 表视图中不可见:如果在表视图中检查产品表,是看不到空白行的,因为它是在加载数据模型期间自动创建的行。如果恢复了所有的银色产品,则一对多关系完全匹配,空白行将从表中消失。
接着创建以下三个度量值,统计产品表中的颜色数:
NumOfAllColors := COUNTROWS ( ALL ( 'Product'[Color] ) ) // ALL 函数始终返回列的所有唯一值,不考虑任何筛选器
NumOfColors := COUNTROWS ( VALUES ( 'Product'[Color] ) ) // VALUES考虑筛选器和空白行
NumOfDistinctColors := COUNTROWS ( DISTINCT ( 'Product'[Color] ) ) // DISTINCT考虑筛选器,但不考虑空白行

3.5.3 处理无效关系
一个设计良好的模型不应该出现任何无效的关系。因此,如果您的模型是完美的,那么VALUES 与 DISTINCT这两个函数总是返回相同的值。如果存在无效关系,那么计算时就要注意了。假设我们要计算每个产品的平均销售额,有三种方式:
-
使用
VALUES:AvgSalesPerProduct := DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), COUNTROWS ( VALUES ( 'Product'[Product Code] ) ) ) -
使用
DISTINCT:AvgSalesPerDistinctProduct := DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), COUNTROWS ( DISTINCT ( 'Product'[Product Code] ) ) ) -
使用
VALUES,但统计连接字段Sales[ProductKey]AvgSalesPerDistinctKey := DIVIDE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ), COUNTROWS ( VALUES ( Sales[ProductKey] ) ) )

AvgSalesPerProduct:VALUES会将所有空白行视为一个单独的行(分母为1),相当于不同种类的银色产品的销量都聚合到一起,结果是一个异常大的数;AvgSalesPerDistinctProduct:DISTINCT完全忽略空白行,孤立行计算结果为空白(BLANK)AvgSalesPerDistinctKey:使用VALUES考虑空白行情况,但直接从销售表中 进行统计,避免了产品表中可能存在的空白行问题(销售表的Sales[ProductKey]字段依旧保留所有银色产品的正确行数)。
3.6 单个值的表
单一的数字或文本值称之为标量值(例如3.14),度量值必须返回标量值。不过在 DAX 中,一个只有一行一列的表可以像标量值一样使用,例如{3.14}。例如VALUES 函数可以用于计算标量值,但需要确保返回的表只有一行一列。
3.6.1 使用IF…VALUES组合
假设我们有一个按类别和子类别划分的品牌数量报告,我们还想同时看到品牌名,一种可能的解决方案是使用 VALUES 来检索不同的品牌并返回它们的值。但是,只有在品牌只有一种值的特殊情况下才是可能的,所以我们需要使用IF 语句保护代码,如果返回空白,表示存在多个品牌值。
Brand Name :=
IF ( COUNTROWS ( VALUES ( Product[Brand] ) ) = 1, VALUES ( Product[Brand] )
)

3.6.2 使用HASONEVALUE…VALUES组合
上述代码使用 COUNTROWS 检查 Products 表的 Brand 列是否只选择了一个值,另一个更简单的函数是HASONEVALUE,它可以自动检查列是否只有一个可见值(返回TRUE或FALSE):
Brand Name :=
IF ( HASONEVALUE ( 'Product'[Brand] ), VALUES ( 'Product'[Brand] )
)
3.6.3 使用SELECTEDVALUE函数
为了简化开发人员的工作,DAX 提供了一个 SELECTEDVALUE 函数,该函数自动检查列是否包含单个值。如果包含,则将该值作为标量返回;如果有多个值,也可以定义要返回的默认值,其语法为:
// 两个参数分别是列名和多个值时返回的默认值
SELECTEDVALUE(<columnName>[, <alternateResult>])
上述代码可改为:
Brand Name := SELECTEDVALUE ( 'Product'[Brand], "Multiple brands" )
3.6.4 使用CONCATENATEX,连接所有表值
如果想要列出所有品牌,而不是返回 “Multiple brands” 这样的信息,可以使用 CONCATENATEX 函数。CONCATENATEX可以迭代一个表的值,并将它们连接成一个字符串,其语法为:
CONCATENATEX(<table>, <expression>[, <delimiter> [, <orderBy_expression> [, <order>]]...])
| 参数 | 描述 |
|---|---|
<table> | 要计算的表 |
<expression> | 计算的表达式,逐行迭代,通常是一个列引用或更复杂的表达式。 |
<delimiter> | (可选)用于连接各个值的分隔符。如果不指定,默认为空字符串。 |
<orderBy_expression> | (可选)用于对输出字符串中的值进行排序的表达式,逐行迭代 |
<order> | (可选)指定排序方式,默认值为降序(DESC、FALSE或0都可以);也可以是是升序 ( ASC、TRUE或1都可以) |
上述代码可改为:
[Brand Name] :=
CONCATENATEX ( VALUES ( 'Product'[Brand] ), 'Product'[Brand], ", "
)

注意:
CONCATENATEX是一个迭代函数,如果表非常大,建议先对表进行筛选或优化,比如先使用VALUES或DISTINCT函数去重。
CONCATENATEX可以进行多列计算。假设我们有一个名为 Employees 的表,结构如下:
| FirstName | LastName |
|---|---|
| Alan | Brewer |
| Michael | Blythe |
以下代码返回 “Alan Brewer, Michael Blythe”。
= CONCATENATEX(Employees, [FirstName] & " " & [LastName], ",")
四、计算上下文
在 DAX 中,计算上下文是指公式在执行计算时所处的“环境”,同一 DAX 表达式在不同的上下文中可能会产生不同的结果。计算上下文分为两种:筛选上下文和行上下文,筛选上下文筛选,行上下文迭代。
4.1 筛选上下文与行上下文
4.1.1 筛选上下文的定义与作用
筛选上下文是 DAX 中最常见的一种上下文,它的作用是对数据进行筛选。筛选上下文由报表中的行、列、切片器以及其他可视化元素(比如报表上的筛选器)共同定义,是所有筛选的集合。每个单元格的筛选上下文是独立的,它决定了该单元格计算时所使用的数据子集。
比如以下度量值,放入矩阵中,每个单元格的筛选上下文会同时筛选行(品牌)和列(年份)以及切片器选项(Education),这种筛选上下文的定义使得每个单元格的计算结果都不同。
Sales Amount:= SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
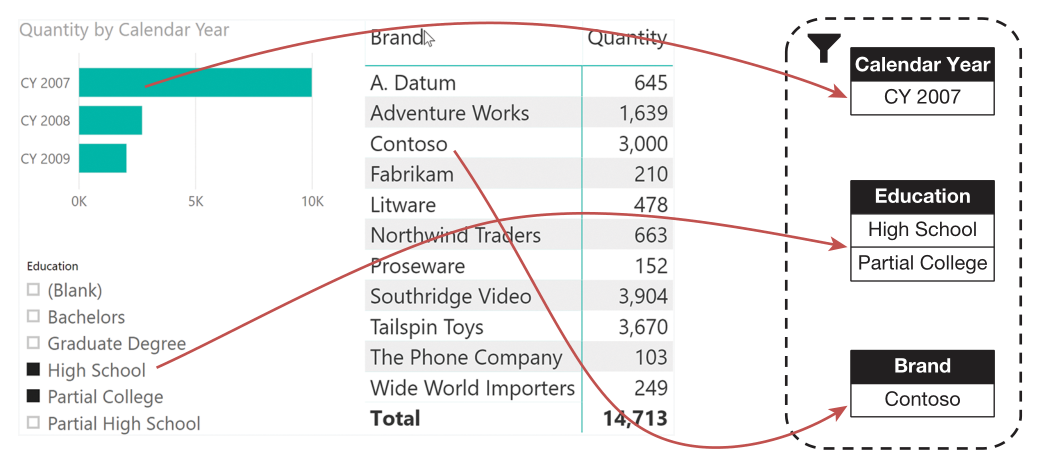
对于左上角的单元格(A.Datum, CY 2007, 57,276.00),其筛选上下文包含行(品牌Contoso)。列(CY2007)以及切片器的选择( High School 和 Partial College)。
4.1.2 行上下文
当我们定义一个计算列时,DAX 会自动为每一行创建一个行上下文,从而逐行计算表达式的结果,而无需手工创建(计算列的计算永远在行上下文中执行)。例如,定义一个计算列来计算毛利润:
Sales[Gross Margin] = Sales[Quantity] * (Sales[Net Price] - Sales[Unit Cost])
在这个例子中,DAX 会逐行计算 Sales[Quantity]、Sales[Net Price] 和 Sales[Unit Cost] 的值,并计算出每行的毛利润。
行上下文也可以通过迭代函数(如 SUMX)来手动创建,例如,定义一个度量值来计算总毛利润:
Gross Margin :=
SUMX (Sales,Sales[Quantity] * ( Sales[Net Price] - Sales[Unit Cost] )
)
行上下文的一个重要特性是它允许列引用。在行上下文中,DAX 可以通过列引用获取某行的值。然而,如果没有行上下文,列引用是无法工作的。例如,以下度量值是非法的:
Gross Margin := Sales[Quantity] * (Sales[Net Price] - Sales[Unit Cost])
这个公式试图直接引用列的值,但由于没有行上下文,DAX 无法确定应该使用哪一行的值。因此,这个公式在度量值中是不合法的,但在计算列中是合法的,因为计算列会自动创建行上下文。
| 特性 | 筛选上下文 | 行上下文 |
|---|---|---|
| 作用 | 筛选数据,定义数据子集 | 逐行计算表达式,获取列值 |
| 创建方式 | 由报表的行、列、切片器等定义 | 通过计算列或迭代函数创建 |
| 影响范围 | 影响整个数据模型 | 仅影响当前表的行 |
| 使用场景 | 通常用于报表中,通过行、列和切片器等元素定义数据的筛选条件。 | 用于计算列和迭代函数中,逐行计算表达式。 |
4.2 计算上下文的常见误区
4.2.1 在计算列中使用聚合函数
考虑以下公式,在 Sales 表中的计算列中的使用SUM函数,结果会是怎样的呢?
Sales[SumOfSalesQuantity] = SUM ( Sales[Quantity] )
- 每行的值不同。
- 所有行的值相同。
- 错误;无法在计算列中使用 SUM。-
正确答案是计算列中的每一行都会显示相同的值,即 Sales[Quantity] 的总计。因为计算列是在数据刷新时计算的,计算时通过行上下文进行逐行迭代。此公式中只有计算列自动生成的行上下文,没有筛选上下文,因此筛选上下文为空。SUM 函数在这种情况下会作用于整个 Sales 表,所有行的计算结果都是一样的,即 Sales[Quantity] 的总计。本质上,此公式等同于:
Sales[SumOfSalesQuantity] = SUMX ( Sales, Sales[Quantity])
很多人会错误地认为,计算列中的每一行会显示不同的值,即当前行的 Sales[Quantity] 的值。这种误解的根源在于混淆了筛选上下文和行上下文。实际上,行上下文只是告诉 DAX 在当前行中进行计算,但它不会筛选数据。再次记住:筛选上下文筛选,行上下文迭代。
4.2.2 在度量值中使用列
考虑以下公式,下面三个选项哪个是正确的?
GrossMargin% := ( Sales[Net Price] - Sales[Unit Cost] ) / Sales[Unit Cost]
- 公式工作正常,需要在报表中验证结果。
- 错误,无法编写公式。
- 可以编写公式,但在报表中返回错误信息。
这个公式试图计算毛利百分比,但没有使用任何聚合函数。由于这个公式没有提供行上下文,不知道该用哪一行的值进行计算,所以这个公式在度量值中的无效的。不过此公式在计算列中是有效的,因为计算列会自动创建行上下文。
4.3 迭代与行上下文
4.3.1 使用迭代函数创建行上下文
上一节在度量值中直接使用列引用是不正确的,因为没有提供行上下文。如果要在度量值中进行列引用,正确的做法是通过迭代函数(比如 SUMX)来创建行上下文,比如上式可改为:
GrossMargin% :=
SUMX (Sales, // 外部筛选上下文和行上下文( Sales[Net Price] - Sales[Unit Cost] ) / Sales[Unit Cost] // 外部筛选上下文、行上下文 以及新的行上下文
)
在这个式子中,SUMX 作为迭代器函数,在处理 Sales 表(第一个参数)时会创建一个行上下文。计算时,它将每行的值传递给表达式(第二个参数)进行以进行逐行计算。所有迭代器函数的执行方式都一样:
- 根据当前上下文计算第一个参数,以确定需要扫描的表。
- 为表的每一行创建一个行上下文。要注意的是:
- 迭代器函数不会修改已存在的筛选上下文(比如筛选红色产品),而是在已有的上下文中添加一个新的行上下文。
- 对于嵌套行上下文,DAX 会优先使用当前正在迭代的行上下文,而无法直接访问外层的行上下文。也就是如果表上已经有行上下文(外层循环),新创建的行上下文(内层循环)会覆盖之前创建的的行上下文。
- 迭代整张表,在已确定的上下文(筛选上下文+行上下文)中执行表达式(第2个参数)计算。
- 聚合计算结果。
4.3.2 不同表上的嵌套行上下文(RELATED 和 RELATEDTABLE )
DAX 支持迭代器嵌套,即在一个迭代器的表达式中使用另一个迭代器,这样可以生成非常强大的表达式,在处理多表关联时非常有用。例如下面这个嵌套的 SUMX 函数,它扫描三个表:Categories,Products , Sales;计算每个产品分类下的总销售额,同时考虑了产品的单价和分类的折扣。
SUMX ('Product Category', -- 最外层迭代器,逐行扫描 'Product Category' 表,处理每个产品分类SUMX (RELATEDTABLE ( 'Product' ), -- 对于每个产品分类,获取与当前产品分类相关的所有产品SUMX (RELATEDTABLE ( Sales ), -- 对于每个产品,获取相关的销售记录Sales[Quantity] * 'Product'[Unit Price] * 'Product Category'[Discount] -- 计算每个销售记录的销售额))
)
最里面的表达式——三个因子的乘法 ———引用了三张表,每个行上下文均代表当前正在被迭代的表。两个 RELATEDTABLE 函数返回在当前行上下文中关联表的行。因此, RELATEDTABLE ( Product ) 是在Categories 表的行上下文中被执行,返回指定产品类型对应的产品。基于同样的原则,RELATEDTABLE ( Sales ) 返回指定产品对应的销售记录。
这段代码只是为了演示迭代器嵌套是可行的,但是多嵌套迭代会导致计算量显著增加。为了提高性能和可读性,可以使用 RELATED 函数来直接引用相关表中的值,而不是通过嵌套迭代器逐层扫描。优化后的代码如下:
SUMX (Sales,Sales[Quantity]* RELATED ( 'Product'[Unit Price] ) // 引用了与当前销售记录相关的产品的单价* RELATED ( 'Product Category'[Discount] ) // 引用了与当前销售记录相关的产品分类的折扣
)
- RELATED :用于从关系中的多端表访问一端表的列值(返回值);
- RELATEDTABLE:用于从关系中的一端表访问多端表的的所有行(返回表);
所以方式1可总结为从一端表中进行计算,每次都迭代扫描多端表中的子表;方式2是在多段表中进行计算,只需要查找一端表中的表值。
在不同的表中,行上下文是独立的。对于嵌套迭代,只要是计算不同的表(表之间存在关系),都可以使用方式2进行计算:在一个 DAX 表达式中通过 RELATED 函数来直接引用其它表中的字段。
如果两张表间是一对一关系,那么
RELATED和RELATEDTABLE在两表间都能工作,它们会产生列值或具有单行的表。
4.3.3 同一表上的嵌套行上下文(使用变量处理)
在同一个表上嵌套行上下文是一个常见的场景,尤其是在需要对数据进行排名或比较时。例如,创建计算列来计算每个产品的价格排名,我们可以先使用 PriceOfCurrentProduct 作为占位符来表示当前产品的价格:
1. 'Product'[UnitPriceRank] =
2. COUNTROWS (
3. FILTER (
4. 'Product',
5. 'Product'[Unit Price] > PriceOfCurrentProduct
6. )
7. ) + 1
FILTER 函数返回所有价格高于当前产品价格的产品,COUNTROWS 函数计算 FILTER 函数结果。现在需要找到一种方法来表达当前产品的价格。 由于代码是在计算列中编写的,因此引擎会自动创建一个默认行上下文,用于扫描 Product 表。 此外,FILTER 函数是一个迭代器,FILTER 生成的行上下文会再次扫描产品表。 所以在运行最内层表达式期间,在同一个表上同时有两个行上下文。
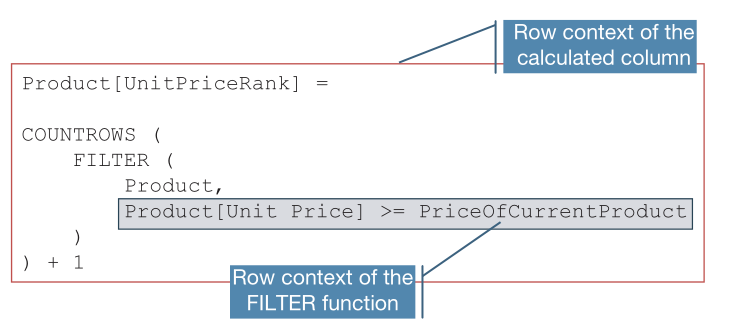
由FILTER 函数生成的内部行上下文会隐藏外部行上下文,也就是说此时我们无法访问外层 Product[Unit Price]的值,所以最佳的解决办法是使用变量保存它,即定义:
VAR PriceOfCurrentProduct = 'Product'[Unit Price]
此外,通过使用更多变量来分解计算的不同步骤,可以使代码更加易读。最终代码为:
'Product'[UnitPriceRank] =
VAR PriceOfCurrentProduct = 'Product'[Unit Price]
VAR MoreExpensiveProducts =FILTER ('Product','Product'[Unit Price] > PriceOfCurrentProduct)
RETURNCOUNTROWS ( MoreExpensiveProducts ) + 1

这段代码的结果是非连续排名(多个产品价格相同时,跳过平级排名),如果要改成连续排名(也叫Dense Rank,“密集排名”),可以改成计算高于当前价格的 不同价格 数量,而不是计算产品数量。
'Product'[UnitPriceRankDense] =
VAR PriceOfCurrentProduct = 'Product'[Unit Price]
VAR HigherPrices =FILTER (VALUES ( 'Product'[Unit Price] ), -- 获取所有不同的价格'Product'[Unit Price] > PriceOfCurrentProduct -- 筛选出高于当前产品价格的所有不同价格)
RETURNCOUNTROWS ( HigherPrices ) + 1 -- 计算高于当前价格的不同价格的数量,并加1
4.3.4 EARLIER
EARLIER 函数是 DAX 中用于访问外层行上下文的工具,它允许我们在嵌套的行上下文中访问外层的值,其语法为:
EARLIER(<column>, [<n>])
是要访问的列,可选参数n表示要回溯的上下文层级数,默认值为 1。所以在上一节的示例中,我们可以将 EARLIER(Product [UnitPrice])赋值给变量 PriceOfCurrentProduct。
'Product'[UnitPriceRankDense] =
COUNTROWS (FILTER (VALUES ( 'Product'[Unit Price] ),'Product'[UnitPrice] > EARLIER ( 'Product'[UnitPrice] ))
) + 1
此外,还有一个名为 EARLIEST 的函数,它只访问最外层的行上下文。在现实情况中,EARLIER 的第二个参数以及 EARLIEST 函数很少使用(很少有3层及以上的嵌套)。自从2015年变量 VAR 出现以后,EARLIER 可以被彻底取代。
4.4 多表数据模型中的上下文
在实际业务中,大多数数据模型包含多张表,这些表通过关系相互关联。当我们在 DAX 中处理多表数据模型时,行上下文和筛选上下文的行为会受到表之间关系的影响:
- 行上下文:
- 负责迭代单张表中的行,不会自动传递到相关表,也就是说每张表的行上下文都是独立的。
- 如果需要访问其它表的关联列,可以使用
RELATED函数或者RELATEDTABLE函数,但必须遵循关系的方向。- 关系链方向一致:比如全部是一对多,或者全部是多对一,那么关系可以正确的依次传递(单向筛选)
- 关系链的方向不一致:比如Customer 表(1:N)➡ Sales 表(N:1)⬅ Product 表, 那么 Product 表和 Product 表之间是多对多关系,
RELATEDTABLE函数筛选结果会是错误的。
- 筛选上下文:负责在整个数据模型中筛选数据,会根据表之间的关系自动传递。关系的交叉筛选方向决定了筛选上下文的传递方式:
- 单向关系:筛选上下文从一端传递到多端。
- 双向关系:筛选上下文可以在两端之间双向传递。
4.4.1 行上下文与关系
我们使用以下模型进行测试,该模型中一共6张表,都是一对多的关系:

-
RELATED函数:单次多对一关系传递
行上下文仅作用于当前表,无法直接访问其他表的列,例如下面这个计算列公式会失败:Sales[UnitPriceVariance] = Sales[Unit Price] – 'Product'[Unit Price]正确的计算方式是:
Sales[UnitPriceVariance] = Sales[Unit Price] - RELATED ( 'Product'[Unit Price] ) -
RELATED函数:多次多对一关系传递
以下代码在 Product 表中创建计算列,从 Product Category 表中复制各类别名称,关系链传递方向为 Product 表→Product Subcategory 表→ Product Category表。'Product'[Category] = RELATED ( 'Product Category'[Category] ) -
RELATEDTABLE函数:多次一对多传递关系
在 Product Category 表中统计各类产品的销量,关系链传递方向为 Product Category 表→ Product Subcategory 表→ Product 表→Sales 表。'Product Category'[NumberOfSales] =COUNTROWS ( RELATEDTABLE ( Sales ) ) -
RELATEDTABLE` 函数:多对多关系时筛选错误
使用以下公式在Product 表中创建计算列,计算与当前产品相关的所有销售记录。RELATEDTABLE 函数试图从 Product 表访问 Customer 表的所有相关行,但由于关系链的方向不一致(1:N → N:1),RELATEDTABLE 函数无法沿着这个路径正确传递筛选上下文。因此,RELATEDTABLE(Customer) 返回的是 所有客户,而不是与当前产品相关的客户。Product[NumOfBuyingCustomers] =COUNTROWS ( RELATEDTABLE ( Customer ) )

4.4.2 筛选上下文与关系
筛选上下文会根据表之间的关系自动传递。比如创建度量值来计算Sales表,Product表和Customer表中相关行数:
[NumOfSales] := COUNTROWS ( Sales )
[NumOfProducts] := COUNTROWS ( Product )
[NumOfCustomers] := COUNTROWS ( Customer )
如果在 Product 表中筛选 Color 列,筛选上下文会传递到 Sales 表(因为它们之间是双向关系),但不会传递到 Customer 表(因为 Customer 和 Sales 之间是单向关系)。

如果改成在Customer表中筛选Education 列,则筛选可以传递到Sales表和Product表。

请注意关系链中的单个双向关系不会使整个关系链变成双向,比如下面的公式计算Subcategory的个数,筛选从Customer表出发,可以传递到Sales表和Product表,但不会传递到 Product Subcategory 表。
NumOfSubcategories := COUNTROWS ( 'Product Subcategory' )

如果设置Product表和 Product Subcategory 表的筛选的方向为双向,则可以得到正确的结果:

注意:虽然双向筛选看起来可以解决多表筛选的问题,但它的复杂性较高,可能导致意外的结果。建议在特定的度量值中通过
CROSSFILTER函数实现双向筛选,而不是全局启用双向筛选。
4.6 SUMMARIZE
4.6.1 SUMMARIZE语法
参考《PowerBI之DAX 2》3.2章节,SUMMARIZE函数用于对数据进行分组和汇总,其语法为:
SUMMARIZE(<Table>, // 要进行汇总的表<GroupBy_Expression1>, ..., // 分组表达式,可以有多个<Name1>, <Expression1>, ... // 定义新列的名称和表达式,可以有多个[, <Filter_Expression>] // 可选的过滤表达式
)
最常用的方式是提取表中多个列的有效组合,比如比如以下表格:

SUMMARIZE可以提取所有有效的产品购买月份记录:
销售时间表 = SUMMARIZE('销售子表','销售子表'[产品名称],'日期表'[年度月份])

4.6.2 案例:计算所有客户购买产品时的平均年龄
业务要求:计算所有客户在交易发生时的平均年龄(不是计算各个客户购买产品时的平均年龄)。如果一个人在同一年龄多次交易,仅计算一次。
-
首先在Sales表中创建计算列,计算销售时的客户年龄。DATEDIFF函数用于计算时间差。
Sales[Customer Age] = DATEDIFF(RELATED(Customer[Birth Date]), Sales[Order Date], YEAR) -
计算平均年龄
- 直接求均值:同一客户同一年龄的多次交易会被重复计算
Avg Customer Age Wrong :=AVERAGE(Sales[Customer Age])- 对年龄去重后求均值:不同客户同一年龄会被合并为一次记录
Avg Customer Age Wrong Distinct :==AVERAGEX(DISTINCT(Sales[Customer Age]), Sales[Customer Age])- 对客户去重后求均值:Sales[CustomerKey]是一个表列,去重结果还是单个列,而AVERAGEX第一个参数必须是表。
Avg Customer Age Invalid Syntax :=AVERAGEX(DISTINCT(Sales[CustomerKey]), Sales[Customer Age]) // 语法错误!
-
正确解决方案:使用SUMMARIZE生成客户与年龄的唯一组合表,再用AVERAGEX计算均值
Correct Average := AVERAGEX(SUMMARIZE(Sales, Sales[CustomerKey], Sales[Customer Age]),Sales[Customer Age] )

4.6.3 匿名表与模型表
对于多步计算可以使用变量来区分,比如使用VAR来存储计算表:
Correct Average :=
VAR CustomersAge =SUMMARIZE ( Sales, Sales[CustomerKey], Sales[Customer Age]
)
RETURN
--对 Sales 表中 Customer Age 列迭代并计算 Customer Age 的平均值
AVERAGEX ( CustomersAge, Sales[Customer Age]
)
这里要注意的是,通过 DAX 函数(如 SUMMARIZE、FILTER)动态生成的临时表是匿名表,仅在计算过程中临时存在。匿名表可直接用列名,比如直接使用[Customer Age]:
...
RETURN
AVERAGEX ( CustomersAge, [Customer Age]
)
要注意的是,匿名表不能作为表引用,比如不能写成CustomersAge[Customer Age]。只有模型表才可以进行表引用,比如上面代码中SUMMARIZE函数的Sales[Customer Age]参数 。
4.6.4 数据沿袭(Data Lineage)
匿名表中的列引用,除了直接使用[Customer Age]的方式,还可以根据数据沿袭,使用用原始表的表引用,比如AVERAGEX中的Sales[Customer Age] 。
数据沿袭是 DAX 中列的“身份标识”,它表示某列的数据来源(原始表),即使该列被复制、重命名或重组到其他表中,DAX 仍能识别其原始归属。数据沿袭决定了列的归属关系,直接影响筛选上下文传递(如 RELATED、CALCULATE), 匿名表(临时生成的表)中的列仍保留原始数据沿袭。对于以下代码:
VAR CustomersAge = SUMMARIZE(Sales, Sales[CustomerKey], Sales[Customer Age])
虽然 CustomersAge 是临时生成的匿名表,但其列 Sales[CustomerKey] 和 Sales[Customer Age] 仍保留来自 Sales 表的数据沿袭。 因此,在 AVERAGEX 中可以直接用 Sales[Customer Age] 引用该列。
| 特性 | 数据模型表 | 匿名表 |
|---|---|---|
| 定义 | 预先在数据模型中定义的表 | 通过 DAX 函数(如 SUMMARIZE、FILTER)动态生成的临时表 |
| 存储位置 | 持久化存储在模型中 | 仅在计算过程中临时存在 |
| 列引用方式 | 必须用表名限定列(如 Sales[CustomerKey]) | 可直接用列名(如 [Customer Age]),或用原始表名限定(依赖数据沿袭) |
| 能否直接通过变量名引用列 | 是(如 Sales[CustomerKey]) | 否(变量名不是表名,需依赖数据沿袭或直接列名) |
进一步理解,对于VAR X = Order,其中Order是模型表,则有:
SUMX( X , X[Amount] ) // 不可以,匿名表无法进行表引用
SUMX( Order , Order[Amount] ) // 可以,模型表可以进行表引用
SUMX( X , Order[Amount] ) // 可以
SUMX( X , [Amount] ) // 可以,匿名表可直接引用列名,通过数据沿袭找到原始列
SUMX( Order , [Amount] ) // 可以


:Llama模型的简单部署)
)




Java/python/JavaScript/C/C++/GO最佳实现)



攻击解析)






