说明
文章内容包括数据库管理、表操作及查询等核心功能
创建数据库
-- 默认引擎(Atomic)
CREATE DATABASE IF NOT EXISTS test_db;
-- MySQL引擎(映射外部MySQL数据库)
CREATE DATABASE mysql_db ENGINE = MySQL('host:port', 'mysql_db_name', 'user', 'password');
CREATE DATABASE mysql_db ENGINE = MySQL('localhost:3306', 'test', 'test', 'test');
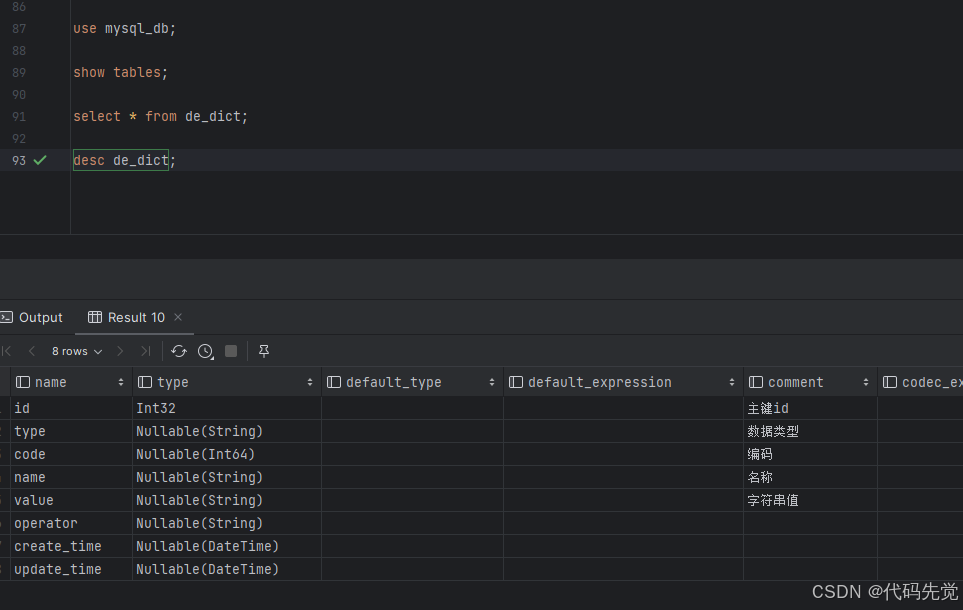
use mysql_db;
show tables;
select * from de_dict;
desc de_dict;
删除数据库
DROP DATABASE test_db;
切换数据库
USE test_db;
本地表(MergeTree引擎)
CREATE TABLE user_logs (
log_id UInt64,
user_id UInt32,
event_time DateTime,
metric Float32
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(event_time) -- 按年月分区
ORDER BY (user_id, event_time) -- 主键及排序键
SETTINGS index_granularity = 8192; -- 索引粒度
分布式表
-- 本地表(集群各节点创建)
CREATE TABLE test.user_event ON CLUSTER data_cluster (
uid String,
dt Date
) ENGINE = MergeTree() PARTITION BY dt ORDER BY uid;
-- 分布式表(逻辑视图)
CREATE TABLE test.user_event_distributed
ENGINE = Distributed('data_cluster', 'test', 'user_event', rand()); -- 随机分片
插入数据
INSERT INTO user_logs VALUES
(1, 101, '2023-10-01 10:00:00', 1.5),
(2, 102, '2023-10-01 11:00:00', 2.8);
查询数据
-- 基础查询
SELECT * FROM user_logs WHERE user_id = 101;
-- 聚合统计
SELECT user_id, SUM(metric) FROM user_logs GROUP BY user_id;
-- 排序与分页
SELECT * FROM user_logs ORDER BY event_time DESC LIMIT 10;
更新/删除数据
-- 删除分区
ALTER TABLE user_logs DROP PARTITION '202310';
-- 删除条件数据
ALTER TABLE user_logs DELETE WHERE user_id = 101;
表结构修改
-- 添加列
ALTER TABLE user_logs ADD COLUMN ip String AFTER user_id;
-- 删除列
ALTER TABLE user_logs DROP COLUMN metric;
-- 修改列类型
ALTER TABLE user_logs MODIFY COLUMN ip IPv4;
其他实用操作
SHOW DATABASES; -- 查看所有数据库
SHOW TABLES FROM test_db; -- 查看库中所有表
DESC user_logs; -- 查看表结构
SELECT * FROM system.clusters; --查看已配置的集群信息
数据导入/导出
-- 导出到CSV
SELECT * FROM user_logs INTO OUTFILE 'data.csv' FORMAT CSV;
-- 从文件导入
INSERT INTO user_logs FROM INFILE 'data.csv' FORMAT CSV;
性能优化建议
批量插入数据(每次插入至少数千行);
避免使用SELECT *,明确指定查询列;
合理使用分区和索引减少扫描范围。


)
】)








![class path resource [] cannot be resolved to absolute file path](http://pic.xiahunao.cn/class path resource [] cannot be resolved to absolute file path)
、位图的实现和布隆过滤器的介绍)

)

)

