今天主播我把黑马新版微服务课程MQ高级之前的内容都看完了,虽然在看视频的时候也记了笔记,但是看完之后还是忘得差不多了,所以打算写一篇博客再温习一下内容。
课程坐标:黑马程序员SpringCloud微服务开发与实战
微服务
认识单体架构
单体架构(monolithic structure):顾名思义,整个项目中所有功能模块都在一个工程中开发;项目部署时需要对所有模块一起编译、打包;项目的架构设计、开发模式都非常简单。
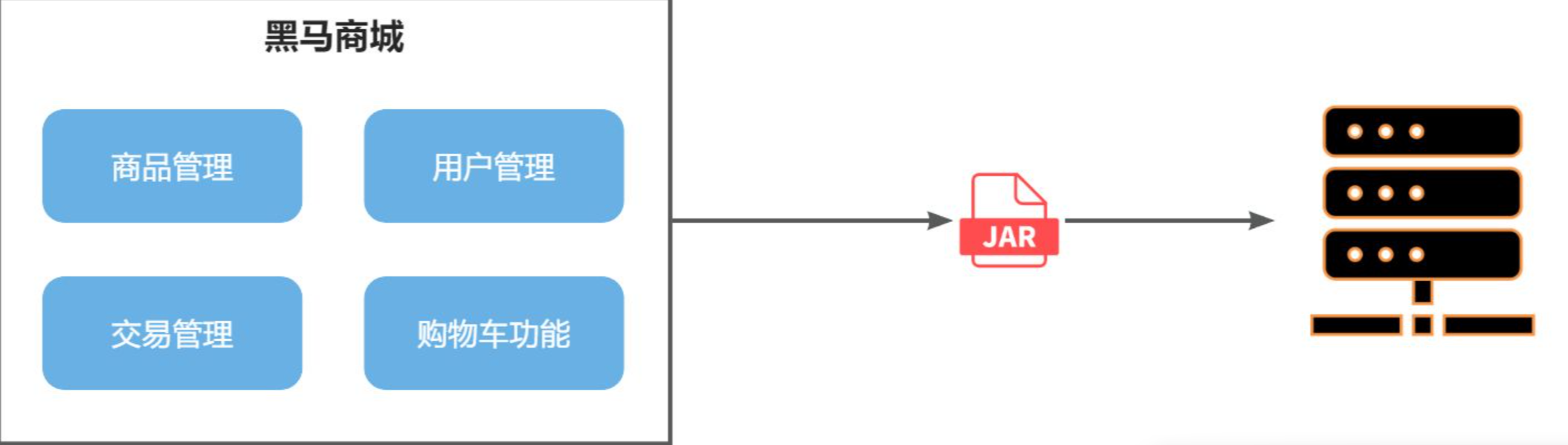
像我们之前写过的
苍穹外卖,黑马点评,他们虽然被拆分成了不同的模块,但是还是一个单体项目,通过Maven的聚合,让所有模块联系在一起,这种单体项目架构开发起来非常方便,例如我们简单写一个后台管理系统,或者是访问量较小的个人博客的后台系统的时候,单体项目是再简单不过的,但是如果我们用微服务来写,属实是大材小用。
但随着项目的业务规模越来越大,团队开发人员也不断增加,单体架构就呈现出越来越多的问题:
团队协作成本高:试想一下,你们团队数十个人同时协作开发同一个项目,由于所有模块都在一个项目中,不同模块的代码之间物理边界越来越模糊。最终要把功能合并到一个分支,你绝对会陷入到解决冲突的泥潭之中。在公司当中一般都是用git来管理代码,你想象下,你开发一个模块,别人开发另一个模块,但是有一天,你们都对公共代码进行了修改,向git提交的时候是不是就会出现合并冲突。系统发布效率低:任何模块变更都需要发布整个系统,而系统发布过程中需要多个模块之间制约较多,需要对比各种文件,任何一处出现问题都会导致发布失败,往往一次发布需要数十分钟甚至数小时。系统可用性差:单体架构各个功能模块是作为一个服务部署,相互之间会互相影响,一些热点功能会耗尽系统资源,导致其它服务低可用。
关于系统可用性差,我们可以想象下,如果我们单体项目有两个服务,一个是
不太经常被访问的接口A,而一个是经常被访问的热点接口B,如果我们使用的是单体项目架构,那么热点接口B在被频繁访问的时候就会影响A的访问速度和性能,这就是单体项目的缺点,功能之间的相互影响比较大。而要想解决这些问题,就需要使用微服务架构了。
认识微服务
微服务架构,首先是服务化,就是将单体架构中的功能模块从单体应用中拆分出来,独立部署为多个服务。同时要满足下面的一些特点:
单一职责:一个微服务负责一部分业务功能,并且其核心数据不依赖于其它模块。团队自治:每个微服务都有自己独立的开发、测试、发布、运维人员,团队人员规模不超过10人(2张披萨能喂饱)服务自治:每个微服务都独立打包部署,访问自己独立的数据库。并且要做好服务隔离,避免对其它服务产生影响
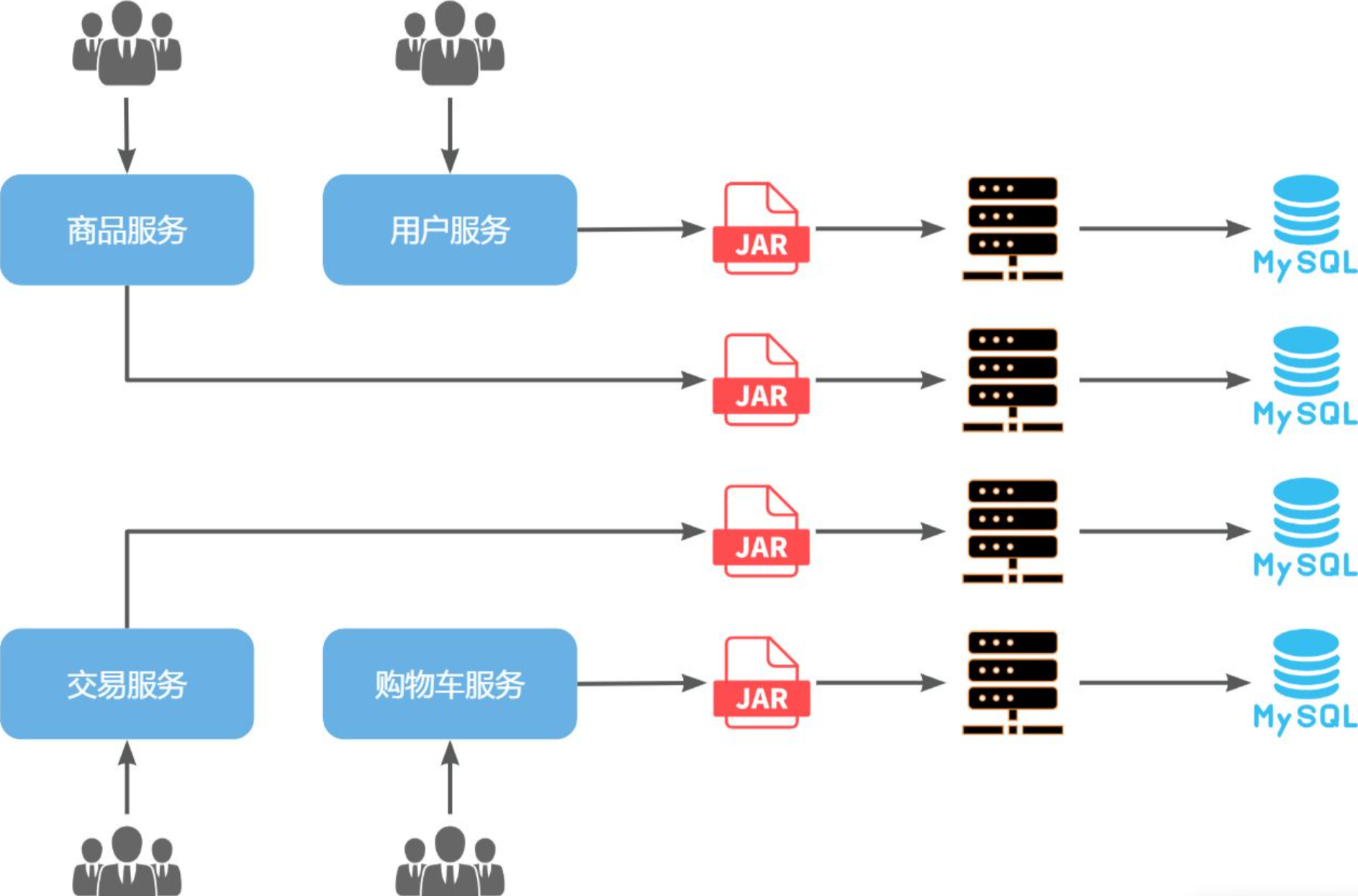
那么,单体架构存在的问题有没有解决呢?
团队协作成本高?- 由于服务拆分,每个服务代码量大大减少,参与开发的后台人员在1~3名,协作成本大大降低
系统发布效率低?- 每个服务都是独立部署,当有某个服务有代码变更时,只需要打包部署该服务即可
系统可用性差?- 每个服务独立部署,并且做好服务隔离,使用自己的服务器资源,不会影响到其它服务。
SpringCloud
微服务拆分以后碰到的各种问题都有对应的解决方案和微服务组件,而SpringCloud框架可以说是目前Java领域最全面的微服务组件的集合了。
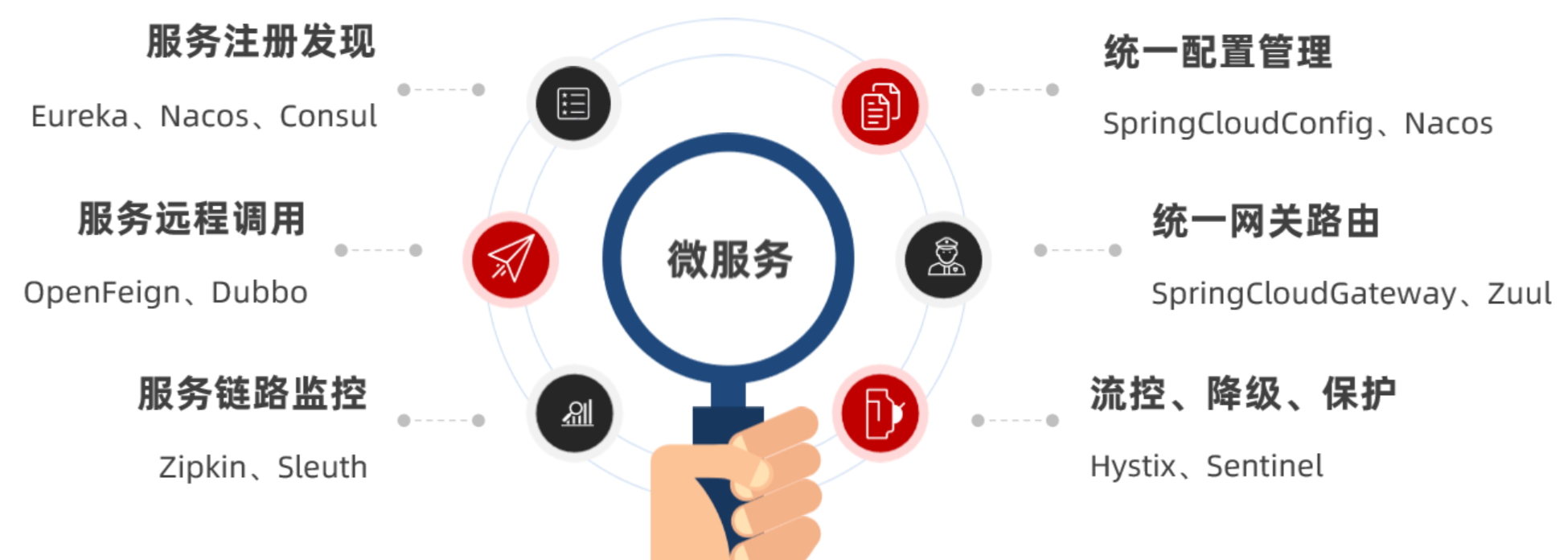
而且SpringCloud依托于SpringBoot的自动装配能力,大大降低了其项目搭建、组件使用的成本。对于没有自研微服务组件能力的中小型企业,使用SpringCloud全家桶来实现微服务开发可以说是最合适的选择了!
SpringCloud官方网址
拆分微服务
拆分原则
服务拆分一定要考虑几个问题:什么时候拆? 如何拆?
什么时候拆
一般情况下,对于一个初创的项目,首先要做的是验证项目的可行性。因此这一阶段的首要任务是敏捷开发,快速产出生产可用的产品,投入市场做验证。为了达成这一目的,该阶段项目架构往往会比较简单,很多情况下会直接采用单体架构,这样开发成本比较低,可以快速产出结果,一旦发现项目不符合市场,损失较小。
如果这一阶段采用复杂的微服务架构,投入大量的人力和时间成本用于架构设计,最终发现产品不符合市场需求,等于全部做了无用功。
所以,对于大多数小型项目来说,一般是先采用单体架构,随着用户规模扩大、业务复杂后再逐渐拆分为微服务架构。这样初期成本会比较低,可以快速试错。但是,这么做的问题就在于后期做服务拆分时,可能会遇到很多代码耦合带来的问题,拆分比较困难(前易后难)。
而对于一些大型项目,在立项之初目的就很明确,为了长远考虑,在架构设计时就直接选择微服务架构。虽然前期投入较多,但后期就少了拆分服务的烦恼(前难后易)。
怎么拆
之前我们说过,微服务拆分时粒度要小,这其实是拆分的目标。具体可以从两个角度来分析:
高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖,或者依赖接口的稳定性要强。
高内聚首先是单一职责,但不能说一个微服务就一个接口,而是要保证微服务内部业务的完整性为前提。目标是当我们要修改某个业务时,最好就只修改当前微服务,这样变更的成本更低。
一旦微服务做到了高内聚,那么服务之间的耦合度自然就降低了。
当然,微服务之间不可避免的会有或多或少的业务交互,比如下单时需要查询商品数据。这个时候我们不能在订单服务直接查询商品数据库,否则就导致了数据耦合。而应该由商品服务对应暴露接口,并且一定要保证微服务对外接口的稳定性(即:尽量保证接口外观不变)。虽然出现了服务间调用,但此时无论你如何在商品服务做内部修改,都不会影响到订单微服务,服务间的耦合度就降低了。
明确了拆分目标,接下来就是拆分方式了。我们在做服务拆分时一般有两种方式:纵向拆分 横向拆分
所谓纵向拆分,就是按照项目的功能模块来拆分。例如黑马商城中,就有用户管理功能、订单管理功能、购物车功能、商品管理功能、支付功能等。那么按照功能模块将他们拆分为一个个服务,就属于纵向拆分。这种拆分模式可以尽可能提高服务的内聚性。
而横向拆分,是看各个功能模块之间有没有公共的业务部分,如果有将其抽取出来作为通用服务。例如用户登录是需要发送消息通知,记录风控数据,下单时也要发送短信,记录风控数据。因此消息发送、风控数据记录就是通用的业务功能,因此可以将他们分别抽取为公共服务:消息中心服务、风控管理服务。这样可以提高业务的复用性,避免重复开发。同时通用业务一般接口稳定性较强,也不会使服务之间过分耦合。
拆分实操
这里我们以商品服务为例子,点击新建,选择新建模块
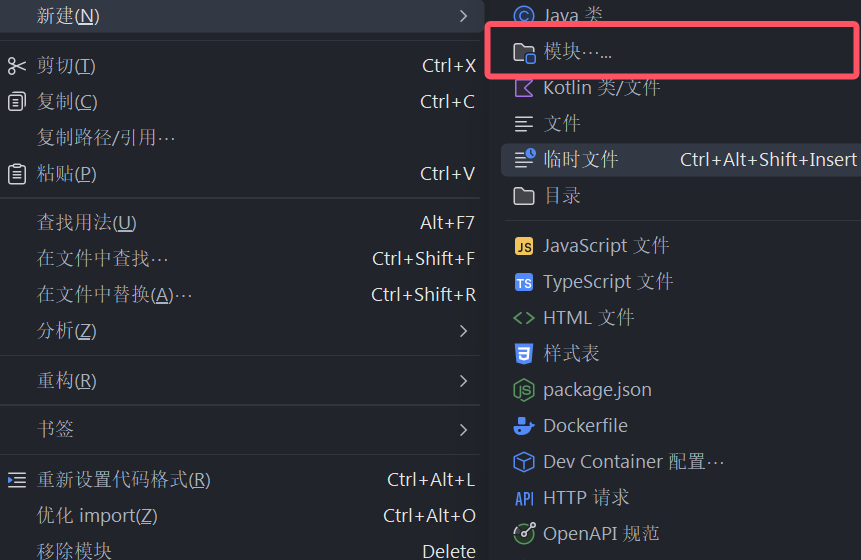
这里我们选择Java的Maven项目,JDK选择项目的JDK,父工程选择项目父工程
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>hmall</artifactId><groupId>com.heima</groupId><version>1.0.0</version></parent><modelVersion>4.0.0</modelVersion><artifactId>item-service</artifactId><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target></properties><dependencies><!--common--><dependency><groupId>com.heima</groupId><artifactId>hm-common</artifactId><version>1.0.0</version></dependency><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--数据库--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--mybatis--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId></dependency><!--单元测试--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>
编写启动类
package com.hmall.item;import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@MapperScan("com.hmall.item.mapper")
@SpringBootApplication
public class ItemApplication {public static void main(String[] args) {SpringApplication.run(ItemApplication.class, args);}
}
接下来就是拷贝与商品管理有关的代码到该微服务项目当中,然后写配置
server:port: 8081
spring:application:name: item-serviceprofiles:active: devdatasource:url: jdbc:mysql://${hm.db.host}:3306/hm-item?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghaidriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: ${hm.db.pw}
mybatis-plus:configuration:default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandlerglobal-config:db-config:update-strategy: not_nullid-type: auto
logging:level:com.hmall: debugpattern:dateformat: HH:mm:ss:SSSfile:path: "logs/${spring.application.name}"
knife4j:enable: trueopenapi:title: 商品服务接口文档description: "信息"email: zhanghuyi@itcast.cnconcat: 虎哥url: https://www.itcast.cnversion: v1.0.0group:default:group-name: defaultapi-rule: packageapi-rule-resources:- com.hmall.item.controller
注意在这里所有获取用户id的代码我们需要写死,后面我们会讲到如何获取。
服务调用
在微服务拆分的时候我们会发现,当一个微服务需要调用另一个微服务里的功能的时候,并不能直接注入Service,最终结果就是查询到的购物车数据不完整,因此要想解决这个问题,我们就必须改造其中的代码,把原本本地方法调用,改造成跨微服务的远程调用(RPC,即Remote Produce Call)。最终就变成了这样
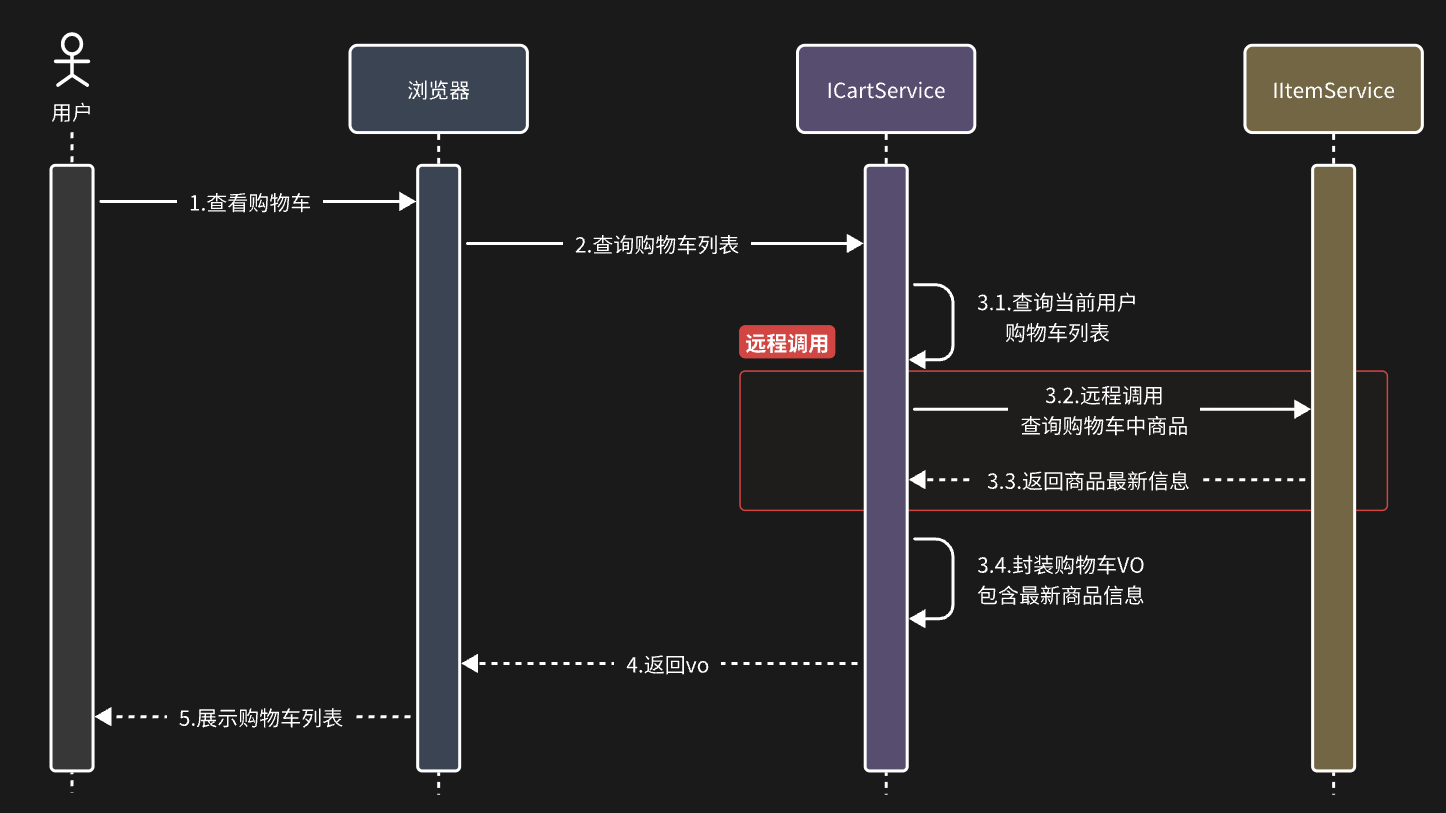
那么问题来了:我们该如何跨服务调用,准确的说,如何在cart-service中获取item-service服务中的提供的商品数据呢?
大家思考一下,我们以前有没有实现过类似的远程查询的功能呢?
有的兄弟,有的,我们前端向服务端查询数据,其实就是从浏览器远程查询服务端数据。比如我们刚才通过Swagger测试商品查询接口,就是向http://localhost:8081/items这个接口发起的请求:
而这种查询就是通过http请求的方式来完成的,不仅仅可以实现远程查询,还可以实现新增、删除等各种远程请求。
假如我们在cart-service中能模拟浏览器,发送http请求到item-service,是不是就实现了跨微服务的远程调用了呢?
那么:我们该如何用Java代码发送Http的请求呢?
RestTemplate
Spring给我们提供了一个RestTemplate的API,可以方便的实现Http请求的发送。其中提供了大量的方法,方便我们发送http请求。可以看到常见的Get、Post、Put、Delete请求都支持,如果请求参数比较复杂,还可以使用exchange方法来构造请求。

我们先将其注入为一个Bean:
package com.hmall.cart.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;@Configuration
public class RemoteCallConfig {@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}
远程调用
可以看到,利用RestTemplate发送http请求与前端ajax发送请求非常相似,都包含四部分信息:
- ① 请求方式
- ② 请求路径
- ③ 请求参数
- ④ 返回值类型
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange("http://localhost:8081/items?ids={ids}",HttpMethod.GET,null,new ParameterizedTypeReference<List<ItemDTO>>() {},Map.of("ids", CollUtil.join(itemIds, ","))
);
// 解析响应
if(!response.getStatusCode().is2xxSuccessful()){// 查询失败,直接结束return;
}
微服务的注册与发现
在上一章我们实现了微服务拆分,并且通过Http请求实现了跨微服务的远程调用。不过这种手动发送Http请求的方式存在一些问题。
试想一下,假如商品微服务被调用较多,为了应对更高的并发,我们进行了多实例部署,如图:

此时,每个item-service的实例其IP或端口不同,问题来了:
- item-service这么多实例,
cart-service如何知道每一个实例的地址?- http请求要写url地址,
cart-service服务到底该调用哪个实例呢?- 如果在运行过程中,
某一个item-service实例宕机,cart-service依然在调用该怎么办?- 如果并发太高,
item-service临时多部署了N台实例,cart-service如何知道新实例的地址?
为了解决上面的问题,就必须引入注册中心的概念了
注册中心
在微服务远程调用的过程中,包括两个角色:
服务提供者:提供接口供其它微服务访问,比如item-service服务消费者:调用其它微服务提供的接口,比如cart-service
在大型微服务项目中,服务提供者的数量会非常多,为了管理这些服务就引入了注册中心的概念。注册中心、服务提供者、服务消费者三者间关系如下:

流程如下
- 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
- 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
- 调用者自己对实例列表负载均衡,挑选一个实例
- 调用者向该实例发起远程调用
那么当提供服务的宕机或者开启了新的服务了,服务调用者该怎么知道呢
心跳机制:服务提供者会定期向注册中心发送请求,报告自己的健康状态,当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除- 当服务有
新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表- 当注册中心
服务列表变更时,会主动通知微服务,更新本地服务列表
Nacos注册中心
注册中心框架很多,目前国内流行的有三个
Eureka:Netflix公司出品,目前被集成在SpringCloud当中,一般用于Java应用Nacos:Alibaba公司出品,目前被集成在SpringCloudAlibaba中,一般用于Java应用Consul:HashiCorp公司出品,目前集成在SpringCloud中,不限制微服务语言
以上几种注册中心都遵循SpringCloud中的API规范,因此在业务开发使用上没有太大差异。但是Nacos是阿里巴巴公司开源的,有中文API,方便我们使用。
Nacos官网
我们部署Nacos是基于Docker进行的,所以先要准备Nacos的相关表,然后我们需要修改Nacos的配置文件,在运行的时候根据官方配置挂载指定目录
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim
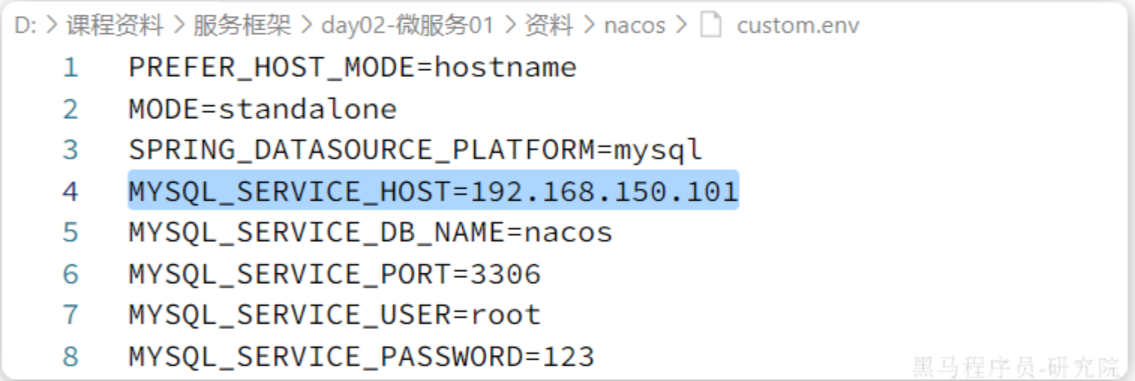
如果mysql和nacos在同一个网段下,这里直接写mysql的容器名字就可以,启动完成之后我们访问网址
http://虚拟机IP:8848/nacos/,账号密码都是nacos
服务注册
引入依赖
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
配置nacos
spring:application:name: item-service # 服务名称cloud:nacos:server-addr: 虚拟机IP:8848 # nacos地址
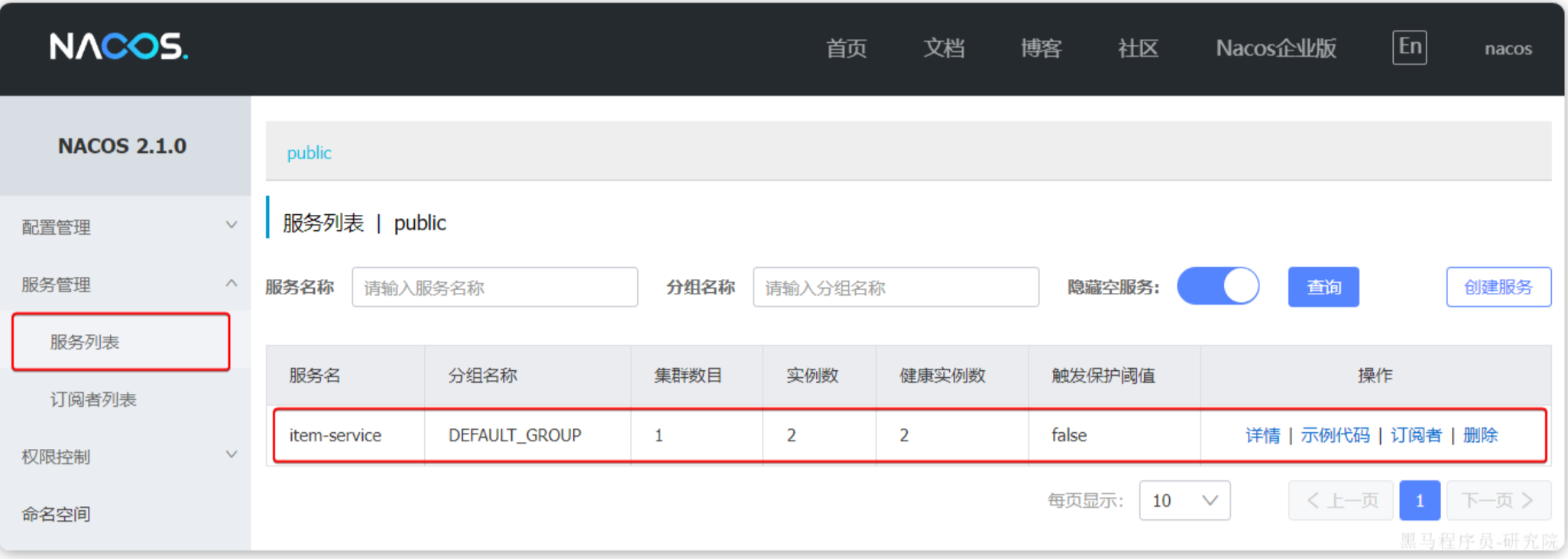
在Nacos注册的时候,就会根据微服务的名字来注册,所以每个微服务的名字要唯一不重复
启动项目之后,我们在网站上可以看到该服务已经被注册
服务发现
服务调用者想要调用其他微服务就要,引入依赖 配置Nacos地址 发现并调用服务 走这三步
引入依赖
服务发现除了要引入nacos依赖以外,由于还需要负载均衡,因此要引入SpringCloud提供的LoadBalancer依赖。
<!--nacos 服务注册发现-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
可以发现,这里Nacos的依赖于服务注册时一致,这个依赖中同时包含了服务注册和发现的功能。因为任何一个微服务都可以调用别人,也可以被别人调用,即可以是调用者,也可以是提供者。
因此,等一会儿cart-service启动,同样会注册到Nacos
配置Nacos
spring:cloud:nacos:server-addr: IP:8848
发现并调用服务
接下来,服务调用者cart-service就可以去订阅item-service服务了。不过item-service有多个实例,而真正发起调用时只需要知道一个实例的地址。
因此,服务调用者必须利用负载均衡的算法,从多个实例中挑选一个去访问。常见的负载均衡算法有:
- 随机
- 轮询
- IP的hash
- 最近最少访问
- …
这里我们可以选择最简单的随机负载均衡。
服务的发现需要一个工具,
DiscoveryClient,SpringCloud已经帮我们自动装配,我们可以直接注入使用
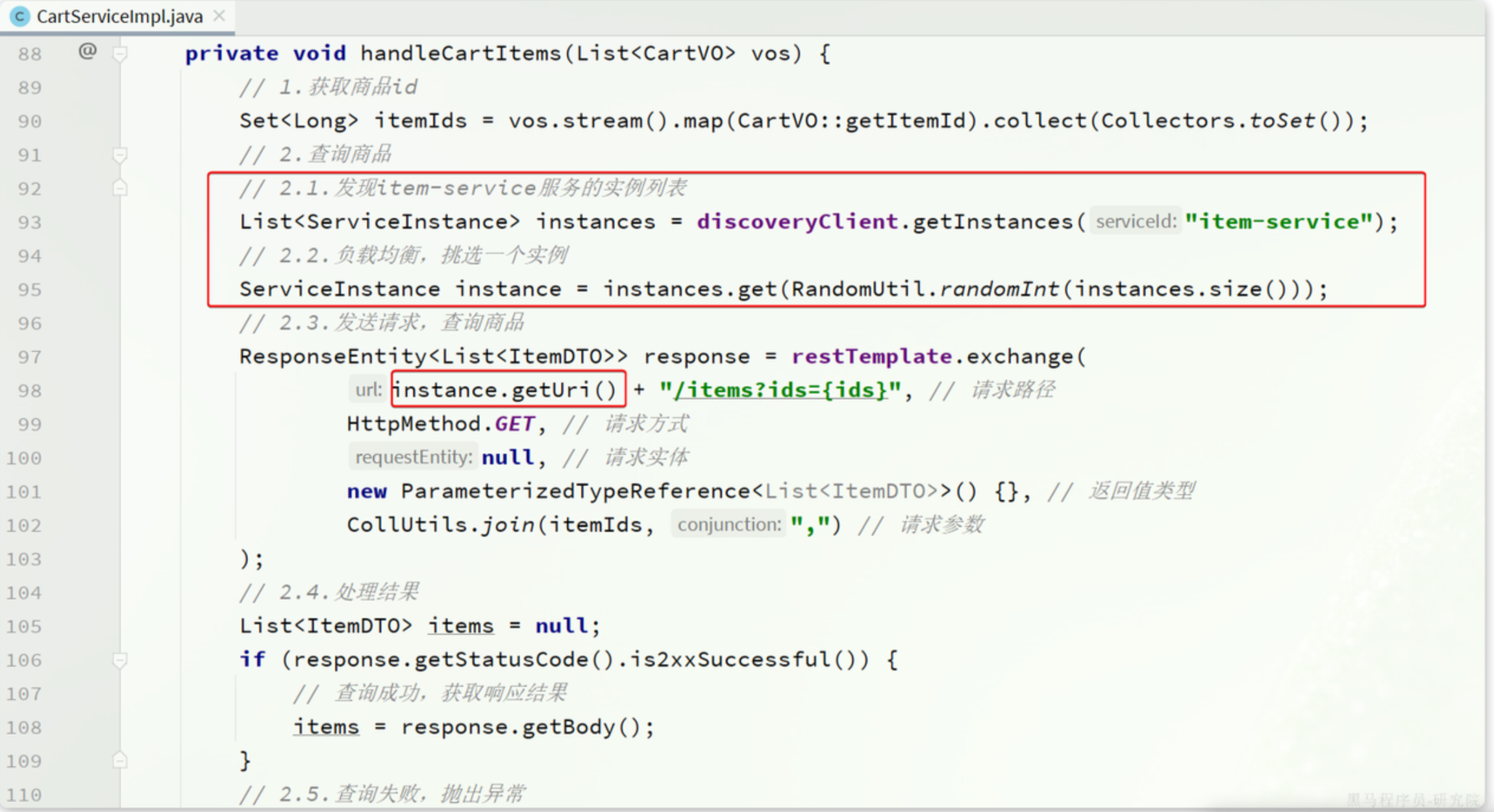
我们先通过这个工具,获取到所有命名为item-service的实例集合,然后随机获取一个,获取它的URI,然后调用。
OpenFegin
在上一章,我们利用Nacos实现了服务的治理,利用RestTemplate实现了服务的远程调用。但是远程调用的代码太复杂了,而且这种调用方式,与原本的本地方法调用差异太大,编程时的体验也不统一,一会儿远程调用,一会儿本地调用。
因此,我们必须想办法改变远程调用的开发模式,让远程调用像本地方法调用一样简单。而这就要用到OpenFeign组件了。
快速入门
引入依赖
<!--openFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--负载均衡器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>
启用OpenFeign
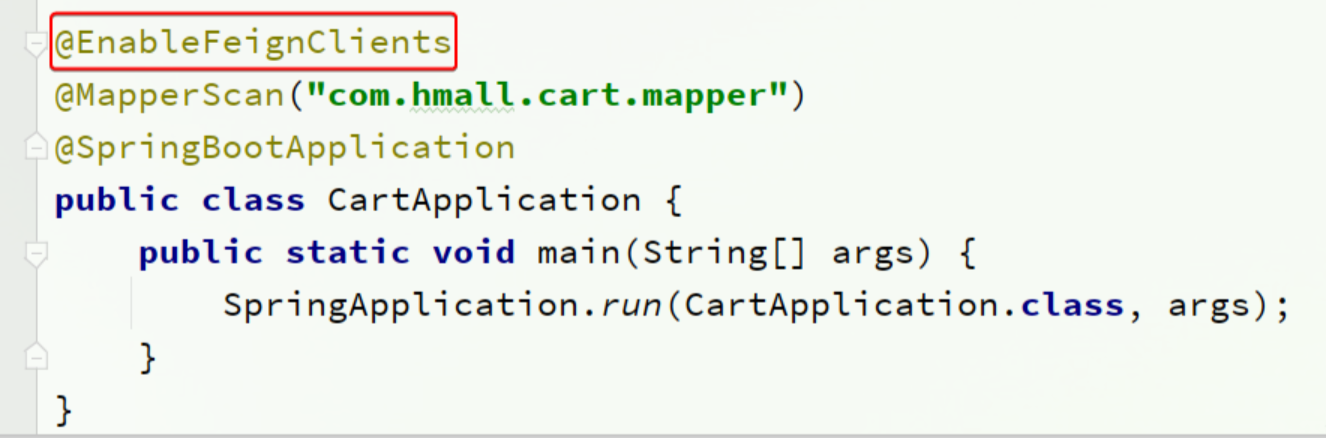
编写OpenFeign客户端
package com.hmall.cart.client;import com.hmall.cart.domain.dto.ItemDTO;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;import java.util.List;@FeignClient("item-service")
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}
这里只需要声明接口,无需实现方法。接口中的几个关键信息:
@FeignClient("item-service"):声明服务名称@GetMapping:声明请求方式@GetMapping("/items"):声明请求路径@RequestParam("ids") Collection<Long> ids:声明请求参数List<ItemDTO>:返回值类型
有了上述信息,OpenFeign就可以利用动态代理帮我们实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List。
我们只需要直接调用这个方法,即可实现远程调用了。
使用FeignClient
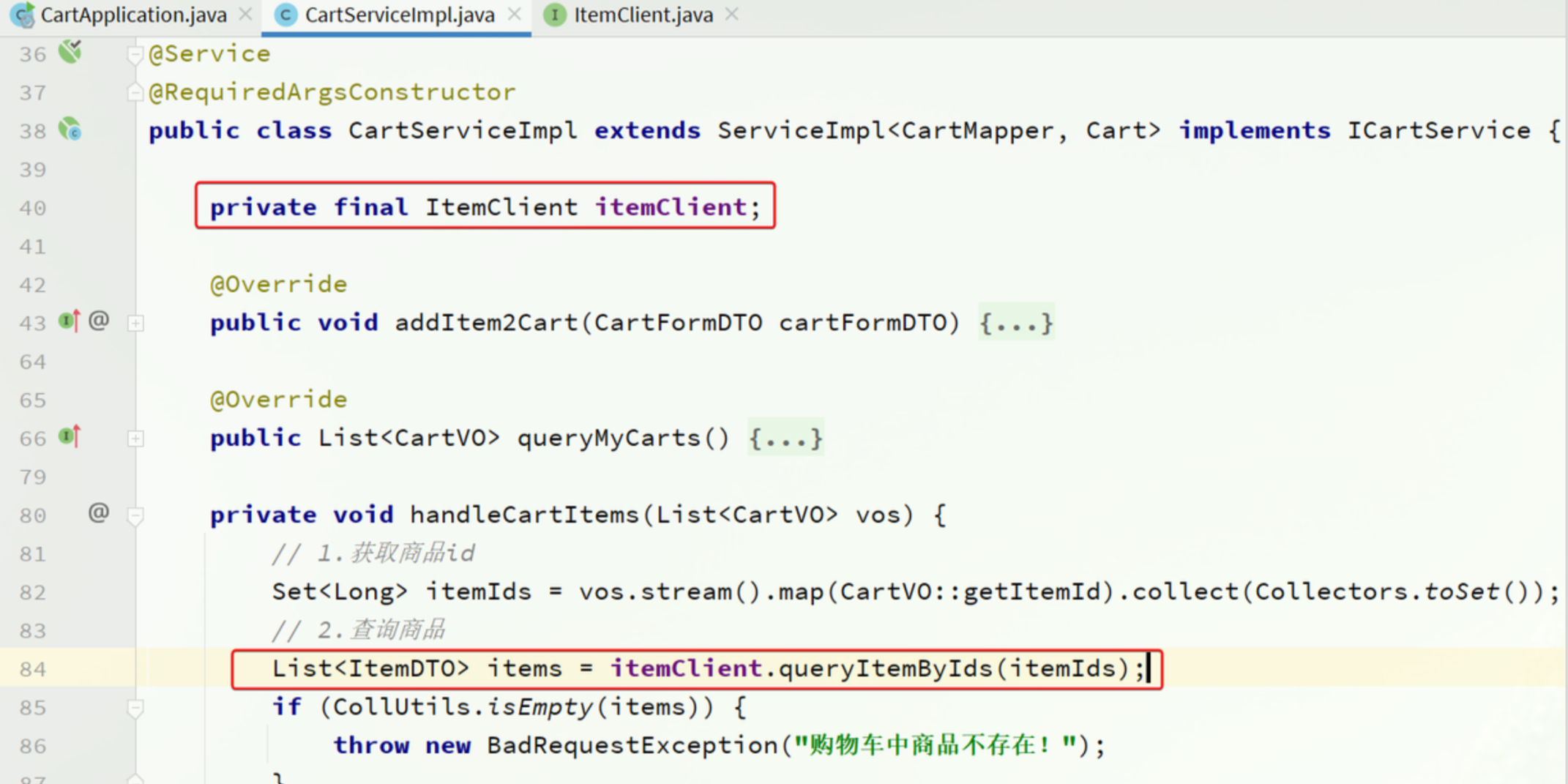
先注入,后使用
连接池
Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括:
HttpURLConnection:默认实现,不支持连接池Apache HttpClient:支持连接池OKHttp:支持连接池
引入依赖
<!--OK http 的依赖 -->
<dependency><groupId>io.github.openfeign</groupId><artifactId>feign-okhttp</artifactId>
</dependency>
配置开启连接池
feign:okhttp:enabled: true # 开启OKHttp功能
抽取Feign客户端
我们在里微服务调同一个接口的时候,如果没有抽取出来,那么每个微服务是不是都需要重新编写一下,那么有什么办法能解决这种重复编码的问题吗
这里有两种解决办法
- 思路1:抽取到微服务之外的公共module
- 思路2:每个微服务自己抽取一个module

方案1抽取更加简单,工程结构也比较清晰,但缺点是整个项目耦合度偏高。
方案2抽取相对麻烦,工程结构相对更复杂,但服务之间耦合度降低。
实战
这里我们选择方案1,只需要再创建一个模块,名为hm-all引入需要的依赖,在里面编写接口就可以。但是这里我们需要注意一个包扫描的问题,我们每个微服务都在独立的包中,包括这个API模块也在独立的保重,boot项目默认扫描的是当前包及其子包 。这里我们有两种解决方案。
- 第一种是生命扫描包

- 第二种是声明要用的FeignClient,这里面是一个数组,可以声明多个

_python版本)
)

![[Vue]App.vue讲解](http://pic.xiahunao.cn/[Vue]App.vue讲解)

)



)








的简单程序)
