一、摘要
本文介绍2024年12月字节跳动牵头发表的大模型论文《ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning》。论文提出了 ChatTS 模型,用合成数据提升对时间序列的理解和推理能力。作者在纽约出租车乘客数量、广告 CPC 数据、交通占用率等真实数据上进行案例研究,ChatTS 能准确分析形状、统计特征和识别异常波动。在数据库操作和 Twitter 话题讨论强度分析等实际应用中,ChatTS 也展现了强大的分析和推理能力。

译文:
理解时间序列对于其在现实场景中的应用至关重要。最近,大语言模型(LLMs)越来越多地应用于时间序列任务,利用其强大的语言能力来增强各种应用。然而,针对时间序列理解与推理的多模态大语言模型(MLLMs)的研究仍然有限,这主要是由于缺乏能将时间序列与文本信息对齐的高质量数据集。本文介绍了ChatTS,这是一种专为时间序列分析设计的新型多模态大语言模型。ChatTS将时间序列视为一种模态,类似于视觉多模态大语言模型处理图像的方式,使其能够对时间序列进行理解和推理。为了解决训练数据稀缺的问题,我们提出了一种基于属性的方法,用于生成带有详细属性描述的合成时间序列。我们进一步引入了时间序列进化指令(Time Series Evol-Instruct),这是一种生成多样化时间序列问答的新方法,可增强模型的推理能力。据我们所知,ChatTS是首个将多变量时间序列作为输入进行理解和推理的时间序列多模态大语言模型,并且它仅在合成数据集上进行了微调。我们使用包含真实世界数据的基准数据集评估其性能,包括六项对齐任务和四项推理任务。结果表明,ChatTS显著优于现有的基于视觉的多模态大语言模型(如GPT - 4o)以及基于文本/智能体的大语言模型,在对齐任务中提升了46.0%,在推理任务中提升了25.8%。
二、核心创新点
1、总览
由于高质量的将时间序列与文本信息对齐的数据集稀缺,作者选择了生成合成的文本-时间序列对来进行模型的训练。然而,用于时间序列-多模态大模型的数据需要有足够的准确率,且能够全面涵盖时间序列属性以及具有足够的任务多样性。为了实现这一目标,作者提出了一种基于属性的方法来生成时间序列+文本数据:
- 属性选择器:为了生成具有精确属性且高度可控的时间序列数据,作者使用详细的特征集来描述时间序列。通过大模型选择,这些属性与现实世界的设置保持一致。
- 基于属性的时间序列生成器:使用基于规则的方法构建与属性池完全对应的时间序列。
- 时间序列进化指令:一种新颖的时间序列锦华化指令模块,用于创建大规模、多样化且准确的时间序列与文本问答对数据集,以支持复杂推理。
- 模型设计:为处理多时间序列,作者设计了一种针对多时间序列输入的上下文感知多模态大模型编码,以及一种保值时间序列编码方法。
- 模型训练:进行大规模训练和监督微调,以实现语言对齐并提高与时间序列相关的推理能力。
2、基于属性的时间序列生成器(attribute-based time series generator)
多样的时间序列以及精确、详细的文本属性描述对于实现准确的时间序列-语言对齐至关重要。作者将时间序列属性分为四大类:趋势、周期性、噪声和局部波动,以构建相应的时间序列属性集。
基于此,作者提出了一种属性选择器和基于属性的时间序列生成器,用于生成合成的时间序列数据。首先,作者定义一个“全属性集”,它包括不同属性类别下的许多特定属性。全属性集包括4种趋势类型、7种季节性类型、3种噪声类型和19种局部波动类型。同一类别中的不同属性可以组合。通过组合相同类型的属性,一个时间序列可以包括多个趋势段和几个局部波动。此外,通过组合正弦波,可以生成各种各样的周期性波动模式。因此,所提出的时间序列生成器理论上可以生成无限数量的不同时间序列,确保了属性的丰富性。
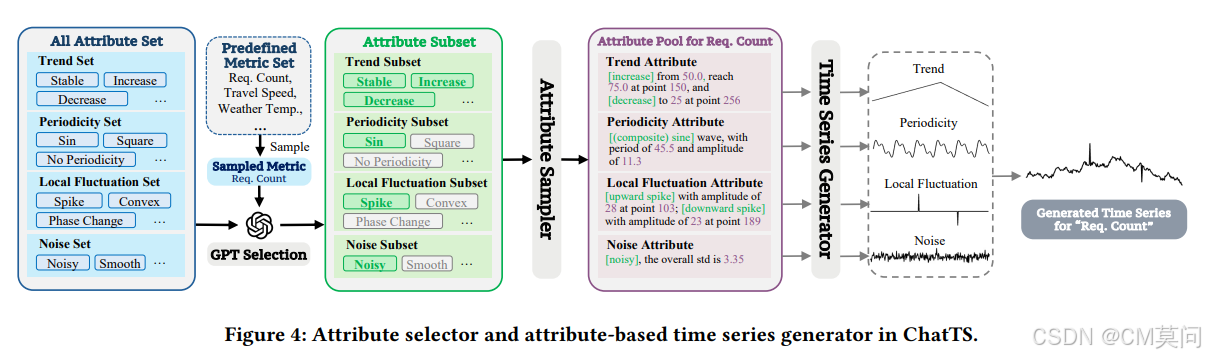
作者还引入了一个GPT选择器。具体来说,在为时间序列生成属性集时,从一个包含567个来自实际场景的预定义指标名称的大型“指标集”中随机采样一个指标,并根据该指标的实际物理意义和预定义场景,使用GPT从全属性集中选择一个属性子集。这有助于使时间序列与实际物理意义保持一致。
然后,属性采样器从属性子集中随机采样属性组合。它还根据GPT选择器的规则和约束分配特定的数值,如位置和幅度。这些细节存储在“属性池”中,该池记录了关于时间序列的所有详细信息。时间序列生成器最终以基于规则的方式创建与属性池中的属性完全匹配的时间序列数组。这个过程使我们能够生成具有精确属性描述的多样化合成时间序列。
3、时间序列进化指令设计(time series evol-instruct)
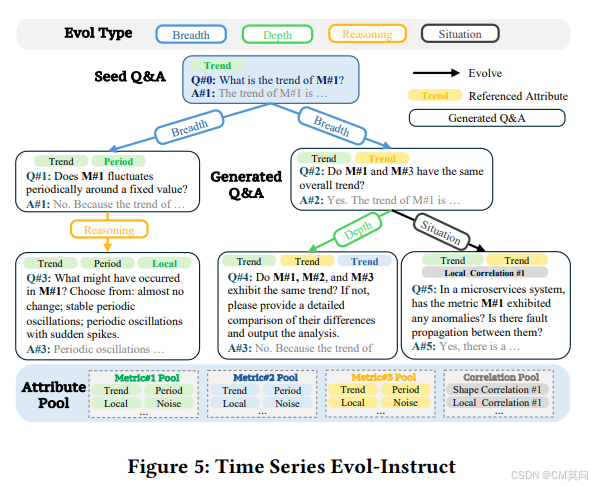
为了提升模型的问答和推理能力,拥有格式和任务多样的高质量监督微调训练数据至关重要。然而,由于缺乏时间序列+文本数据,直接获取足够多样的与时间序列相关的训练数据具有较大挑战。为了生成具有丰富问答格式的准确时间序列+文本监督微调数据,作者提出了时间序列的Evol-Instruct。
该方法通过逐步evolve指令prompt及其输出,来提高大模型训练数据的多样性和复杂度。为了增强模型分析相关性的能力,作者引入了一个相关性池,记录具有相关属性的时间序列。在evolve的每一步中,从属性池中随机选择一个属性子集,并将其作为额外的上下文添加,引导大模型根据演化类型生成关于更广泛的时间序列属性的问答。
4、时间序列多模态LLM
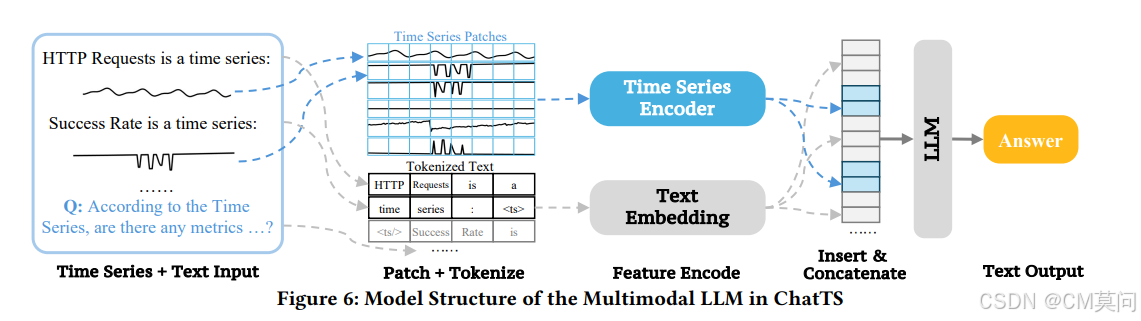
为了处理多模态输入,ChatTS首先将输入的时间序列数组与文本分离。输入的时间序列数组被划分为固定大小的块,这使得模型能够更有效地处理和编码时间模式。由于时间序列本质上具有顺序模式,作者采用一个简单的5层MLP对时间序列的每个块进行编码。对于文本输入,先对其进行标记化处理,然后通过文本嵌入层进行编码。通过这种方式,时间序列的每个块和每个文本标记都被映射到同一空间。
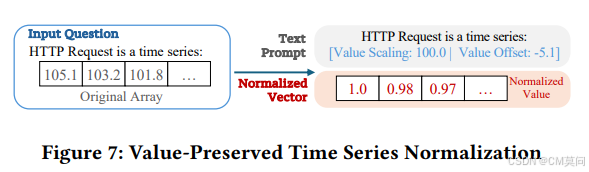
为了充分保留多元时间序列的上下文信息,作者基于时间序列在原始输入中的位置进行了词元级别的拼接。具体来说,将每个时间序列对应的编码片段插入到周围文本词元之间。然后,这个序列会被输入到LLM中。传统的时间序列数据归一化会导致原始数值信息的丢失。为了解决这个问题,作者提出了一种保值时间序列归一化框架。首先,对每个时间序列使用标准的最大-最小值归一化,然后对每个时间序列引入一个“Value Scaling”和“Value Offset”参数,作为prompt的一部分。这样可以利用大模型的数值理解能力,使得能够在保留原始数值信息的同时对时间序列特征进行归一化。
5、模型训练
第一阶段是大规模对齐训练。作者使用基于属性的合成序列数据进行大规模对齐,以在大模型内建立文本与时间序列模态之间的初始对齐。在对齐阶段,作者基于一系列人工设计的模板和大语言模型优化创建了三个数据集用于大规模训练。单变量时间序列(UTS)数据集包含单变量时间序列基本属性描述的任务(包括全局和局部属性任务)。多变量时间序列 - 形状(MTS-Shape)数据集由具有全局趋势相关性的多变量数据组成,旨在增强模型分析多变量相关性的能力。多变量时间序列 - 局部(MTS-Local)数据集包含具有相关局部波动的多变量数据,旨在提高模型分析多变量数据局部特征的能力。
第二阶段,作者使用监督微调(SFT)来提升大语言模型(LLM)执行复杂问答和推理任务的能力。此阶段利用两种主要类型的训练数据:一种是使用TSEvol生成的数据集,旨在增强模型对时间序列的问答和推理能力;另一种是指令跟随(IF)数据集,它基于一系列预定义模板构建,旨在增强模型遵循特定响应格式的能力。对于TSEvol,作者使用对齐训练中的数据集以及大语言模型生成的问答作为种子数据。这些数据集共同训练多模态大语言模型,使其能够准确回答特定于时间序列的查询并遵循任务指令,从而强化其执行复杂的、上下文驱动的问答和推理任务的能力。在对齐和监督微调两个阶段,作者通过一系列数值任务来增强ChatTS的数值处理能力。具体来说,作者明确训练模型学习各个方面的知识,例如最大值/最小值、分段平均值、局部特征(如峰值位置和幅度)、季节性和趋势幅度,以及各个时间点的原始数值。













(环境搭建))

)




