在如今的机器学习和深度学习领域,注意力机制绝对是一个热度居高不下的话题。事实上,注意力机制并不是一个全新的概念,早在多年前就已经被提出并应用。比如在图像分类任务中,SENet 和 ECA-Net 等模型中都运用了注意力机制,它们通过对图像特征的筛选和聚焦,提升了模型对图像的分类准确率,这些模型的成功也初步展示了注意力机制在处理图像数据时的强大能力。
而真正让注意力机制火爆起来的,是谷歌发表的那篇具有里程碑意义的论文《Attention Is All You Need》。这篇论文最初是针对自然语言处理(NLP)领域的,它提出的 Transformer 架构以及自注意力机制,彻底改变了 NLP 任务的处理方式,使得模型在文本生成、机器翻译等任务上取得了显著的性能提升。有趣的是,这种强大的注意力机制不仅仅局限于 NLP 领域,在计算机视觉(CV)领域也逐渐崭露头角。越来越多的研究人员开始将注意力机制引入到 CV 任务中,比如图像生成、目标检测等。在这些任务中,注意力机制能够帮助模型更好地聚焦于图像中的关键信息,忽略无关的噪声和干扰,从而提高模型的性能和泛化能力。
现在,几乎在许多不同领域的论文中,我们都能看到注意力机制的身影。很多研究人员为了提高模型的性能,都会选择加入注意力机制模块。这些模块就像是模型的 “眼睛”,让模型能够更加智能地处理数据,捕捉到数据中那些重要的特征和模式。
一、注意力机制:Attention
1.1 什么是注意力机制?
在日常生活中,我们时刻都在运用着注意力机制。比如与人见面时,我们往往会第一时间将目光聚焦在对方的脸部,因为脸部包含了大量用于识别身份、解读情绪的关键信息;阅读文章时,标题会率先吸引我们的视线,它像是文章的 “缩影”,能快速传递核心主题;而阅读段落时,开头部分通常是作者阐述观点、引出下文的重要位置,所以我们会着重关注。通过这些例子,我们能对注意力机制有一个初步的感性认识。
从本质上来说,注意力机制的灵感来源于人类处理外部信息的方式。在现实世界中,我们每一刻接收到的信息既庞大又复杂,像视觉上看到的周围环境、听觉上捕捉到的各种声音等,远远超出了人脑的即时处理能力。如果大脑试图对所有信息都进行同等程度的处理,不仅效率低下,还会消耗过多精力。因此,人类在处理信息时,会本能地将注意力集中在那些对当前任务、目标更重要或更相关的信息上,同时对无关紧要的外部信息进行过滤和弱化处理,这种信息筛选和聚焦的方式,就是我们所说的注意力机制。
在深度学习领域,对于人类而言可以理解为 “关注度” 的注意力机制,在机器模型中体现为对不同信息赋予不同的权重,这些权重通常是介于 0 到 1 之间的小数。权重数值越大,意味着模型对该部分信息的 “关注度” 越高,认为其越重要;权重数值越小,则表示该部分信息相对不那么重要,会被模型在处理过程中适当弱化。通过这种方式,机器模型能够像人类一样,聚焦关键信息,忽略次要信息,从而更高效地完成数据处理和任务执行。
1.2 如何运用注意力机制?
1.2.1 Query&Key&Value
在深入理解注意力机制的运作过程之前,我们需要先掌握三个重要概念:查询(Query)、键(Key)和值(Value)。
查询(Query)可以看作是我们主动提出的一个 “问题” 或者 “寻找目标” 的依据,它是由我们的主观意识生成的特征向量。比如我们在思考 “什么样的电影适合周末放松”,这个思考过程所蕴含的特征信息就是 Query。
键(Key)则是被用来与查询进行比对的信息项,它代表了客观存在的物体或数据的突出特征信息向量。例如电影的类型、主演、评分等信息,这些都可以作为 Key,用于和我们的查询需求进行匹配。
值(Value)代表着物体本身完整的特征向量,它通常和 Key 成对出现。就像电影的详细剧情介绍、完整的视频资源等,这些就是与电影相关特征 Key 对应的 Value。
在注意力机制中,其核心就是通过 Query 与 Key 之间的交互,也就是注意力汇聚的过程,来实现对 Value 的注意力权重分配,最终生成符合我们需求的输出结果。具体来说,就是先计算 Query 与 Key 的相关性,根据这个相关性去筛选出最合适的 Value,并为其赋予相应的权重,从而突出重要信息,弱化次要信息。
1.2.2 注意力机制计算过程
注意力机制的计算过程主要分为三个阶段,下面我们结合具体的数学表达和计算步骤来详细说明:
- 输入 Query、Key、Value:首先,我们将 Query、Key 和 Value 作为输入数据提供给注意力机制模型。这里的 Query、Key 和 Value 通常都是向量形式的数据,它们的维度可能根据具体任务和数据特点有所不同。
- 阶段一:计算相关性或相似性:在这个阶段,我们需要根据 Query 和 Key 计算两者之间的相关性或相似性,从而得到注意力得分。常见的计算方法有点积运算、余弦相似度计算,以及使用多层感知机(MLP)网络等。
- 点积运算:假设 Query 向量为
,Key 向量为
,通过点积运算得到注意力得分
。 点积结果越大,说明 Query 和 Key 的相关性越高。
- 余弦相似度:余弦相似度通过计算两个向量夹角的余弦值来衡量它们的相似程度,公式为
, 其中
和
分别是 Query 和 Key 向量的 L2 范数。余弦相似度的值越接近 1,表示两个向量越相似;越接近 -1,表示越不相似;接近 0 则表示两者相关性较低。
- MLP 网络:将 Query 和 Key 拼接或分别输入到一个多层感知机网络中,通过网络的运算输出一个数值作为注意力得分。这种方式可以学习到更复杂的 Query 和 Key 之间的关系模式。
- 点积运算:假设 Query 向量为
- 阶段二:缩放与 Softmax 处理:得到注意力得分后,为了更好地调整得分分布并突出重要信息的权重,我们会进行缩放(scale)操作,通常是将注意力得分除以维度
的平方根,即
。 缩放操作有助于避免在计算 Softmax 时,因得分值过大导致 Softmax 函数梯度消失等问题。
接着,我们对缩放后的得分应用 Softmax 函数,公式为
,
其中 n 是 Key 的数量。Softmax 函数有两个重要作用:一方面,它对原始的计算分值进行归一化处理,使得所有元素的权重之和为 1,将其整理成一个概率分布,这样每个权重值都可以看作是对应 Value 被选中的概率;另一方面,通过 Softmax 函数的指数运算和归一化特性,能够更加突出得分较高(即更重要)元素的权重,相对弱化得分较低元素的权重。
4. 阶段三:加权求和:在得到注意力权重后,我们根据这些权重系数对 Value 值进行加权求和,从而得到最终的 Attention Value。假设 Value 向量为 ,注意力权重为:
,
那么 Attention Value 的计算公式为:
。
经过这个步骤,生成的 Attention Value 包含了注意力信息,模型对更重要的信息给予了更高的权重关注,而相对不重要的信息则在加权求和过程中被适当弱化,从而实现了对关键信息的聚焦和筛选。
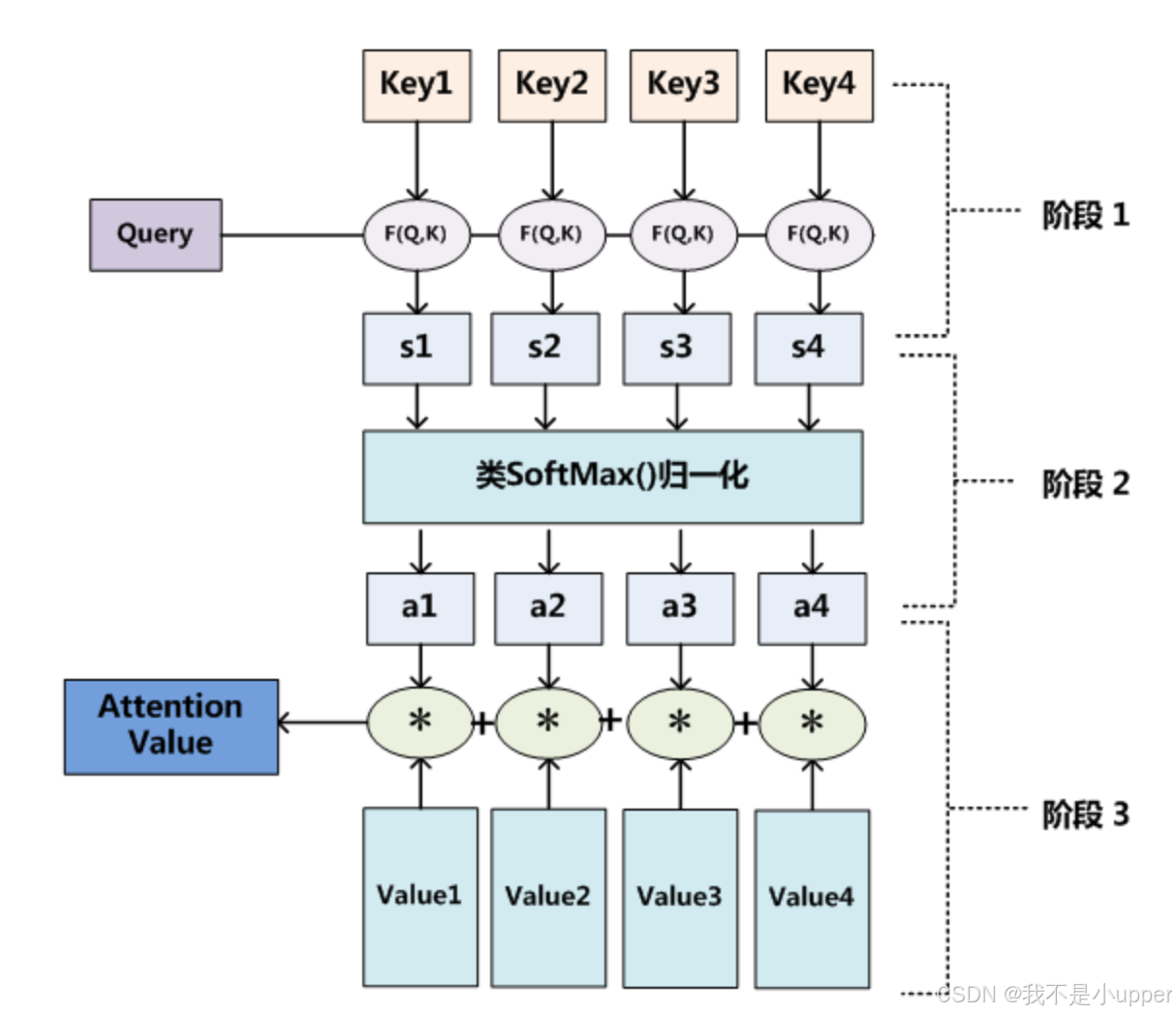
这三个阶段紧密相连,共同构成了注意力机制从输入数据到输出关键信息的完整计算过程,使得模型能够像人类一样,在大量的数据中捕捉和利用最重要的信息。
二、自注意力机制:Self-Attention
2.1 什么是自注意力机制?
在深度学习领域,当我们处理诸如文本、图像等数据时,数据往往被表示为多个大小各异的向量。以文本为例,每个单词都可以被编码成一个向量,这些向量之间存在着复杂的语义关系;在图像中,不同区域对应的向量也蕴含着空间和内容关联。然而,传统的全连接神经网络在处理这些相关输入时,难以充分挖掘和利用向量之间的内在联系,导致模型训练效果不佳,无法准确捕捉数据的关键特征和模式。
自注意力机制正是为了解决这一问题而诞生的。它是注意力机制的一种特殊变体,同时也是一种独特的网络架构设计。其核心目标是让模型能够自动关注输入数据内部不同部分之间的相关性,从而更好地理解数据的整体结构和语义信息。
在自注意力机制中,有一个关键特点:查询(Query)、键(Key)和值(Value)这三个重要元素,要么完全相同,要么都来源于同一个输入数据 ,我们记为X。也就是说,自注意力机制是从输入数据X自身出发,去寻找其中的关键信息,聚焦重要部分,弱化不重要的部分。它与一般注意力机制不同,不是在输入和输出数据之间建立注意力关系,而是在输入数据内部元素之间,或者输出数据内部元素之间进行注意力计算 。
我们可以通过与一般注意力机制对比,更清晰地理解自注意力机制的特点:
- 一般注意力机制:在常见的 Encoder-Decoder 模型(比如机器翻译模型)中,查询(Q)和键(K)来自不同的地方。以中译英模型为例,中文句子经过编码器(Encoder)处理后,转化为一组包含语义信息的特征表示,这些就是键(K);而解码器(Decoder)在生成英文句子的过程中,会根据当前生成的英文单词生成对应的特征表示,作为查询(Q)。模型通过 Q 和 K 的交互,决定下一个要生成的英文单词,即注意力机制建立在输入(中文句子)和输出(英文句子生成过程)之间 。
- 自注意力机制:查询(Q)和键(K)都来自同一组元素。同样在 Encoder-Decoder 模型中,在编码器(Encoder)处理中文句子时,自注意力机制会让中文句子内部的各个词向量(即同一组元素)之间相互计算注意力。比如在处理 “我爱中国” 这句话时,自注意力机制会计算 “我”“爱”“中国” 这些词向量之间的相关性,挖掘句子内部的语义联系。在图像领域,也可以理解为同一张图像中不同图像块(patch)之间相互进行注意力计算 。因此,自注意力机制也被称为内部注意力机制。
2.2 如何运用自注意力机制?
自注意力机制的计算步骤与一般注意力机制类似,但由于其 Q、K、V 的特殊来源,在具体应用中有自身特点,具体过程如下:
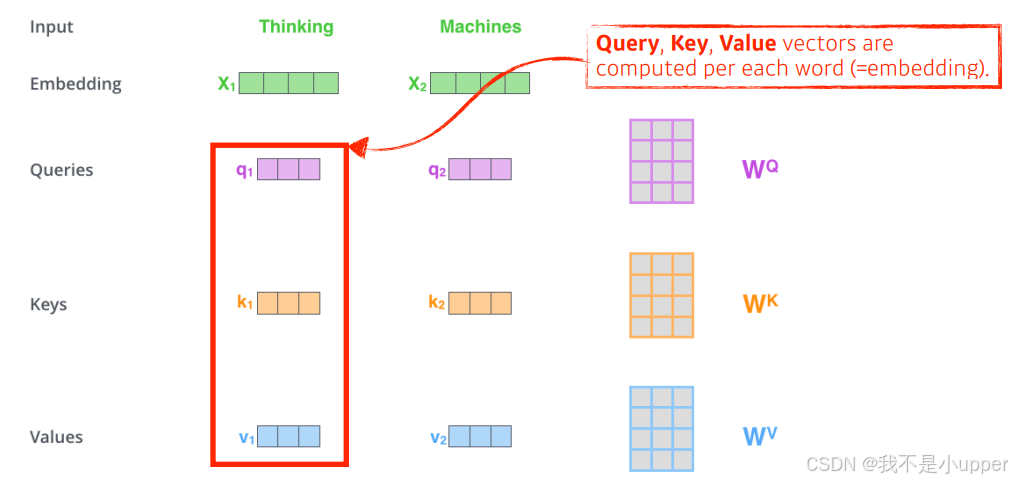
第 1 步:得到 Q,K,V 的值
假设我们的输入数据是一组向量,其中
代表第i个向量,n是向量的总数。对于每一个向量
,我们分别让它与三个可学习的权重矩阵
、
、
相乘 ,得到对应的查询(Query)、键(Key)和值(Value)向量:
这里的、
、
是我们需要通过模型训练学习得到的参数矩阵,d是输入向量
的维度,
和
分别是查询(Q)、键(K)和值(V)向量的维度。通过这样的矩阵乘法运算,我们为每个输入向量生成了对应的 Q、K、V 表示 。
第 2 步:Matmul
得到 Q 和 K 后,我们需要计算每两个输入向量之间的相关性,通常使用点积运算来计算每个向量的得分(score) :
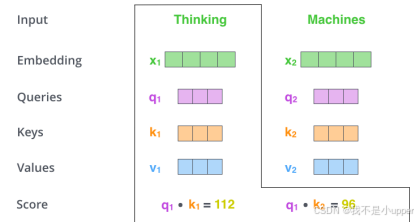
这里的表示第i个向量的查询
与第j个向量的键
之间的相关性得分。通过这种方式,我们可以得到一个
的得分矩阵,矩阵中的每一个元素都反映了两个输入向量之间的关联程度 。
第 3 步:Scale+Softmax
为了避免点积运算后得分值过大,导致 Softmax 函数梯度消失等问题,我们对得到的得分进行缩放(Scale)操作。具体是将得分除以,
是键(K)向量的维度 :
然后,对缩放后的得分应用 Softmax 函数,将其转化为概率分布形式的权重系数:

经过 Softmax 处理后,每个的值都介于 0 到 1 之间,且对于每一行i,所有列的
之和为 1。这些权重系数表示了第i个向量对其他各个向量的关注程度 。
第 4 步:Matmul
最后,我们使用得到的权重矩阵与值(V)向量进行加权求和运算。对于每个向量,其经过自注意力机制后的输出
计算如下:
通过这个加权求和过程,每个输出向量都融合了输入数据中所有向量的信息,并且根据计算得到的注意力权重,重点关注了与自身相关性更高的向量信息 。
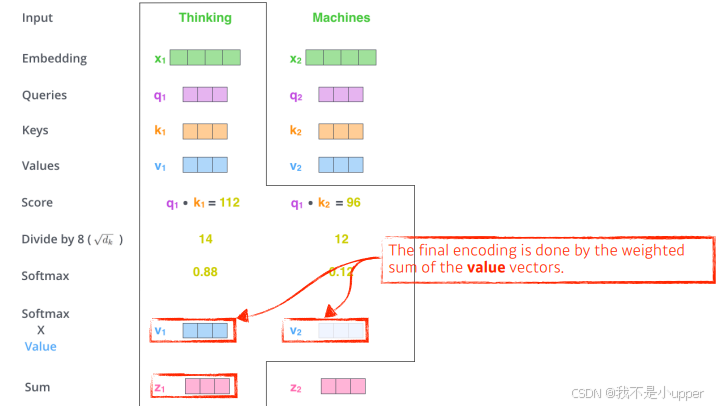
以 “Thinking Machines” 这句话为例,经过上述自注意力机制的计算过程,我们会得到两个新向量和
,分别对应 “Thinking” 和 “Machines” 这两个词的新向量表示。其中
虽然依然是 “Thinking” 的词向量,但它不再仅仅是原始的词向量,而是融入了 “Thinking Machines” 这句话中各个单词与 “Thinking” 的相关性信息,突出了在整个句子语境下与 “Thinking” 相关的重要内容 。
2.3 自注意力机制的问题
尽管自注意力机制在捕捉数据内部相关性方面表现出色,但它也存在一些局限性:
- 有效信息抓取能力:自注意力机制的核心是筛选输入数据中的重要信息,过滤不重要信息。然而,相比卷积神经网络(CNN),它在利用数据的先验结构信息方面存在不足。例如在图像数据中,CNN 能够天然利用图像的尺度不变性(图像缩放后语义不变)、平移不变性(图像平移后特征不变),以及图像的特征局部性(相邻图像区域往往具有相似特征,同一物体的信息集中在局部)等特性 。而自注意力机制缺乏这种对数据结构的内置理解,只能依赖大量数据进行学习来发现规律。因此,在数据量较小的情况下,自注意力机制难以建立准确的全局关系,其性能往往不如 CNN;只有在大数据支撑下,它才能充分发挥捕捉长距离依赖关系的优势 。
- 位置信息利用:自注意力机制在计算过程中,平等地考虑了所有输入向量,没有显式地引入向量的位置信息 。但在实际应用中,特别是文字处理问题里,词语在句子中的位置至关重要。比如在自然语言中,动词通常很少出现在句首,名词在不同位置可能有不同的语法和语义角色。由于自注意力机制没有内置的位置信息处理方式,如果不额外进行位置编码(如在 Transformer 中加入位置编码向量),模型就无法区分相同词语在不同位置的差异,可能影响对数据语义的准确理解 。
三、多头注意力机制:Multi-Head Self-Attention
通过前面的学习,我们知道自注意力机制存在一定缺陷。在对数据进行处理时,模型在编码某个位置的信息时,往往会过度聚焦于该位置自身,导致在抓取有效信息方面能力不足,尤其难以全面捕捉数据中不同距离的依赖关系,比如句子中相隔较远词汇间的语义关联。为了解决这些问题,多头注意力机制应运而生,并且在实际应用中被广泛使用。
3.1 什么是多头注意力机制?
在实际的深度学习任务中,当我们向模型输入相同的查询(Query)、键(Key)和值(Value)集合时,我们期望模型不仅仅以单一的方式处理这些数据,而是能够从多个角度去理解和学习数据的特征,进而学到不同的 “行为模式” 。这里所说的 “行为模式”,可以理解为模型关注数据不同方面、捕捉不同特征关系的方式。然后,把这些从不同角度学到的 “行为模式” 整合起来,就能够更全面地捕获数据序列内部各种范围的依赖关系,无论是近距离的词语搭配,还是远距离的语义呼应。
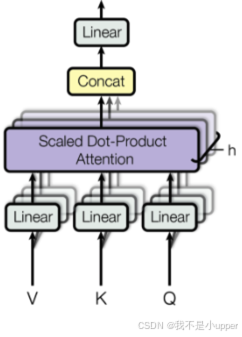
为了实现这一目标,多头注意力机制采用了一种巧妙的设计思路:不再仅仅使用一组查询、键和值进行单一的注意力汇聚计算,而是通过独立学习得到的h组(在实际应用中,通常将h设置为 8)不同的线性投影矩阵,对输入的查询、键和值进行变换 。每一组线性投影矩阵都会将原始的查询、键和值映射到不同的子空间中,得到h组不同的查询、键和值表示。这h组变换后的查询、键和值会并行地进入各自的注意力汇聚模块进行计算 。计算完成后,将这h个注意力汇聚的输出结果拼接在一起,再通过另一个可学习的线性投影矩阵进行变换,最终得到多头注意力机制的输出。这种设计就像让多个 “专家” 从不同角度去分析数据,然后把他们的分析结果整合起来,从而更全面地理解数据的内在信息。
3.2 如何运用多头注意力机制?
第 1 步:定义多组W,生成多组 Q、K、V
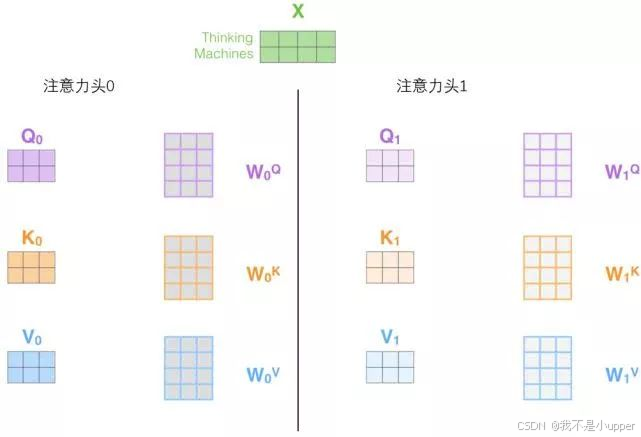
在自注意力机制中,我们知道查询(Q)、键(K)、值(V)是通过输入向量X分别与三个可训练的参数矩阵、
、
相乘得到的 ,具体公式为:
在多头注意力机制中,对于同样的输入向量X,我们定义h组不同的参数矩阵 。例如,对于第i组参数矩阵,分别记为、
、
。通过这h组不同的参数矩阵,分别与输入向量X进行矩阵乘法运算,就可以得到h组不同的查询(
)、键(
)和值(
):
这里的每一组参数矩阵都是独立学习的,它们会在模型训练过程中不断调整,从而让模型学到不同的特征表示和注意力计算方式。
第 2 步:定义 8 组参数
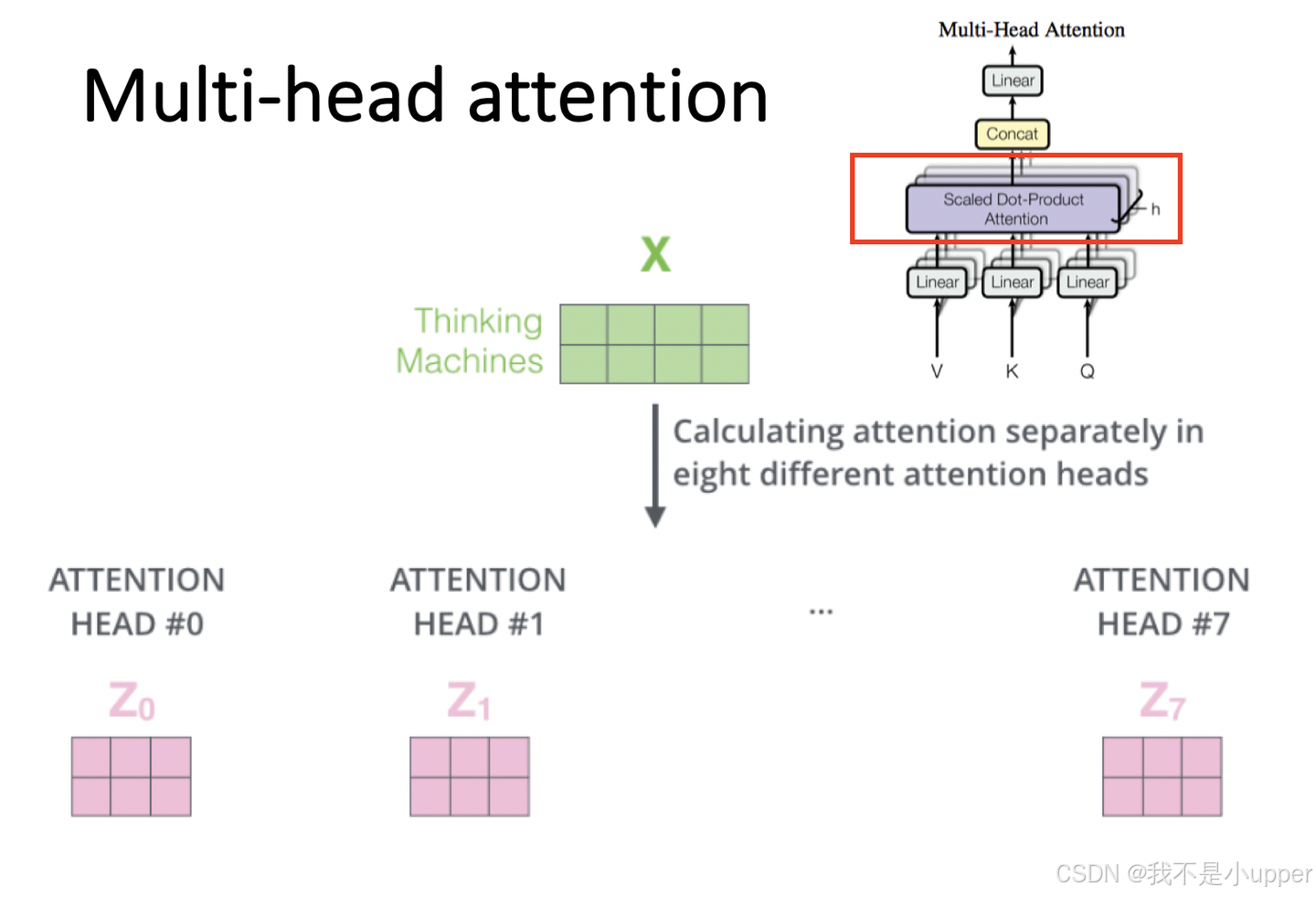
通常情况下,我们会设置,即对应 8 个 “单头”(single head)注意力机制 。对于这 8 组不同的查询(
)、键(
)和值(
),分别进行自注意力机制计算。根据自注意力机制的计算步骤,对于第i个单头,经过计算后会得到输出
。具体计算过程和自注意力机制相同,先计算
与
的相关性得分,经过缩放和 Softmax 处理得到注意力权重,再与
进行加权求和,即:
通过这样的计算,我们就得到了这 8 个单头注意力机制的输出结果。
第 3 步:将多组输出拼接后乘以矩阵以降低维度

在将多头注意力机制的输出传递到下一层网络之前,我们需要对这 8 个输出进行处理 。首先,将这 8 个输出沿着特定的维度(通常是特征维度)进行拼接(concat)操作,得到一个维度较大的张量。假设每个
的维度是d,那么拼接后的张量维度就是
。
然后,我们让这个拼接后的张量与一个可学习的线性投影矩阵相乘,进行一次线性变换 。这个线性变换的目的是对拼接后的特征进行整合和降维,得到最终的输出Z,公式为:
,
其中,
表示将进行拼接操作,
是一个维度合适的可训练参数矩阵,通过调整
的参数,模型可以学习到如何更好地整合这 8 个单头的输出信息,得到更具代表性的最终输出,用于后续的任务处理。
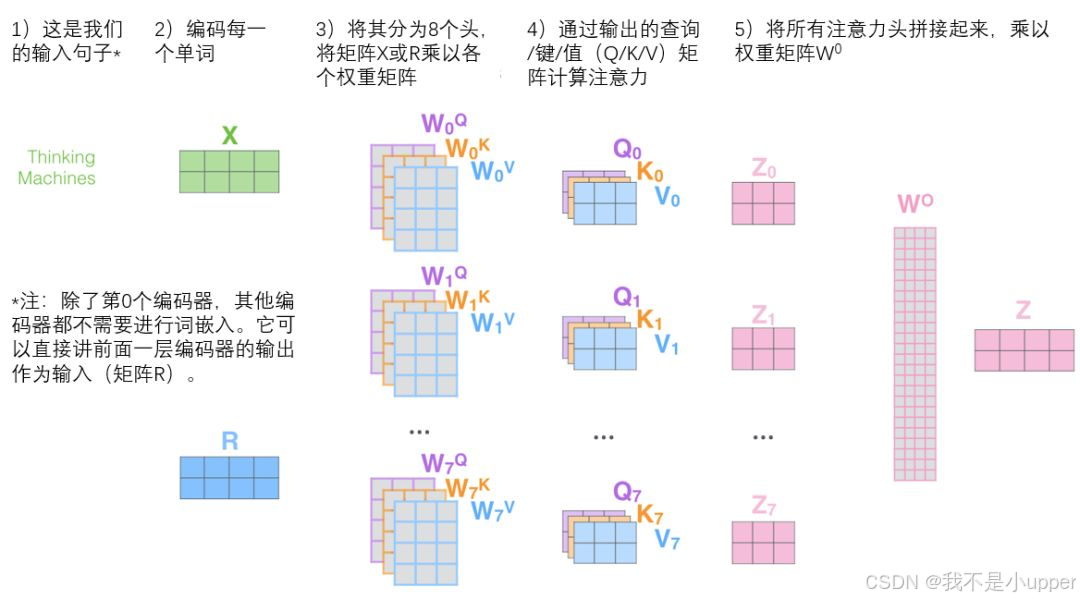
完整流程图如下:
四、通道注意力机制:Channel Attention
4.1 什么是通道注意力机制?
在利用卷积神经网络(CNN)处理二维图像时,图像数据存在两个重要维度。其中一个维度是图像的尺度空间,也就是我们直观看到的图像的长和宽,它决定了图像的大小和形状;另一个维度则是通道 ,比如常见的 RGB 图像包含红(Red)、绿(Green)、蓝(Blue)三个通道,每个通道记录着图像在对应颜色下的信息。通道注意力机制正是基于图像的通道维度发挥作用,并且在图像处理任务中应用十分广泛。
通道注意力机制的核心目标是明确地构建出图像不同通道之间的相关性。在图像中,各个通道所包含的信息对最终的任务(如图像分类、目标检测等)贡献程度是不同的。例如在识别猫的图像时,某些通道可能更多地包含猫的轮廓信息,而另一些通道可能侧重于猫的毛发颜色等细节信息 。通道注意力机制通过网络学习的方式,自动地评估每个特征通道的重要程度,为每个通道分配不同的权重系数 。对于包含关键信息、对任务更有帮助的通道,赋予更高的权重,使其在后续计算中得到强化;而对于那些包含次要信息或对当前任务帮助不大的通道,则赋予较低的权重,起到抑制作用。这样一来,模型就能更聚焦于重要的图像特征,从而提升对图像特征的表示能力,更好地完成各种视觉任务。
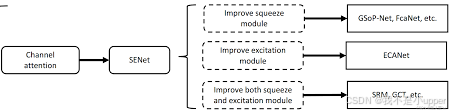
4.2 SENet
SENet(Squeeze-and-Excitation Networks,挤压激励网络)是通道注意力机制的经典实现,它在特征图的通道维度上引入了注意力机制,其核心操作包括 “挤压(squeeze)” 和 “激励(excitation)” 两个步骤 。
在图像经过一系列卷积等操作得到特征图后,SENet 通过构建一个额外的小型神经网络,来自动学习每个特征通道的重要程度。具体过程如下:
- 挤压(squeeze):在这一步骤中,针对输入的特征图,沿着空间维度(即长和宽方向)进行全局平均池化操作 。假设输入特征图的尺寸为\(H×W×C\)(H为高度,W为宽度,C为通道数),通过全局平均池化,将每个通道在空间维度上的信息压缩成一个数值,最终得到一个大小为\(1×1×C\)的向量 。这个向量可以看作是对整个特征图在每个通道上的全局信息的一种汇总,将空间维度的信息 “挤压” 到了通道维度上。
- 激励(excitation):得到\(1×1×C\)的向量后,通过两个全连接层组成的网络对其进行处理 。第一个全连接层将通道数从C降维到\(C/r\)(r为降维比例,是一个超参数),然后经过激活函数(如 ReLU)处理;接着进入第二个全连接层,将通道数从\(C/r\)恢复到C 。通过这两层全连接层的计算,输出一个大小同样为\(1×1×C\)的向量,这个向量中的每个元素代表了对应特征通道的重要程度。最后,将该向量与原始的特征图相乘,使得重要程度高的通道对应的特征得到增强,重要程度低的通道对应的特征被抑制 。
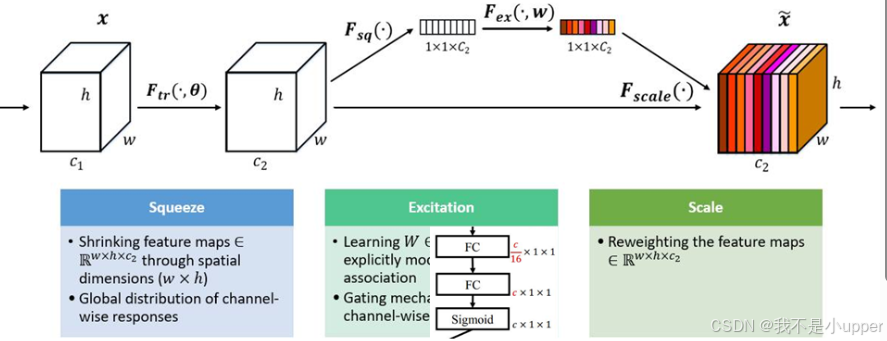
通过 SENet 的这种方式,神经网络能够重点关注那些对当前任务有用的特征通道,比如在图像分类任务中,突出与目标类别相关的图像特征,而抑制对任务帮助较小的特征通道,从而提升模型的性能。
4.3 ECA
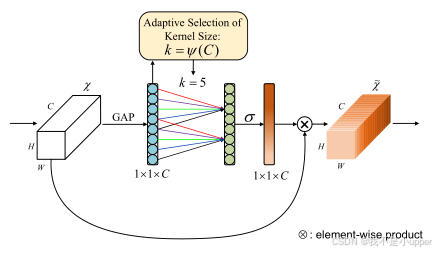
ECA(Efficient Channel Attention,高效通道注意力)机制也是一种应用于视觉模型的通道注意力机制,并且具有 “即插即用” 的特性 。也就是说,在不改变输入特征图尺寸的前提下,它能够增强输入特征图的通道特征,方便地集成到各种视觉模型中。
ECA 机制的出现源于对 SENet 的改进。ECA-Net 研究发现,SENet 中采用的降维操作会影响通道注意力的预测准确性,并且在获取所有通道的依赖关系时,这种方式效率较低,也并非必要 。基于此,ECA 机制进行了针对性的设计: 在 SENet 使用全连接层学习通道注意信息的基础上,ECA 机制将其替换为 1×1 卷积 。1×1 卷积在神经网络中可以看作是一种特殊的线性变换,它能够在不改变特征图空间尺寸的情况下,对通道维度进行操作 。通过 1×1 卷积,ECA 机制可以捕获不同通道之间的信息交互,同时避免了像 SENet 那样因降维操作导致的信息损失,而且 1×1 卷积的参数量相对全连接层要小得多 。这不仅减少了模型的计算量和参数数量,提高了计算效率,还能更有效地学习通道注意力信息,使得模型在处理图像时能够更精准地聚焦于重要通道特征。
4.4 CBAM
CBAM(Convolutional Block Attention Module,卷积块注意力模块)是一种简单而有效的前馈卷积神经网络注意力模块 。它将传统的通道注意力机制与空间注意力机制相结合,实现了通道(channel)和空间(spatial)维度上的统一关注。
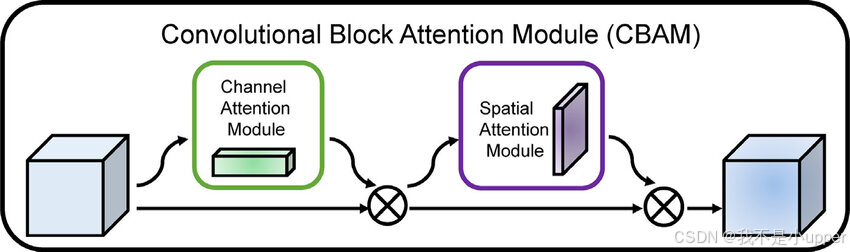
CBAM 的具体操作流程如下:对于给定的中间特征图,该模块会按照顺序,在通道和空间这两个独立的维度上分别生成注意力图 。
- 通道注意力计算:首先,在通道维度上,类似于 SENet 等通道注意力机制的操作,通过全局平均池化和全局最大池化等操作,分别获取特征图在通道维度上的全局信息,然后经过全连接层等网络结构处理,计算出每个通道的重要程度,生成通道注意力图 。这个过程能够让模型关注到哪些通道包含更重要的信息。
- 空间注意力计算:在得到通道注意力图后,将其与原始特征图相乘,得到经过通道注意力调整后的特征图 。接着,在空间维度上,对该特征图进行基于卷积等操作,通过平均池化和最大池化操作,获取特征图在空间位置上的信息,再经过卷积层等处理,生成空间注意力图 。空间注意力图能够让模型关注到图像中哪些空间位置的信息更重要。
- 特征修饰:最后,将空间注意力图与经过通道注意力调整后的特征图相乘,得到经过自适应特征修饰后的最终特征图 。由于 CBAM 结构简单、计算开销小,因此可以轻松地集成到任何 CNN 架构中,并且能够与基础 CNN 模型一起进行端到端的训练,在不显著增加模型复杂度的情况下,提升模型对图像特征的提取和处理能力,从而提高模型在各种视觉任务中的性能。
五、空间注意力机制:Spatial Attention
5.1 什么是空间注意力机制?
在前面介绍的内容中,我们看到的图里就包含了空间注意力机制(例如,绿色长条代表通道注意力机制,而紫色平面则表示空间注意力机制)。在处理图像的任务中,图像的不同区域对于完成任务的贡献程度是不一样的。比如在图像分类任务中,图像里的主体部分(如识别猫的任务中,猫的图像部分)对确定图像类别起着关键作用,而背景等其他区域的重要性相对较低。空间注意力模型的核心任务就是找出图像中对于当前任务最重要的部位,并对这些部位进行重点处理。
从本质上讲,空间注意力机制的目的是提升图像中关键区域的特征表达能力。它通过一个空间转换模块来对原始图像的空间信息进行处理,将图像从原始空间变换到另一个空间。在这个过程中,它会为图像的每个位置生成一个权重掩膜(mask)。权重掩膜中的值表示图像各个位置的重要程度,值越大说明该位置越重要。然后,根据这些权重对图像进行加权输出,增强与任务相关的特定目标区域(如目标物体所在区域)的特征,同时弱化不相关的背景区域的特征,从而使模型能够更专注于关键信息,提升模型在视觉任务中的表现。
5.2 STN
在 2015 年 NIPS(神经信息处理系统大会,Neural Information Processing Systems)上发表的论文中,提出了空间变换器网络(Spatial Transformer Networks,简称 STN),并引入了空间变换器(Spatial Transformer)的概念。STN 的核心是让模型具备空间不变性,即无论目标物体在图像中的位置、旋转角度或缩放比例如何变化,模型都能有效地识别和处理。
STN 是一个可微分的模块,它可以方便地插入到现有的卷积神经网络结构中,并且不需要对神经网络的训练监督方式或优化过程进行额外修改,就能使神经网络自动地根据特征图(Feature Map)的情况对特征进行空间变换。它的主要作用是准确找到图片中需要被关注的区域,并对这些区域进行旋转、缩放等操作,最终提取出固定大小的区域,以便后续的处理。
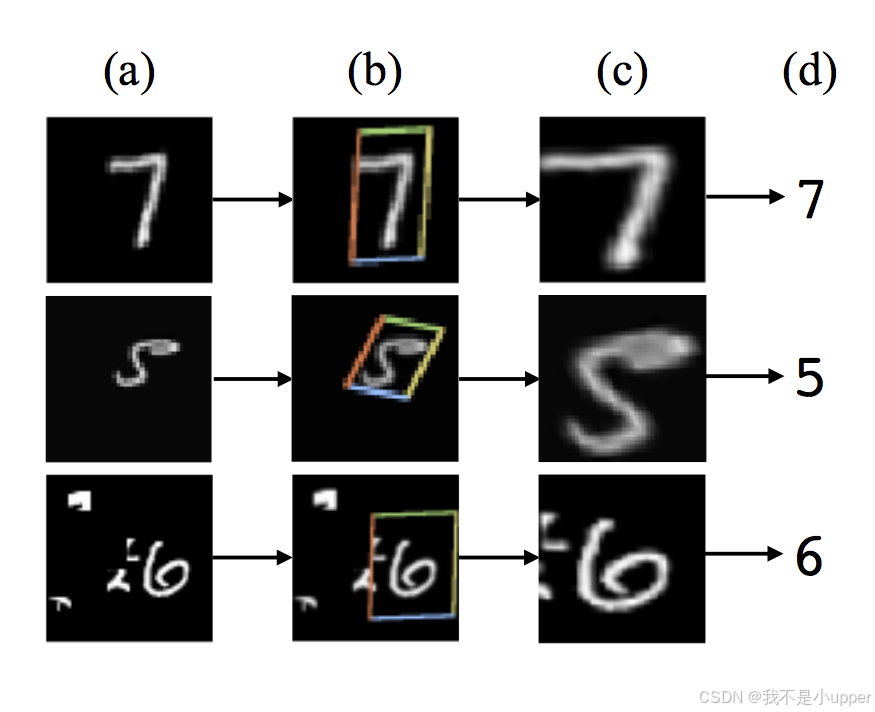
空间采样器作为 STN 的重要组成部分,其实现主要分为以下三个部分:
- 局部网络(Localisation Network):局部网络的作用是对输入的特征图进行分析,计算出空间变换所需的参数。它接收特征图作为输入,通过一系列的卷积、全连接等操作,输出空间变换的参数(如旋转角度、缩放比例、平移量等)。这些参数用于描述如何对特征图进行空间变换,以突出关键区域。例如,在处理包含目标物体的图像时,局部网络会根据目标物体在特征图中的位置和特征,计算出能够将目标物体变换到合适位置和大小的参数。
- 参数化网格采样 (Parameterised Sampling Grid):在得到空间变换参数后,参数化网格采样模块根据这些参数生成一个采样网格。采样网格定义了如何在原始特征图上进行采样,以实现空间变换。它会根据变换参数对原始特征图进行划分,确定每个位置的新坐标。例如,当需要对图像进行旋转时,采样网格会计算出旋转后每个位置在原始图像中的对应位置,从而实现对特征图的旋转操作。
- 差分图像采样(Differentiable Image Sampling):差分图像采样模块根据参数化网格采样生成的采样网格,对原始特征图进行采样操作。它会根据采样网格的坐标信息,从原始特征图中提取相应的特征,并将这些特征映射到新的空间位置上。这个过程是可微分的,使得在训练过程中可以通过反向传播来优化空间变换的参数,从而让模型能够学习到最佳的空间变换方式。例如,在目标检测任务中,差分图像采样会根据采样网格提取出目标物体的特征,并将其变换到合适的位置和大小,以便后续的检测和识别。

)


)






系统)




)

基于opencv实现调用摄像头并实时显示画面)
)