检索方向概述

数据检索领域技术选型大体分为SQL事务数据库、NoSQL数据库、分析型数据库三个类型。
SQL数据库的设计思路是采用关系模型组织数据,注重读写操作的一致性,注重数据的绝对安全。为了实现这一思路,SQL数据库往往会牺牲部分性能(尤其是写性能),来换取更好的事务性与稳定性。
分析型数据库的典型应用就是文本搜索,后来随着机器学习的发展,逐步扩展到向量检索领域。绝大部分分析型数据库的技术选型,保留SQL数据库对数据安全性的追求,采用适配块存储的数据结构存储数据。虽然ES通过一系列技术手段优化写性能,但在我看来并没有做出实质性突破。
NoSQL数据库基本就是我们常说的KV数据库。NoSQL之所以出现,是因为随着大数据时代到来,数据量的爆炸,SQL数据库分布式能力弱、存在性能瓶颈等问题逐渐暴露。NoSQL放弃了关系模型、事务性等能力,以此来换取高可扩展性和极致的性能。
扩展阅读:存储检索技术发展历史(1966 - 2021)
在介绍广告检索技术建设前,我们要先思考几个问题:
- 为什么我们不能直接用上述技术领域中的开源技术选型直接搭建我们的广告检索体系?
- 如果我们自建检索技术体系,放眼整个技术版图,我们的站位在哪里?
广告检索技术特点
大家可能会发现一个看似寻常的现象,就是国内那个比较大的互联网计算广告团队,几乎都会建设自己的检索内核,但是反观推荐、搜索团队,往往会基于一些开源的技术选型做个性化迭代(如ElasticSearch)。究其原因,要从广告业务的特点说起。
- 更新频繁,时效性要求高。
广告业务存在广告主实时行为,这一点是显著区别于推荐、搜索等业务的。推演到检索技术领域,其表象就是检索内核需要支持高频更新,且时效性一般要求在亚秒级。 - 无需保证外部一致性。
虽然上面对更新提出了很高的要求,但是广告场景也有要求比较宽松的地方,那就是并不要求满足外部一致性,而是仅需满足最终一致性。此外,一条记录内部(如一个计划内部)需要保证更新的原子性,不能出现同一条记录中的不同字段版本不一致的情况。 - 对系统工程指标要求极高。
广告业务对收入极其敏感,任何一点时延抖动、不稳定都可能带来很大的资损。因此广告系统往往极致的追求高吞吐、高性能、高可用。对应到检索的技术选型上,往往斥巨资选用纯内存存储。此外,在读写并发的基础上,需要完全消除性能毛刺,避免更新操作对读请求带来影响。 - 采用关系模型。
由于广告业务的复杂性,商家端往往将数据库划分为账户、计划、单元、创意、推广内容几个实体,以此来映射广告主的诉求模型。这些实体之间存在关联关系,因此本质上广告数据内部采用的是关系模型。这一点是显著区别于推荐、文档搜索等业务场景的。 - 需要应用倒排索引、向量索引。
广告的检索过程其实是一次倒排检索的过程。在这里,我将“向量检索”这个行为也抽象为一种模糊的倒排检索。这个严格来说并不是广告场景的特点。之所以在这里提及,是想说明广告场景不能简单的选用NoSQL数据库(如Redis)来满足上面的要求。
有了上面的分析,再回到这张图。我们来看看我们的发挥空间究竟是什么?
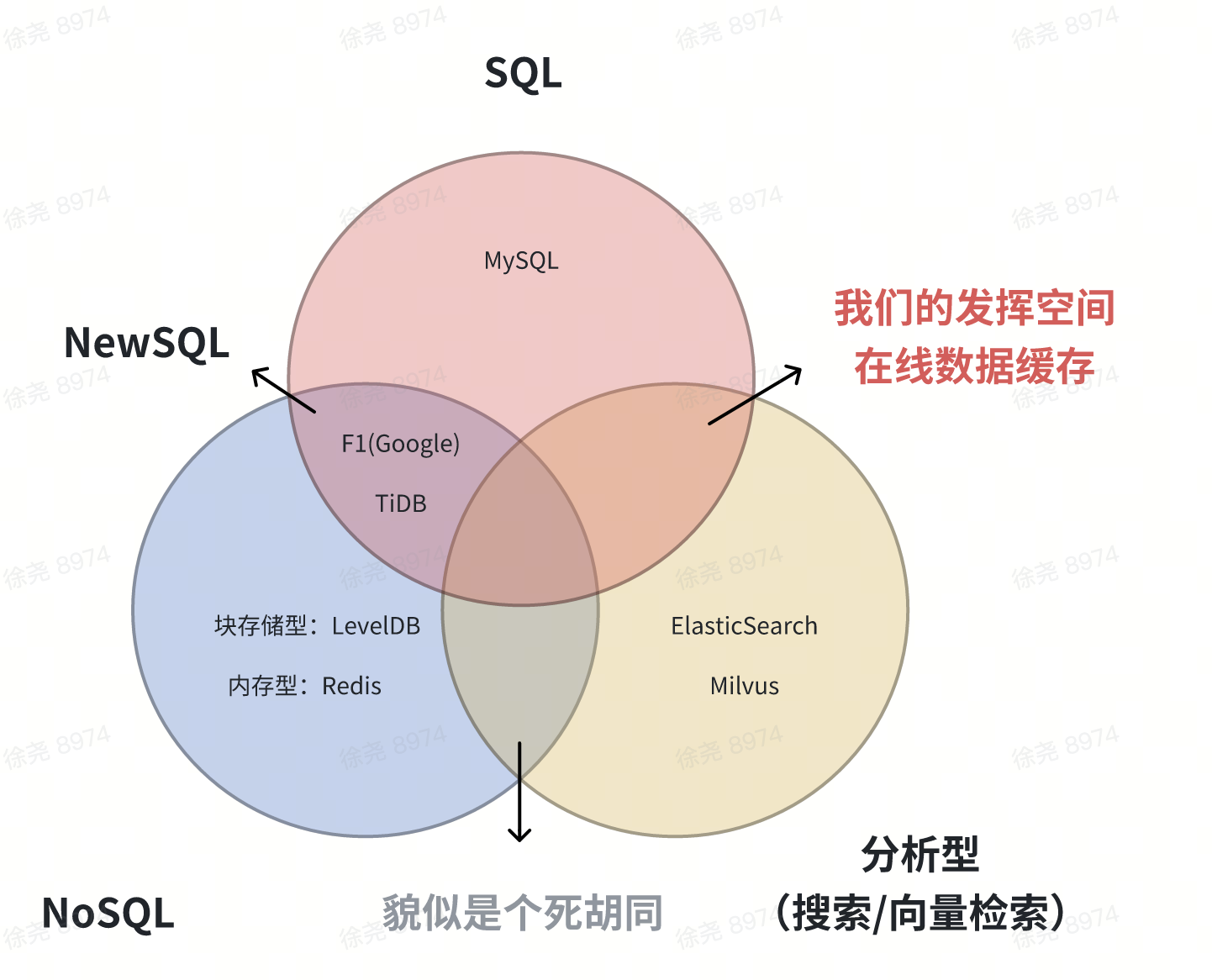
广告检索本质是一个在线数据缓存服务。说他是服务是相对于数据库而言的,他对持久化、事务性、一致性的要求都不高,反倒是对读写两端的性能要求极高。这个服务需要具备的一些核心feature主要有倒排检索、向量检索,同时还要求具备关系模型表达能力(类SQL)。
一点个人理念
- 系统是长出来的,不是设计出来的;长出来的系统,有概率掉进万丈深渊。
- 提效不是最终目标,目标的尽头是敏捷度;敏捷度指的是快速适应与高效纠偏。
- 不要小看上述两点,这都是要命的事!
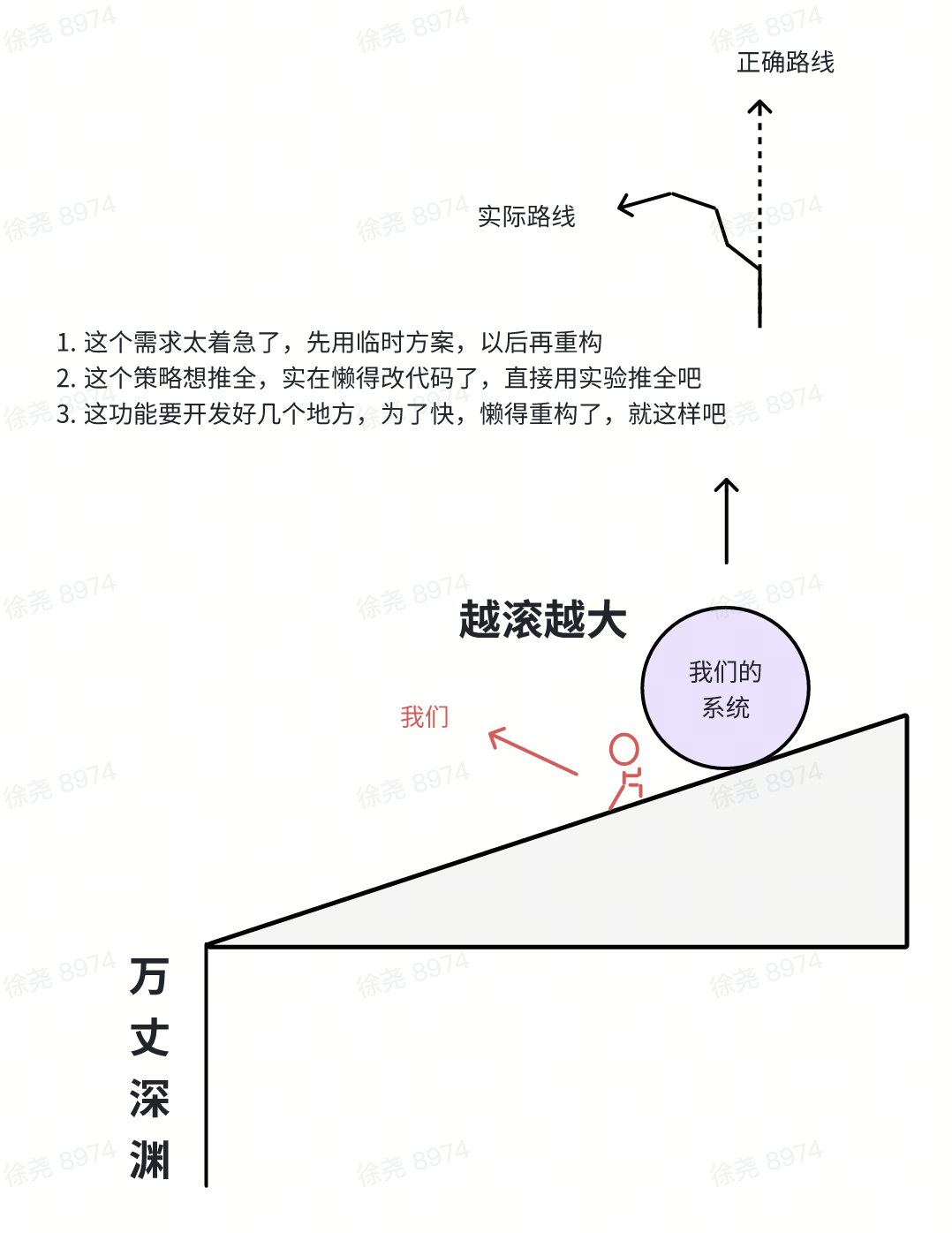
平台的本质是标准化,标准化的目的是:至少不要让路线偏离的太远。
检索平台
基于在线数据缓存服务这个定位,我们规划了函谷检索平台,目标是为广告库提供标准化、通用的检索能力支撑,快速定制业务检索服务,通过能力复用放大技术建设的杠杆作用。
召回平台 与 检索平台 的区别
在规划 检索平台 的时候,其实我们同时也做出了建设 召回平台 的设想。
检索平台专注于提升基础检索能力(如kv、倒排检索、向量检索等),同时对外屏蔽服务部署等细节,提供云原生的“数据表”缓存服务。召回平台更专注于对业务的召回环节进行抽象,提供多种通用的业务实体、召回插件、过滤插件供策略与产品同学选择,方便快速实现产品需求。
简单来说,检索平台更关注基础能力,召回平台更关注业务抽象。
理念
在建设检索平台的时候,我们明确了几个设计理念。
-
数据与查询的标准化
这个其实是老生常谈,建设任何平台都需要先标准化。这个地方不展开了。 -
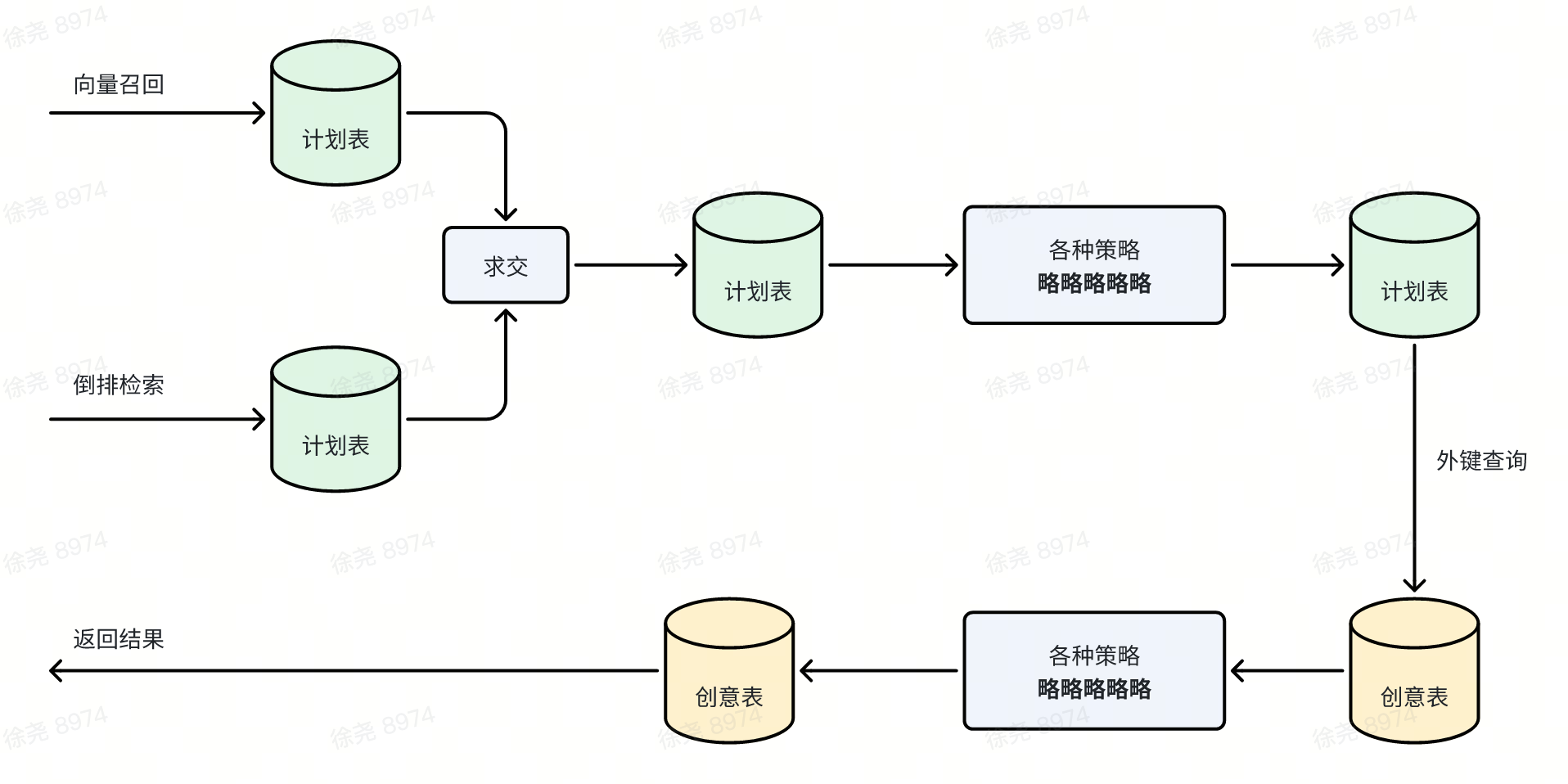
数据即业务
在这个地方,我们将整个检索流程抽象为“从一个数据转化为另一份数据的过程”。检索过程从一个表开始,查询到一些结果,然后对这些结果进行一定计算处理,利用计算结果再去查另一张表,如此往复,直到得到需要返回的数据表。如下图所示。
-
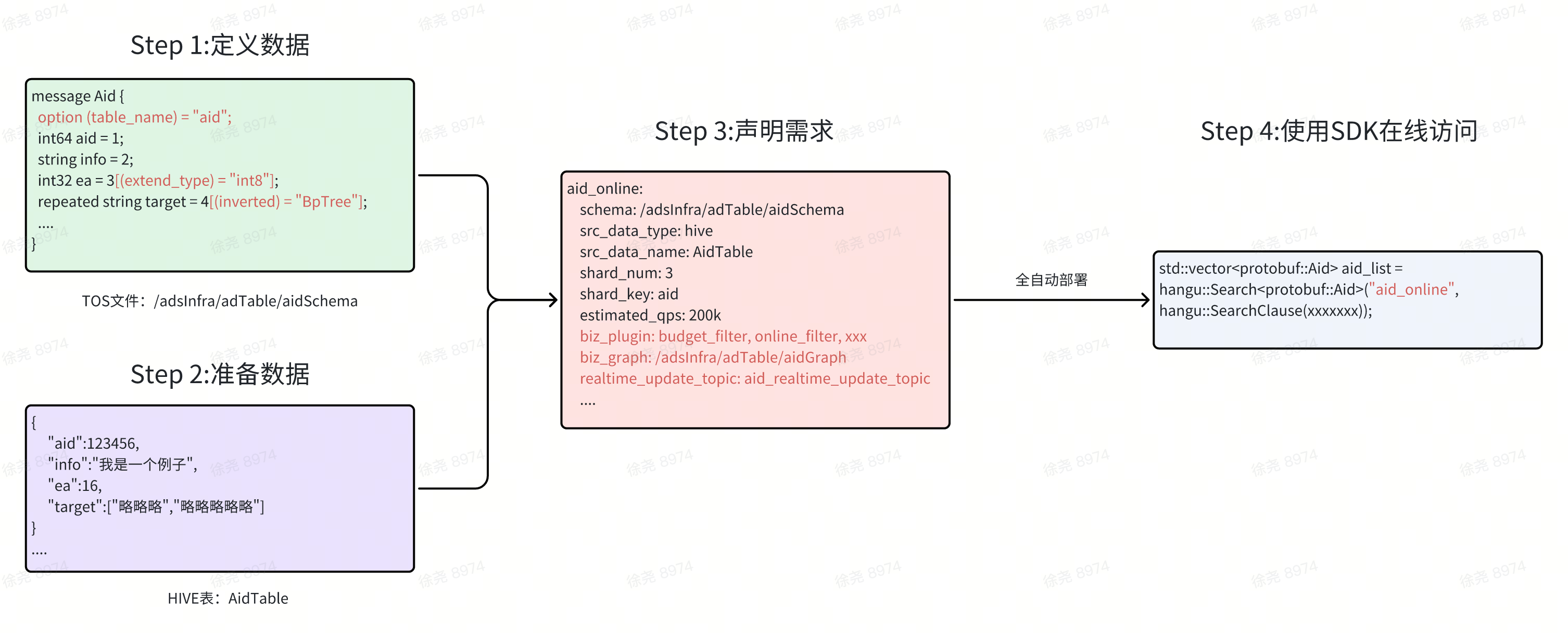
云原生
屏蔽服务部署等细节,提供云原生的“数据表”的声明式部署部署能力。例如,当一个业务方想部署一个计划表时,他只需要如下图操作。
-
支持扩展业务插件/业务图
原则上我们希望用类SQL的语言表达所有业务逻辑。但是考虑到业务的复杂性以及SQL可读性较差,我们还是提供了扩展插件的能力。如上图Step 3所示,插件会和数据表打包在一起部署到运行环境。
用户可以通过两种方式调用插件,一是在函谷SDK的标准化接口中通过插件名调用插件。二是直接将插件的执行顺序编写为一个“插件流”文件,并把文件部署到运行环境中,然后在函谷SDK的标准化接口中通过插件流的名字调用插件。 -
智能分级存储
在实际的应用场景中,一张表内的不同字段或不同行之间的的读取频率、性能要求、存储开销是不一样的。利用这个特性,我们很容易联想到操作系统中的三级缓存机制。那么这种缓存机制能否应用于我们的数据服务呢?我认为是可以的。我们可以采样真实请求与返回结果,根据一定策略智能的调整不同数据的存储介质(如磁盘、SSD、AEP、内存等),以此来满足业务对“资源-性能”兑换比的要求。
架构
![[图片]](https://i-blog.csdnimg.cn/direct/ec109d58a3f246a088f9df58c7cfc9eb.png)
Controller
Controller是整个函谷系统的对外网关,用户通过HTTP协议向Controller发送信令,来实现具体的业务诉求。常见的信令有新建数据表、删除数据表、查看数据列表、构建数据表、调整shard数量等。Controller接收到信令后,会在后端系统中触发一连串操作,并维护任务状态,确保信令正确执行。
HBuilder
在Controller接收到“构建数据表”信令后,会调用k8s接口拉起多个HBuilder实例(取决于信令中数据表的数量、shard数量等)。HBuilder负责从指定位置读取源数据,并构建全量数据。构建完成后,HBuilder会将数据上传到对象存储中,并销毁自己。
HKeeper
HKeeper是运行在在线服务机器上的Sidecar,负责与Controller配合,完成数据分发、数据版本控制、增量消息读入等功能。HKeeper还通过心跳定期上传在线服务状态,如内存负载、CPU负载等,为Controller进行扩所容、迁移等决策提供数据支持。
HWorker
HWorker是在线提供检索服务的进程,解析请求中的检索语法,拆解为对应的基础检索操作。HKernel是HWorker的底层检索内核。
HShark
HShark是插件开发脚手架自动生成工具,是为了提高业务开发插件的效率。
举例:
假设这个是业务方定义的schema文件。
// 使用hangu 2.4.0及以后的镜像,不需要包含addr、segment、snapshot、extension 这几个字段,之前的都需要。
syntax = "proto3"; // 必须
import "hangu/kernel_option.proto"; // 必须
package engine.doc; // package name, // package name + message name 就是 clazz。
message Poi {option (table_name) = "poi"; // tablename,和在函谷平台配置的一致。int64 poiId = 2;string poiInfo = 3;int64 addr = 10001;int64 segment = 10002;int64 snapshot = 10003;map<string, string> extension = 10004;
}message SecondNested {int64 addr = 10001;int64 segment = 10002;int64 snapshot = 10003;map<string, string> extension = 10004;repeated string varLenStringValues = 2;
}message FirstNested {int64 addr = 10001;int64 segment = 10002;int64 snapshot = 10003;map<string, string> extension = 10004;repeated SecondNested secondNested = 1;int32 singleInt8Value = 2[(extend_type) = "int8"];
}
下面是HShark自动生成的Wrapper类的示例。
![[图片]](https://i-blog.csdnimg.cn/direct/f98e62b283c14599bf778049e7bd77d6.png)
索引内核
HKernel是检索技术的核心,它是面向广告业务场景定制设计的基础检索组件。
理念
-
内核职能分层
检索内核承担了很多功能,比如管理存储IO、优化空间碎片、提供数据结构支持、管理数据对象等。这些功能之间是有明确的层级关系的。因此,在实现时,我们对内核进行了非常严格的分层,并且满足几个原则:(1)上层组件通过调用下层组件通用接口实现自身功能;(2)下层组件不允许调用上层组件;(3)同一层组件之间不允许相互调用。
![[图片]](https://i-blog.csdnimg.cn/direct/36753d83d7e0499ea703bdd2ab30cc9d.png)
-
技术参数配置化
可以通过配置的方式,指定某一张表的某一个索引的底层技术选型。如poi表的正排索引选型,可以指定为hash table,也可以指定为sort table。配置方式如下:
poi.forward.index=hashtable
poi.forward.pool.type=fixpool
- 向量检索与倒排检索统一
为了最大化地降低业务同学的认知成本,我们将向量索引与倒排索引进行了统一。具体来说,我们把对一张表的embedding建立向量索引的过程,看作是对这张表的embedding建立倒排索引。只不过这种索引是面向模糊检索,而非精准命中检索。
// 使用hangu 2.4.0及以后的镜像,不需要包含addr、segment、snapshot、extension 这几个字段,之前的都需要。
syntax = "proto3"; // 必须
import "hangu/kernel_option.proto"; // 必须
package engine.doc; // package name, // package name + message name 就是 clazz。
message Poi {option (table_name) = "poi"; // tablename,和在函谷平台配置的一致。int64 poiId = 2;string poiInfo = 3[(inverted) = "b+tree"];repeated float embedding = 4[(inverted) = "ivf-flat", (dim)="32", kernel="faiss"];int64 addr = 10001;int64 segment = 10002;int64 snapshot = 10003;map<string, string> extension = 10004;
}
设计
详见广告检索内核设计。

![[Linux_69] 数据链路层 | Mac帧格式 | 局域网转发 | MTU MSS](http://pic.xiahunao.cn/[Linux_69] 数据链路层 | Mac帧格式 | 局域网转发 | MTU MSS)


开发与综合案例)


![[250506] Auto-cpufreq 2.6 版本发布:带来增强的 TUI 监控及多项改进](http://pic.xiahunao.cn/[250506] Auto-cpufreq 2.6 版本发布:带来增强的 TUI 监控及多项改进)


指针的高级应用汇总)



初识n8n:工作流自动化平台概述)

 实现 MNIST 手写数字识别)


