目录
引言
1 Spark ThriftServer架构解析
1.1 核心组件与工作原理
1.2 与传统HiveServer2的对比
2 Spark ThriftServer部署指南
2.1 环境准备与启动流程
2.1.1 前置条件检查
2.1.2 服务启动流程
2.2 高可用部署方案
2.2.1 基于ZooKeeper的HA架构
3 性能优化实战
3.1 查询执行流程深度解析
3.2 核心参数调优
3.2.1 内存管理配置
3.2.2 并发控制参数
3.3 高级优化技巧
3.3.1 动态资源分配
3.3.2 数据倾斜处理方案
4 安全与权限管理
4.1 认证与授权体系
4.2 多租户资源隔离
4.2.1 基于YARN的隔离
4.2.2 Spark级别的隔离
5 监控与运维
5.1 关键监控指标
5.2 常见问题排查指南
6 总结
引言
在大数据生态系统中,Hive与Spark SQL的集成为企业提供了灵活多样的数据处理方案。本文将深入探讨"Spark on Hive"架构中的关键组件——Spark ThriftServer,详细解析其如何作为高效查询网关实现对Hive表的访问,并对比传统HiveServer2的性能优势。
1 Spark ThriftServer架构解析
1.1 核心组件与工作原理
Spark ThriftServer(STS)是基于HiveServer2协议实现的Spark SQL服务,允许通过JDBC/ODBC连接器执行SQL查询。其架构组成如下:
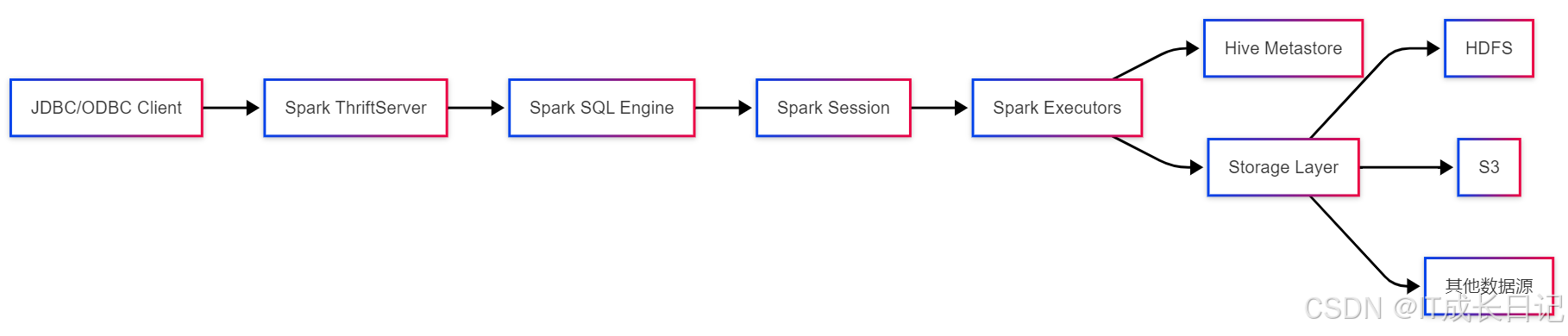
组件职责说明:
- ThriftServer:接收并管理客户端连接,实现多租户支持
- Spark SQL Engine:解析和优化SQL查询,生成执行计划
- Spark Session:维护用户会话状态和上下文信息
- Executors:分布式执行查询任务
- Metastore:获取Hive表的元数据信息
- Storage:访问实际数据存储系统
1.2 与传统HiveServer2的对比
| 特性 | Spark ThriftServer | HiveServer2 |
| 执行引擎 | Spark引擎 | MR/Tez/Spark |
| 内存管理 | 统一内存池 | 按查询隔离 |
| 并发性能 | 高并发(100+连接) | 中等并发(20-50连接) |
| 查询延迟 | 亚秒级响应 | 秒级响应 |
| 元数据访问 | 直接访问Hive Metastore | 通过HiveServer2代理 |
| 适用场景 | 交互式分析/BI连接 | ETL作业/传统报表 |
2 Spark ThriftServer部署指南
2.1 环境准备与启动流程
2.1.1 前置条件检查
- 版本兼容矩阵:
| Spark版本 | Hive版本 | JDK版本 |
| 3.1.x | 3.1.2+ | 8/11 |
| 3.0.x | 2.3.x+ | 8 |
| 2.4.x | 2.3.x | 8 |
- 配置文件调整:
# conf/hive-site.xml
<property><name>hive.metastore.uris</name><value>thrift://metastore-host:9083</value>
</property># conf/spark-defaults.conf
spark.sql.hive.thriftServer.singleSession=true
spark.sql.catalogImplementation=hive2.1.2 服务启动流程

- 启动命令示例:
./sbin/start-thriftserver.sh \--master yarn \--conf spark.driver.memory=4G \--conf spark.executor.instances=10 \--hiveconf hive.server2.thrift.port=100002.2 高可用部署方案
2.2.1 基于ZooKeeper的HA架构
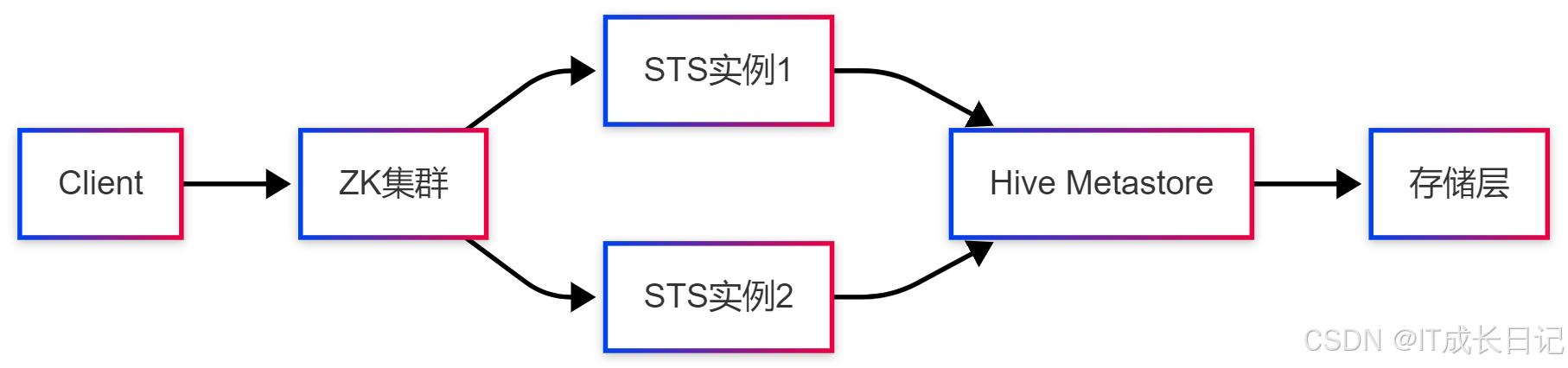
- 配置关键参数:
# spark-thrift-server.conf
spark.deploy.zookeeper.url=zk1:2181,zk2:2181
spark.deploy.recoveryMode=ZOOKEEPER
hive.server2.support.dynamic.service.discovery=true3 性能优化实战
3.1 查询执行流程深度解析
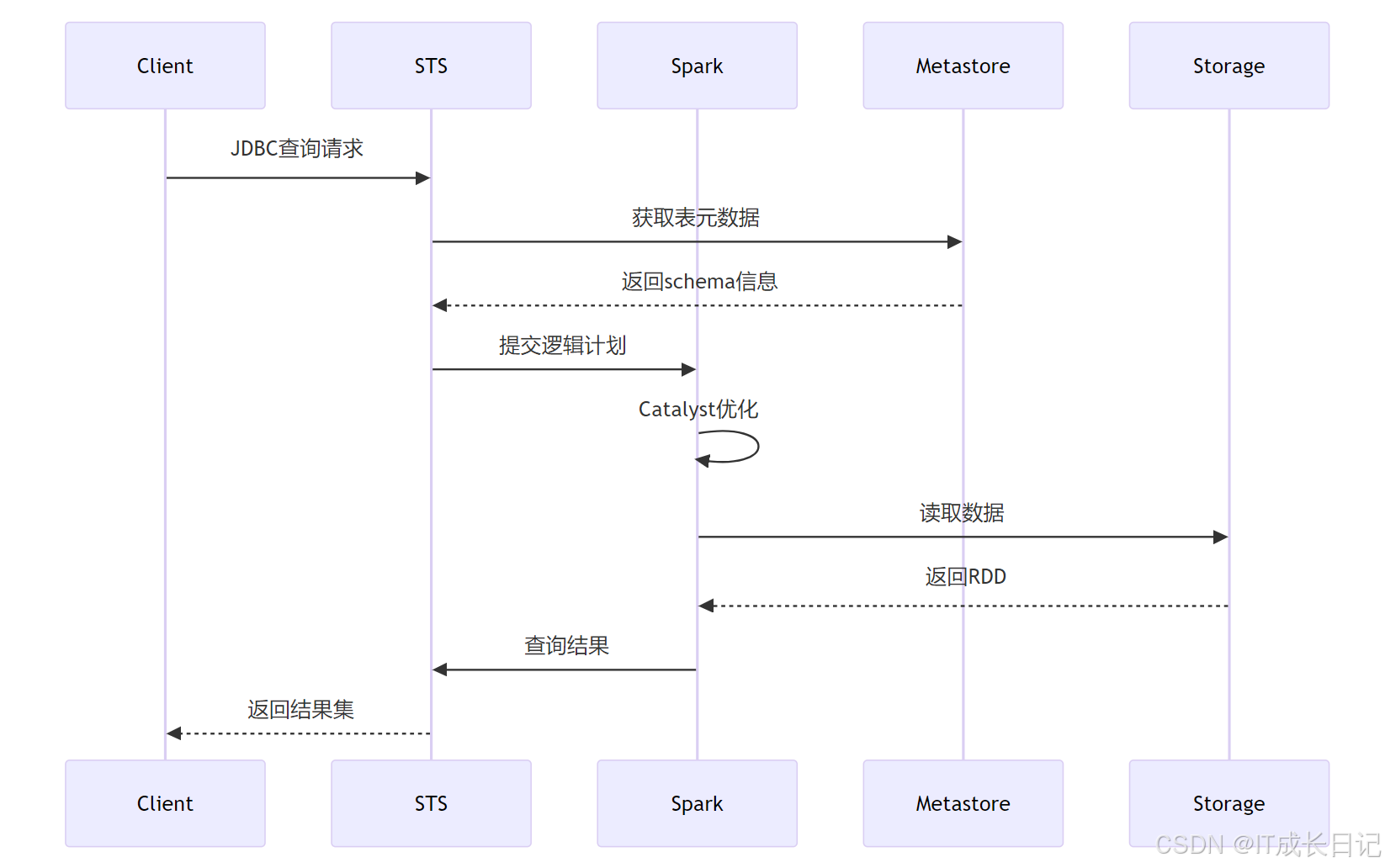
关键优化点:
- 元数据缓存:缓存频繁访问的表元数据
- 执行计划缓存:对相似查询复用执行计划
- 数据本地化:优先从本地节点读取数据
3.2 核心参数调优
3.2.1 内存管理配置
-- 驱动程序内存
SET spark.driver.memory=8G;
-- 执行器内存分配
SET spark.executor.memory=4G;
SET spark.executor.memoryOverhead=1G;
-- 内存分配策略
SET spark.memory.fraction=0.6;
SET spark.memory.storageFraction=0.5;3.2.2 并发控制参数
-- 最大并行连接数
SET spark.sql.thriftServer.incrementalCollect=true;
SET spark.sql.thriftServer.maxResultSize=4g;
-- 查询超时控制
SET spark.sql.broadcastTimeout=600;
SET spark.sql.thriftServer.queryTimeout=3600;3.3 高级优化技巧
3.3.1 动态资源分配
# 启动时配置
./start-thriftserver.sh \--conf spark.dynamicAllocation.enabled=true \--conf spark.dynamicAllocation.minExecutors=5 \--conf spark.dynamicAllocation.maxExecutors=503.3.2 数据倾斜处理方案
-- 倾斜键自动识别
SET spark.sql.adaptive.enabled=true;
SET spark.sql.adaptive.skewJoin.enabled=true;
-- 手动指定倾斜键
SET spark.shuffle.statistics.verbose=true;
SET spark.sql.shuffle.partitions=200;4 安全与权限管理
4.1 认证与授权体系
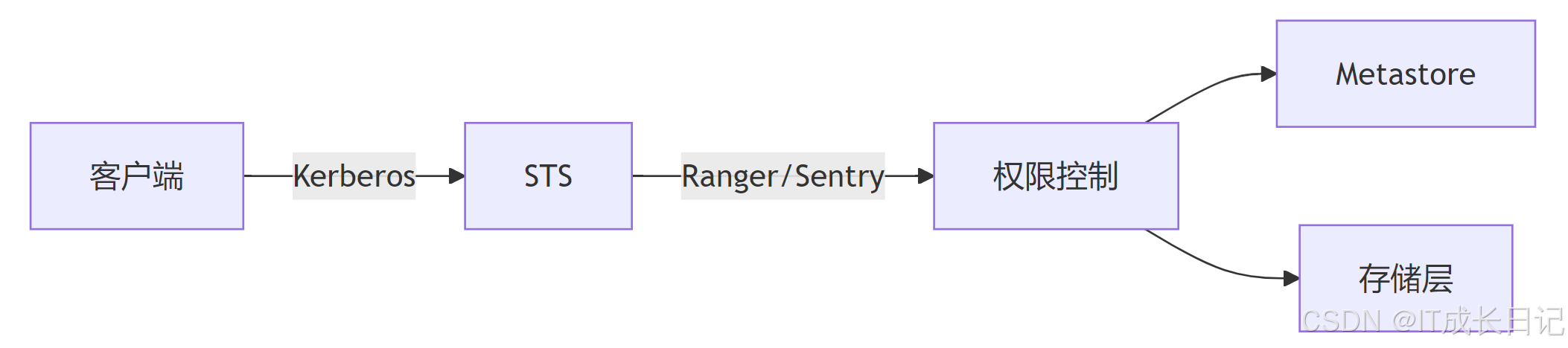
4.2 多租户资源隔离
4.2.1 基于YARN的隔离
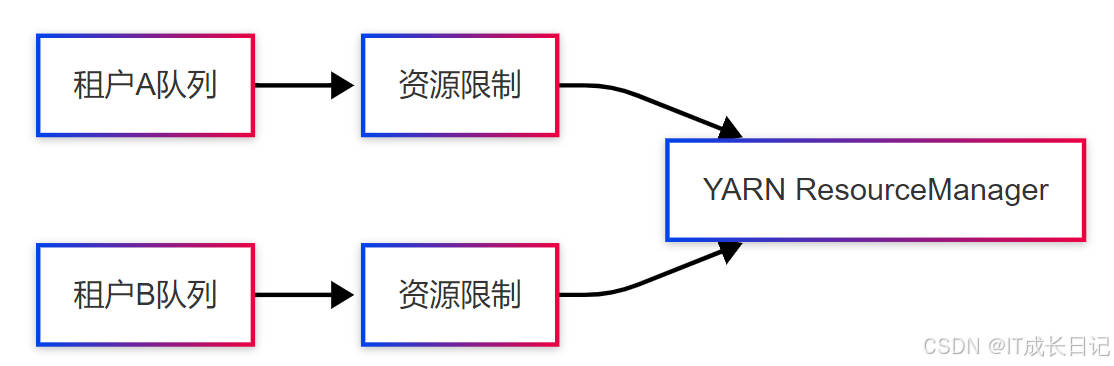
- 配置示例:
<!-- capacity-scheduler.xml -->
<queue name="tenant_a"><maxResources>40960mb,20vcores</maxResources>
</queue>4.2.2 Spark级别的隔离
-- 每个会话资源限制
SET spark.cores.max=4;
SET spark.executor.memory=2g;
-- 查询队列设置
SET spark.yarn.queue=production;5 监控与运维
5.1 关键监控指标
| 指标类别 | 具体指标 | 监控工具 |
| 资源使用 | CPU/Memory/IO利用率 | Grafana+Prometheus |
| 查询性能 | 平均响应时间/P95延迟 | Spark UI |
| 会话管理 | 活跃连接数/空闲会话 | JMX |
| 系统健康 | GC时间/线程阻塞 | ELK Stack |
5.2 常见问题排查指南
- 问题1:连接数达到上限
ERROR ThriftHttpCLIService: Too many connections- 解决方案:
# 增加最大连接数
./start-thriftserver.sh \--conf spark.sql.thriftServer.maxWorkerThreads=200- 问题2:查询结果过大导致OOM
- 优化方案:
-- 启用分批获取
SET spark.sql.thriftServer.incrementalCollect=true;
SET spark.sql.thriftServer.maxResultSize=2g;
-- 客户端配置
jdbc:hive2://host:10000/?fetchSize=10006 总结
通过Spark ThriftServer查询Hive表为企业提供了一种高性能、高并发的数据访问方案。相比传统HiveServer2,STS在以下几个方面展现出显著优势:
- 性能提升:利用Spark内存计算引擎,复杂查询性能提升3-5倍
- 并发能力:支持100+并发连接,满足BI工具直接连接需求
- 资源利用率:通过动态资源分配提高集群整体利用率
- 生态兼容:完全兼容Hive生态,无需修改现有表结构
在实际生产部署中,建议:
- 为交互式分析场景单独部署STS集群
- 根据工作负载特征精细调整内存参数
- 实施完善的多租户资源隔离策略
- 建立全面的监控告警体系
随着Spark和Hive社区的持续发展,Spark ThriftServer将成为连接传统数据仓库与现代分析应用的关键桥梁,为企业数据平台提供更强大的实时分析能力。
![[面试]SoC验证工程师面试常见问题(二)](http://pic.xiahunao.cn/[面试]SoC验证工程师面试常见问题(二))





)









驱动工具软件下载及安装教程)
---java版)

协议详解)