技术解读:多模架构、高效时序数据处理与分布式实现
- 一、多模架构
- 1.1 架构概述
- 1.2 源码分析
- 1.3 实现流程
- 二、高效时序数据处理
- 2.1 处理能力概述
- 2.2 源码分析
- 2.3 实现流程
- 三、分布式实现
- 3.1 分布式特性概述
- 3.2 源码分析
- 3.3 实现流程
- 四、总结
在当今数据爆炸的时代,数据库技术的发展日新月异,尤其是对于能够适应复杂多样数据场景的数据库需求愈发强烈。KWDB作为一款面向AIoT场景的分布式多模数据库,凭借其独特的多模架构、高效的时序数据处理能力以及强大的分布式特性,在众多数据库产品中脱颖而出。
本文基于 KWDB 的源码,解析其核心架构设计和关键技术实现,重点探讨以下三个技术亮点:
- 多模架构设计:支持多种数据模型的灵活架构。
- 高效的时序数据处理:针对时序特性的优化技术。
- 分布式实现流程:数据分片、存储和查询的分布式设计。
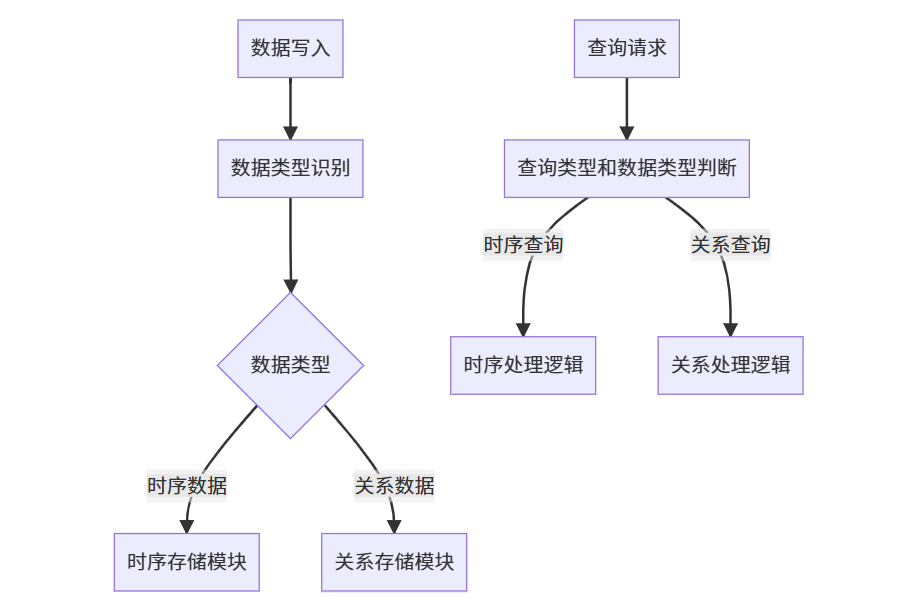
一、多模架构
1.1 架构概述
KWDB的多模架构允许在同一实例中同时建立时序库和关系库,并融合处理多模数据。这种架构设计的优势在于能够满足不同类型数据的存储和处理需求,为企业提供一站式的数据解决方案。
1.2 源码分析
虽然在提供的源码中没有直接体现多模架构的核心代码,但从整体架构设计可以推测,KWDB需要在底层对不同类型的数据进行区分和管理。例如,在SQL执行层面,可能会有不同的处理逻辑来处理时序数据和关系数据。在KWDB/kwbase/pkg/sql目录下的相关代码,如buffer.go和delayed.go,可以看出对不同类型数据的处理逻辑有所不同。
// KWDB/kwbase/pkg/sql/buffer.go
// bufferNode consumes its input one row at a time, stores it in the buffer,
// and passes the row through. The buffered rows can be iterated over multiple
// times.
type bufferNode struct {plan planNode// TODO(yuzefovich): the buffer should probably be backed by disk. If so, the// comments about TempStorage suggest that it should be used by DistSQL// processors, but this node is local.bufferedRows *rowcontainer.RowContainerpassThruNextRowIdx int// label is a string used to describe the node in an EXPLAIN plan.label string
}
从bufferNode结构体的定义可以看出,它用于存储和处理数据行,不同类型的数据可能会有不同的存储和处理方式。例如,时序数据可能需要按照时间顺序进行存储和索引,而关系数据则可能更注重表结构和关联关系。
在KWDB/kwbase/pkg/sql/opt/memo/memo.go中定义的MultimodelHelper结构体,可能与多模数据的处理配置有关。代码如下:
// configurations for multiple model processing.
type MultimodelHelper struct {AggNotPushDown []boolHashTagScan boolHasLastAgg boolIsUnion boolJoinRelations JoinRelationsPlanMode []PlanModePreGroupInfos []PreGroupInfoResetReasons map[MultiModelResetReason]struct{}TableData sync.MapTableGroup [][]opt.TableID
}
该结构体可能用于存储和管理多模数据处理的相关配置信息,为不同类型数据的处理提供支持。
1.3 实现流程
- 数据识别:在数据写入时,KWDB需要识别数据的类型,是时序数据还是关系数据。
- 存储分配:根据数据类型,将数据分配到不同的存储模块中,例如时序数据可能存储在专门的时序存储引擎中,而关系数据则存储在关系数据库中。
- 查询处理:在查询时,根据查询的类型和数据类型,选择合适的处理逻辑进行查询。
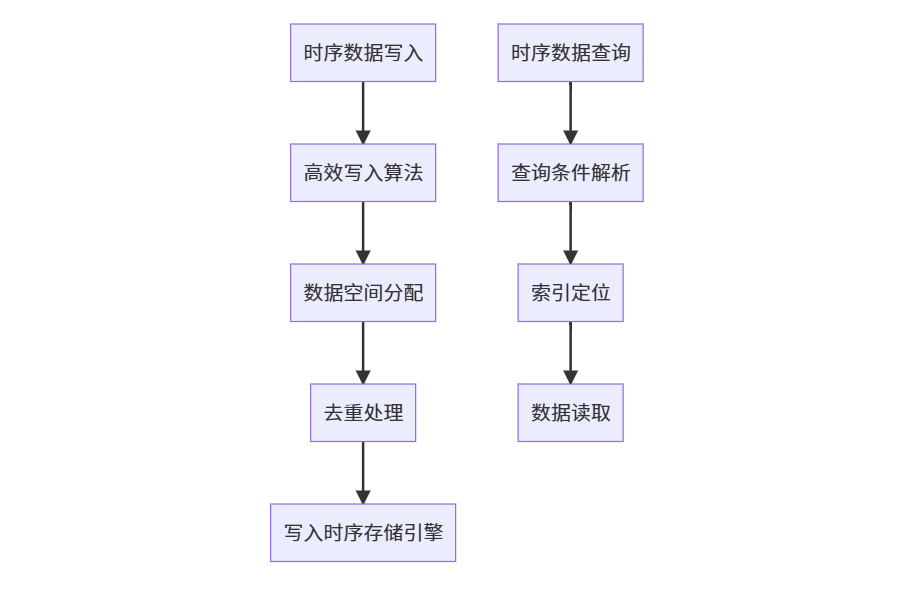
二、高效时序数据处理
2.1 处理能力概述
KWDB具备千万级设备接入、百万级数据秒级写入、亿级数据秒级读取等时序数据高效处理能力。这得益于其先进的时序数据存储和索引技术。
2.2 源码分析
在KWDB/qa/stress_tests/kwdbts-bench2/src/worker/statistics.h文件中,我们可以看到一些与时序数据统计相关的代码。
// KWDB/qa/stress_tests/kwdbts-bench2/src/worker/statistics.h
struct Statistics {// append StatisticsAvgStat db_append_t;AvgStat table_append_t;// Number and time of data blocks written by the flush thread per loopAvgStat flush_time;AvgStat flush_blocks;// Size and time required to write data to a partition fileAvgStat file_write_time;AvgStat file_write_size;AvgStat key_write_size;// The number and time of data blocks read each time according to [from,to]AvgStat block_find_num;AvgStat block_find_time;double WriteGB() {return file_write_size.sum() / KB / KB / KB;}double IoMB() {double sum_size = file_write_size.sum() / KB / KB; // MBdouble sum_time = file_write_time.sum() / Second; // secondreturn sum_size / sum_time;}void Show() {fprintf(stdout, "*******Statistics Print******\n"" DB Append =%.2f ns, table append=%.2f ns\n",db_append_t.avg(), table_append_t.avg());fflush(stdout);}void Reset() {db_append_t.reset();table_append_t.reset();flush_time.reset();flush_blocks.reset();file_write_time.reset();file_write_time.reset();block_find_num.reset();block_find_time.reset();}
};
从Statistics结构体可以看出,KWDB对时序数据的写入和读取进行了详细的统计,包括写入时间、写入大小、读取时间等。这些统计信息可以帮助优化时序数据的处理性能。
在KWDB/kwdbts2/mmap/src/mmap/mmap_partition_table.cpp中的TsTimePartition::RedoPut函数,负责处理时序数据的写入和存储。代码如下:
int TsTimePartition::RedoPut(kwdbts::kwdbContext_p ctx, uint32_t entity_id, kwdbts::TS_LSN lsn,uint64_t start_row, size_t num, kwdbts::Payload* payload,std::vector<BlockSpan>* alloc_spans, std::vector<MetricRowID>* todo_markdel,std::unordered_map<KTimestamp, MetricRowID>* partition_ts_map, KTimestamp p_time,ErrorInfo& err_info) {// 代码实现部分
}
该函数包含了数据写入前的检查、数据空间分配、去重处理、数据写入等操作,体现了高效时序数据处理的流程。
2.3 实现流程
- 数据写入:采用高效的写入算法,将大量的时序数据快速写入到存储系统中。例如,可能会采用批量写入、异步写入等方式提高写入性能。
- 数据存储:使用专门的时序存储引擎,对时序数据进行高效的存储和索引。例如,可能会采用时间分区、压缩存储等技术减少存储空间和提高读取性能。
- 数据读取:根据查询条件,快速定位和读取所需的时序数据。例如,可能会采用索引加速、预取等技术提高读取速度。
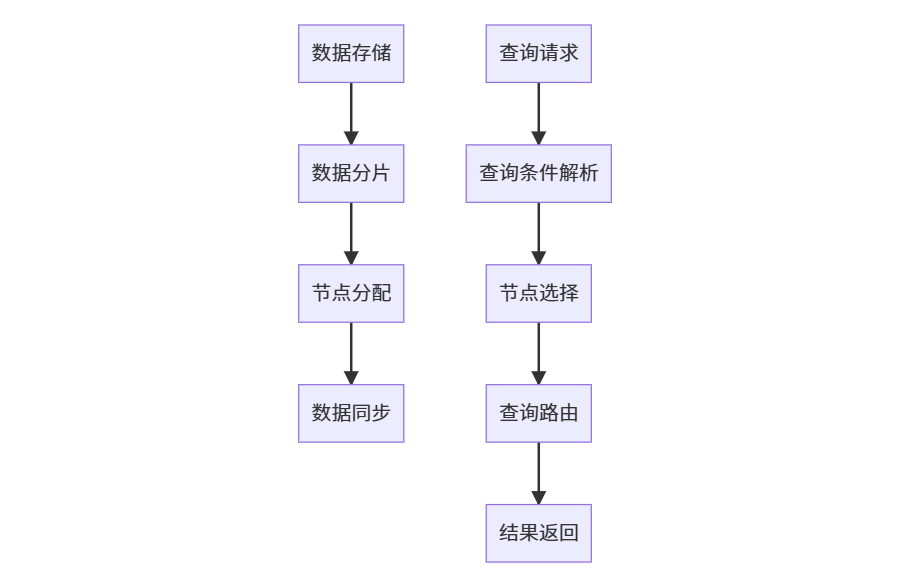
三、分布式实现
3.1 分布式特性概述
KWDB作为分布式数据库,具备分布式存储、分布式查询等特性,能够实现数据的高可用和负载均衡。
3.2 源码分析
在KWDB/kwbase/pkg/cmd/roachtest/tpchbench.go文件中,我们可以看到一些与分布式测试相关的代码。
// KWDB/kwbase/pkg/cmd/roachtest/tpchbench.go
// runTPCHBench runs sets of queries against CockroachDB clusters in different
// configurations.
//
// In order to run a benchmark, a TPC-H dataset must first be loaded. To reuse
// this data across runs, it is recommended to use a combination of
// `--cluster=<cluster>` and `--wipe=false` flags to limit the loading phase to
// the first run.
//
// This benchmark runs with a single load generator node running a single
// worker.
func runTPCHBench(ctx context.Context, t *test, c *cluster, b tpchBenchSpec) {roachNodes := c.Range(1, c.spec.NodeCount-1)loadNode := c.Node(c.spec.NodeCount)t.Status("copying binaries")c.Put(ctx, kwbase, "./kwbase", roachNodes)c.Put(ctx, workload, "./workload", loadNode)filename := b.benchTypet.Status(fmt.Sprintf("downloading %s query file from %s", filename, b.url))if err := c.RunE(ctx, loadNode, fmt.Sprintf("curl %s > %s", b.url, filename)); err != nil {t.Fatal(err)}t.Status("starting nodes")c.Start(ctx, t, roachNodes)m := newMonitor(ctx, c, roachNodes)m.Go(func(ctx context.Context) error {t.Status("setting up dataset")err := loadTPCHDataset(ctx, t, c, b.ScaleFactor, m, roachNodes)if err != nil {return err}t.l.Printf("running %s benchmark on tpch scale-factor=%d", filename, b.ScaleFactor)numQueries, err := getNumQueriesInFile(filename, b.url)if err != nil {t.Fatal(err)}// maxOps flag will allow us to exit the workload once all the queries were// run b.numRunsPerQuery number of times.maxOps := b.numRunsPerQuery * numQueries// Run with only one worker to get best-case single-query performance.cmd := fmt.Sprintf("./workload run querybench --db=tpch --concurrency=1 --query-file=%s "+"--num-runs=%d --max-ops=%d {pgurl%s} "+"--histograms="+perfArtifactsDir+"/stats.json --histograms-max-latency=%s",filename,b.numRunsPerQuery,maxOps,roachNodes,b.maxLatency.String(),)if err := c.RunE(ctx, loadNode, cmd); err != nil {t.Fatal(err)}return nil})m.Wait()
}
从runTPCHBench函数可以看出,KWDB通过分布式集群进行测试,涉及到节点的启动、数据的加载、查询的执行等操作。这表明KWDB在分布式环境下能够协调多个节点进行数据处理。
在KWDB/kwbase/pkg/cmd/allocsim/configs/multiple-nodes-per-locality-imbalanced-load.json文件中,定义了分布式节点的配置信息,包括节点数量、工作负载和节点之间的延迟等。代码如下:
{"Localities": [{"Name": "1","NumNodes": 3,"NumWorkers": 0,"OutgoingLatencies": [{"Name": "2","Latency": "50ms"},{"Name": "3","Latency": "50ms"}]},// 其他节点配置]
}
该配置文件为数据分片和节点通信提供了基础信息,有助于实现分布式存储和查询。
3.3 实现流程
- 数据分片:将数据按照一定的规则进行分片,分布到不同的节点上存储。例如,可能会按照时间、地域等因素进行分片。
- 节点通信:各个节点之间通过网络进行通信,实现数据的同步和协调。例如,可能会采用分布式一致性协议(如Raft)来保证数据的一致性。
- 查询路由:在查询时,根据查询条件将查询请求路由到合适的节点上进行处理。例如,可能会采用查询优化器来选择最优的查询路径。
四、总结
多模架构使得KWDB能够适应不同类型的数据需求,高效时序数据处理能力保证了在海量时序数据场景下的高性能,分布式特性则提供了数据的高可用和负载均衡。这些技术亮点使得KWDB在AIoT等领域具有广阔的应用前景。未来,我们可以进一步关注KWDB的发展,期待它在数据库技术领域取得更大的突破。

)















)

