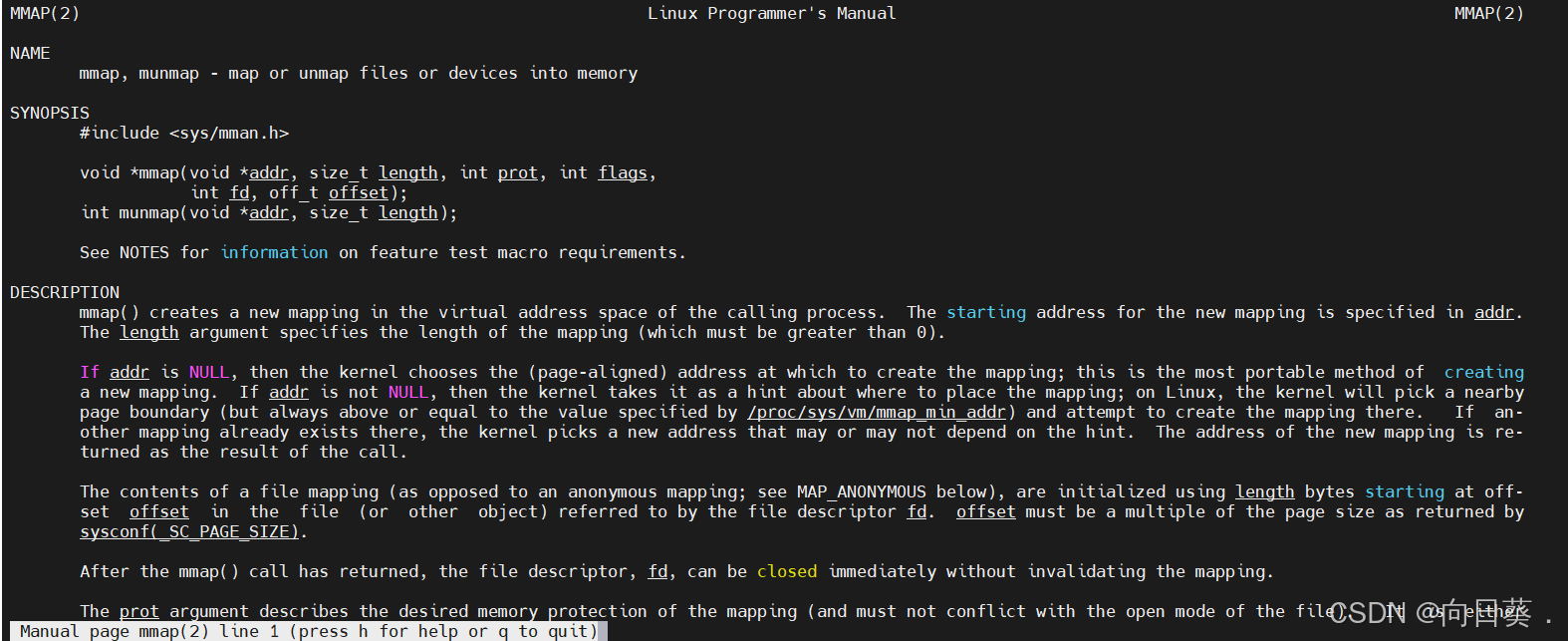
在用户态申请内存,内存内容和磁盘内容建立一一映射
读写内存等价于读写磁盘
支持随机访问
简单来说,把磁盘里的数据与内存的用户态建立一一映射关系,让读写内存等价于读写磁盘,支持随机访问。
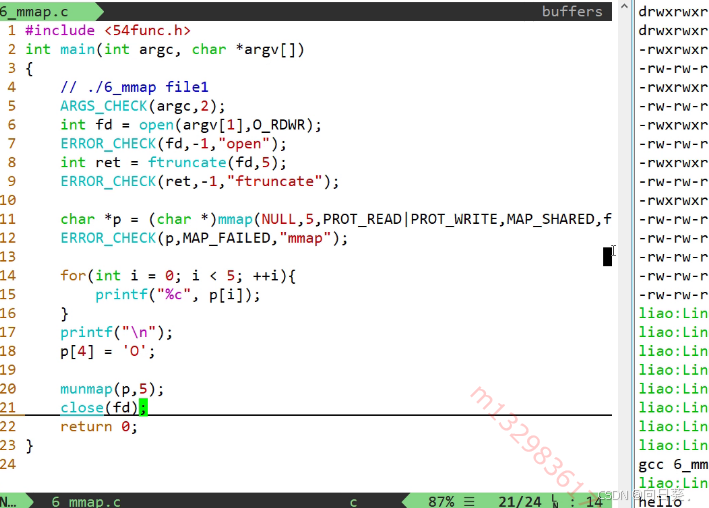
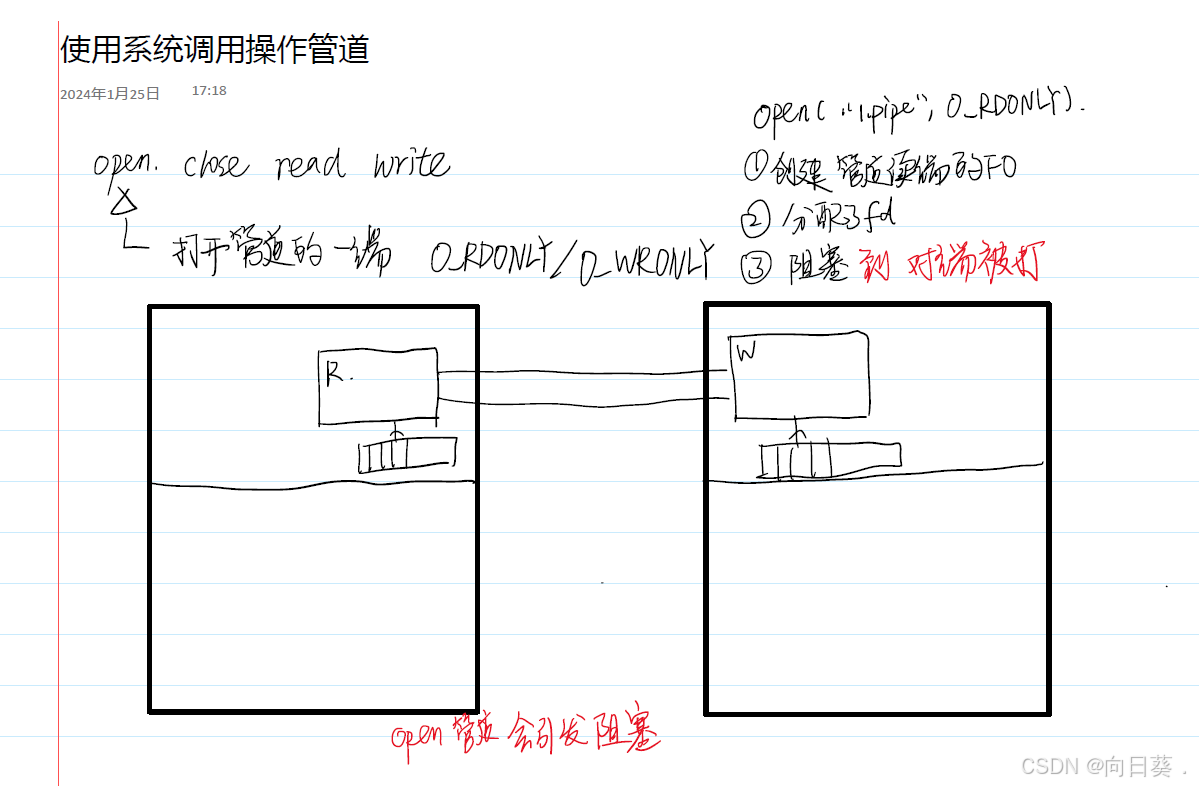
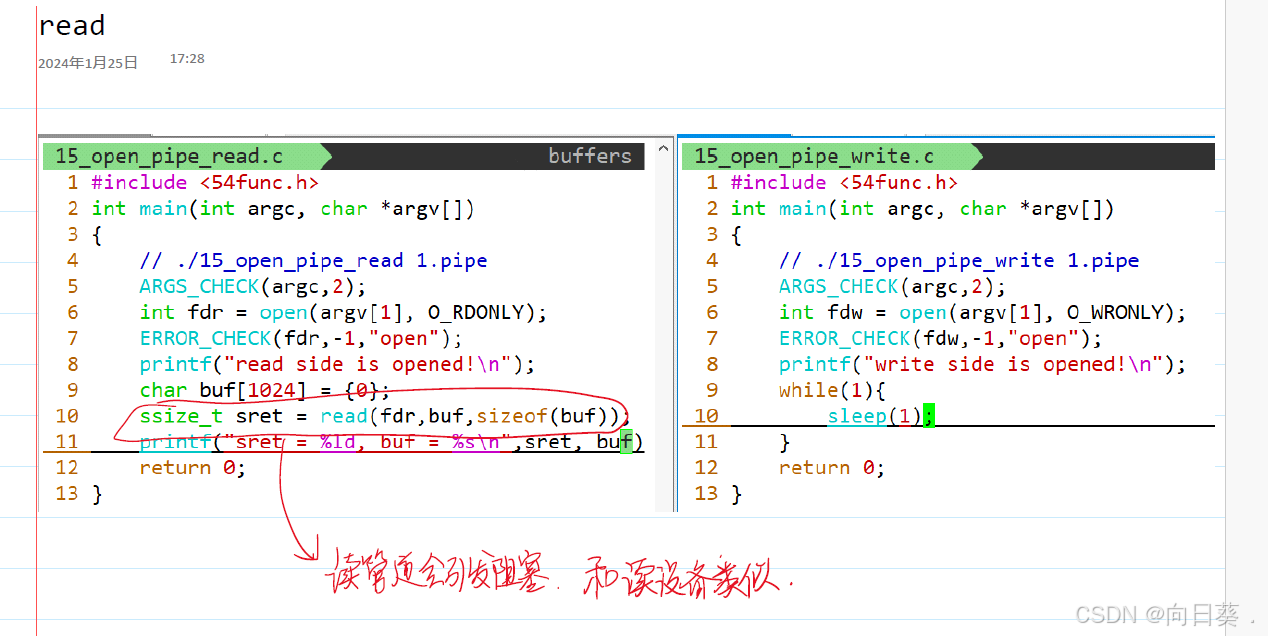
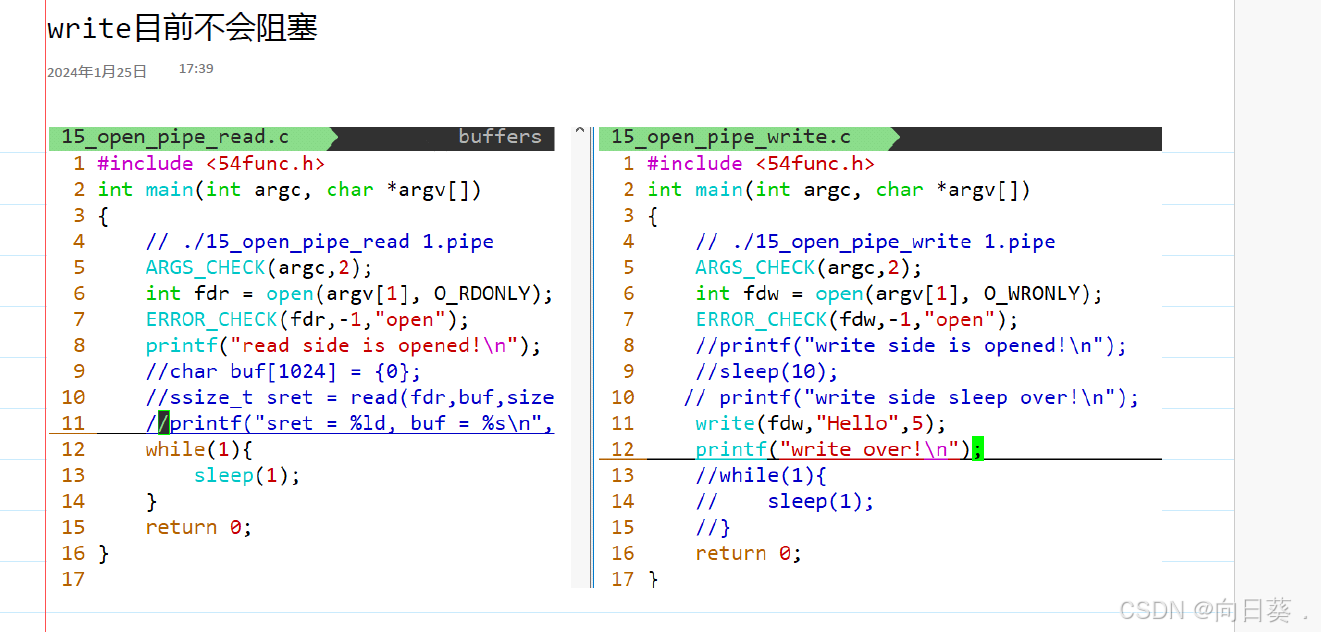
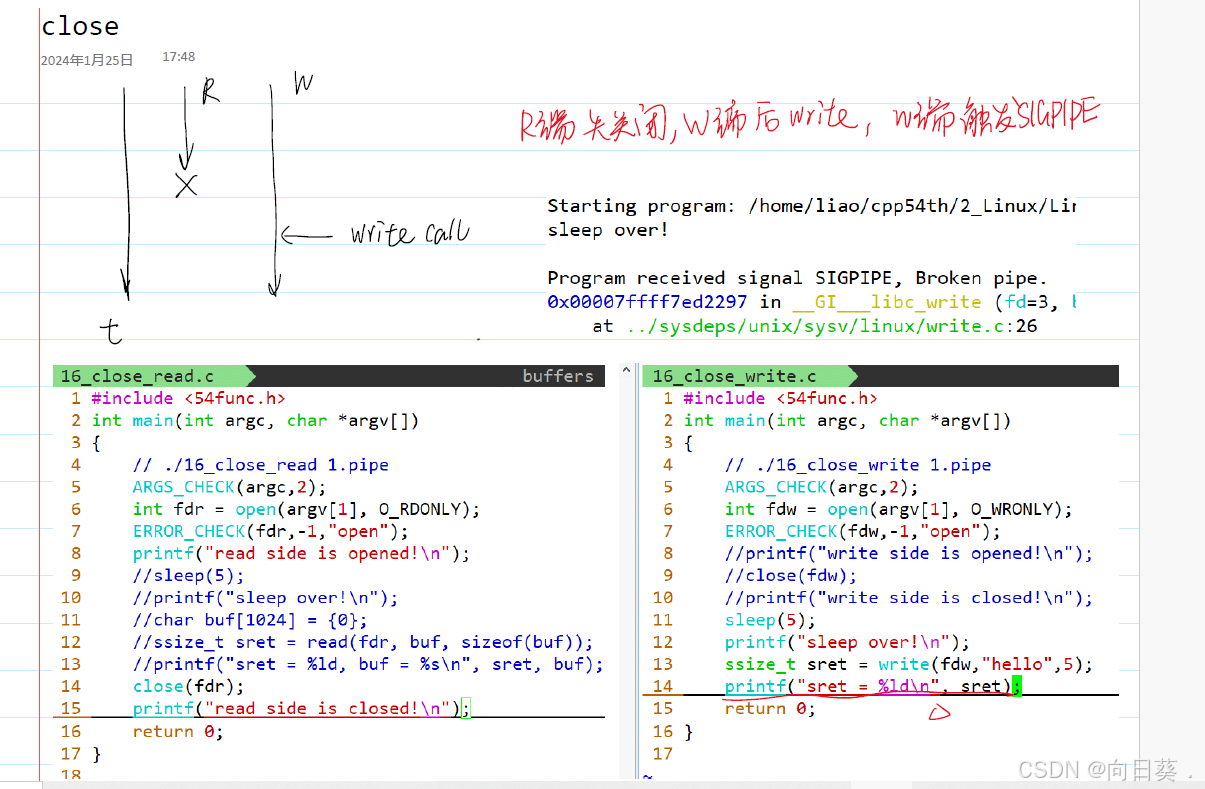
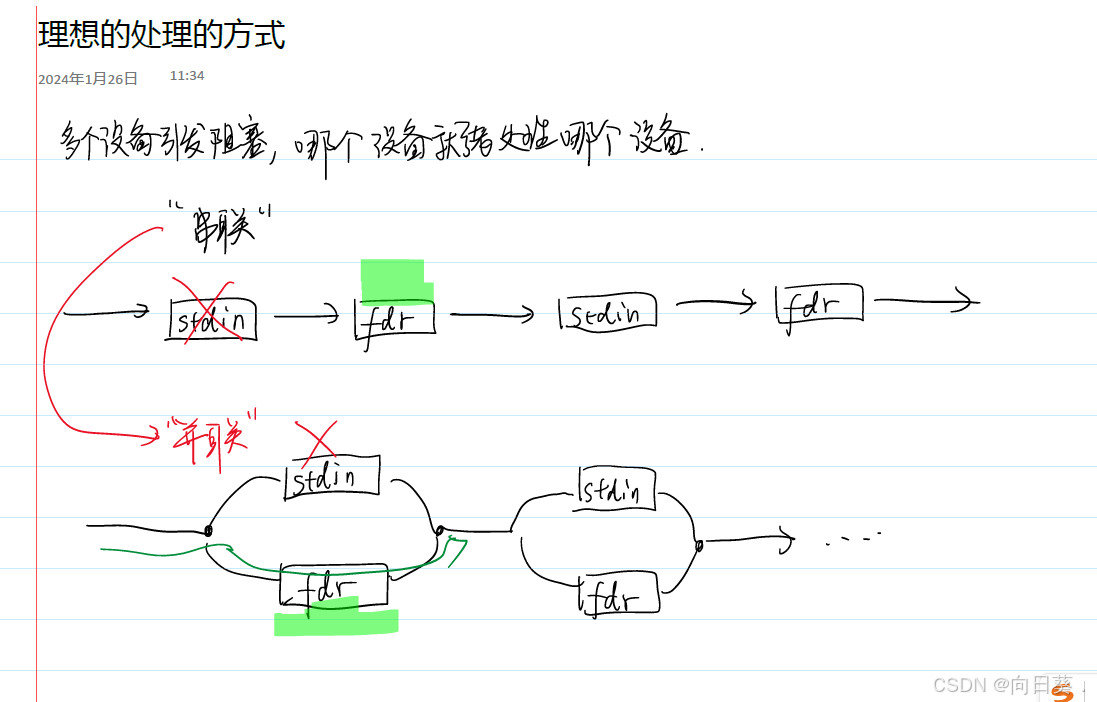
管道文件:进程间通信机制,不占用磁盘空间
named pipe /FIFO 命名管道:在文件系统中存在路径
进程之间沟通可以通过磁盘文件沟通
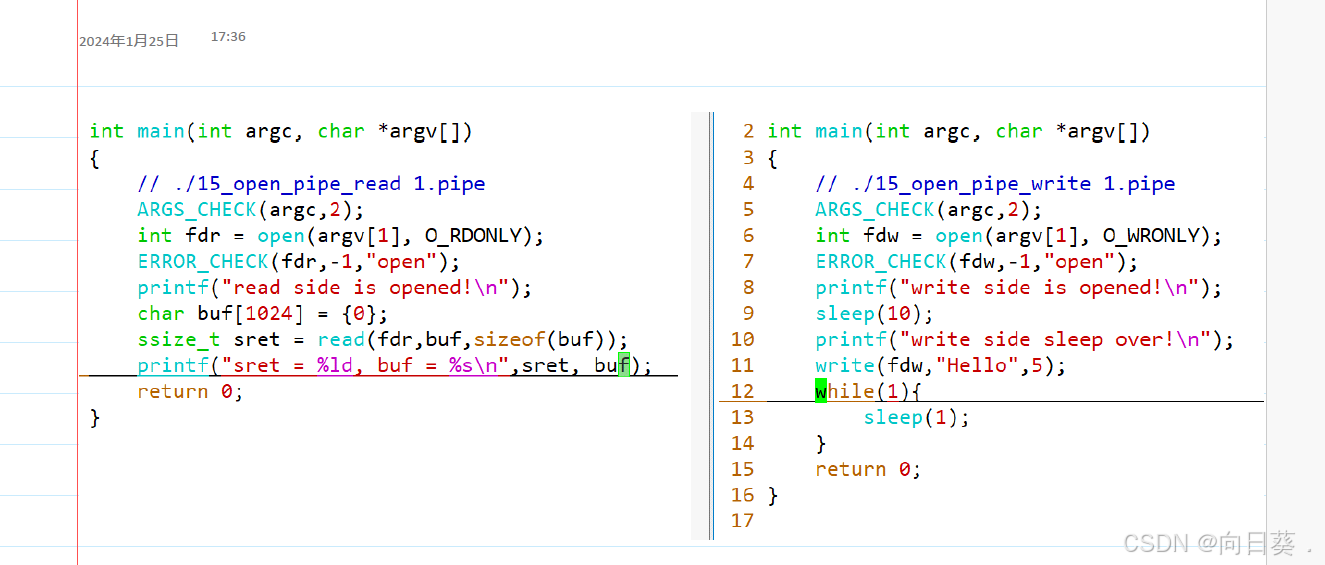
创建管道 mkfifo 1.pipe


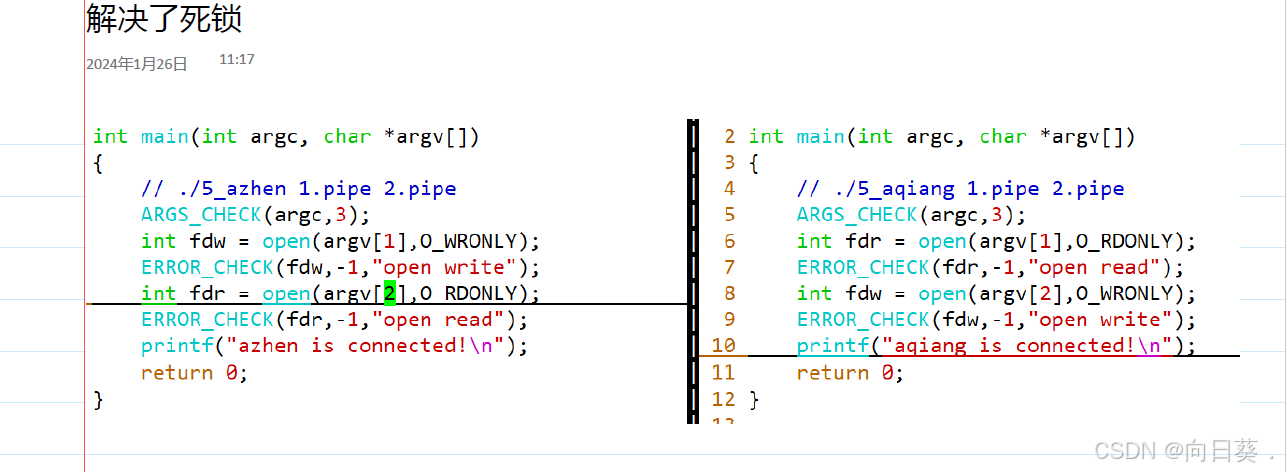
管道需要两个进程通信才能使用






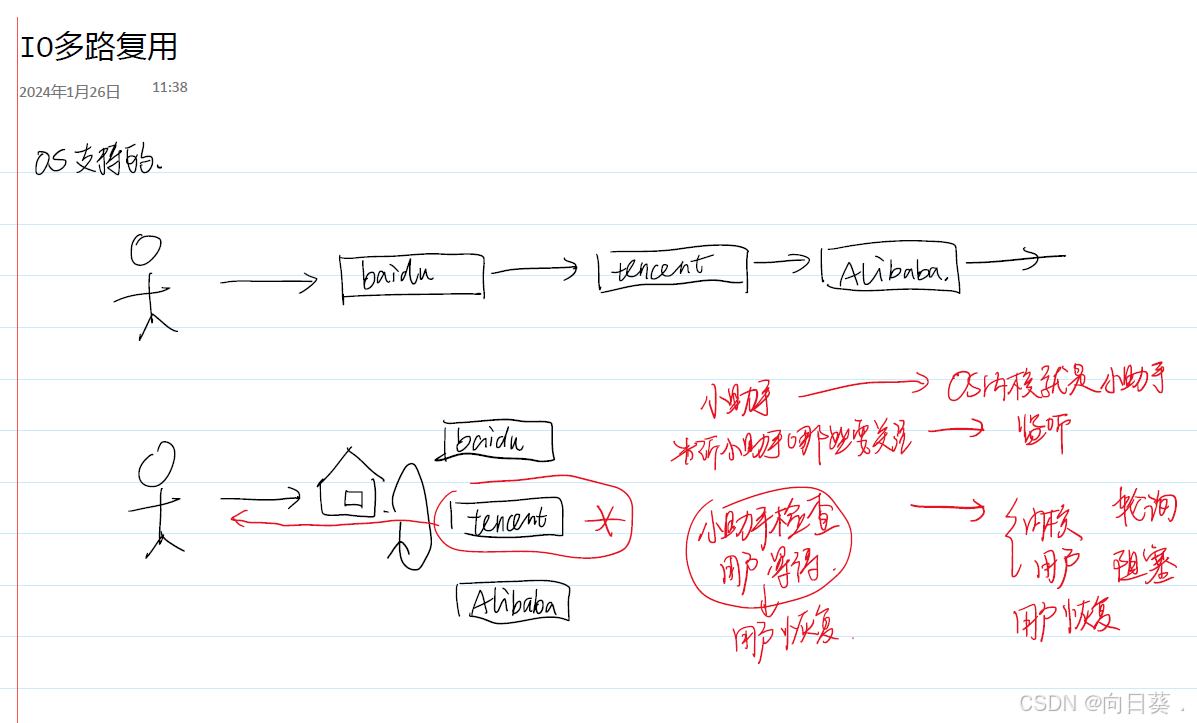
IO多路复用详解
1. 概念与背景
IO多路复用(I/O Multiplexing)是一种高效的IO处理机制,允许单个进程/线程同时监控多个文件描述符(如套接字)的IO事件(如可读、可写、异常)。当任意一个文件描述符的状态发生变化时,系统通知应用程序进行相应的处理,从而避免阻塞和线程资源的浪费。
背景:
- 在高并发网络编程中,传统阻塞IO模型(BIO)需要为每个连接创建一个线程,导致线程数量爆炸式增长,系统资源耗尽。
- 非阻塞IO模型(NIO)虽然避免了线程阻塞,但需要频繁轮询所有文件描述符,消耗大量CPU资源。
- IO多路复用通过事件驱动机制,解决了BIO和NIO的缺陷,成为高并发网络编程的核心技术。
2. 核心机制
IO多路复用的核心是事件通知机制,通过系统调用(如select、poll、epoll等)将多个文件描述符注册到内核,由内核监控这些描述符的状态变化。当有事件发生时,内核通知应用程序,应用程序再处理对应的事件。
关键点:
- 事件驱动:应用程序无需主动轮询,而是被动等待内核通知。
- 单线程处理:一个线程可以同时处理多个连接,减少线程切换开销。
- 高效性:内核只通知就绪的文件描述符,避免无效的轮询。
3. 实现方式
IO多路复用的实现方式主要有以下几种:
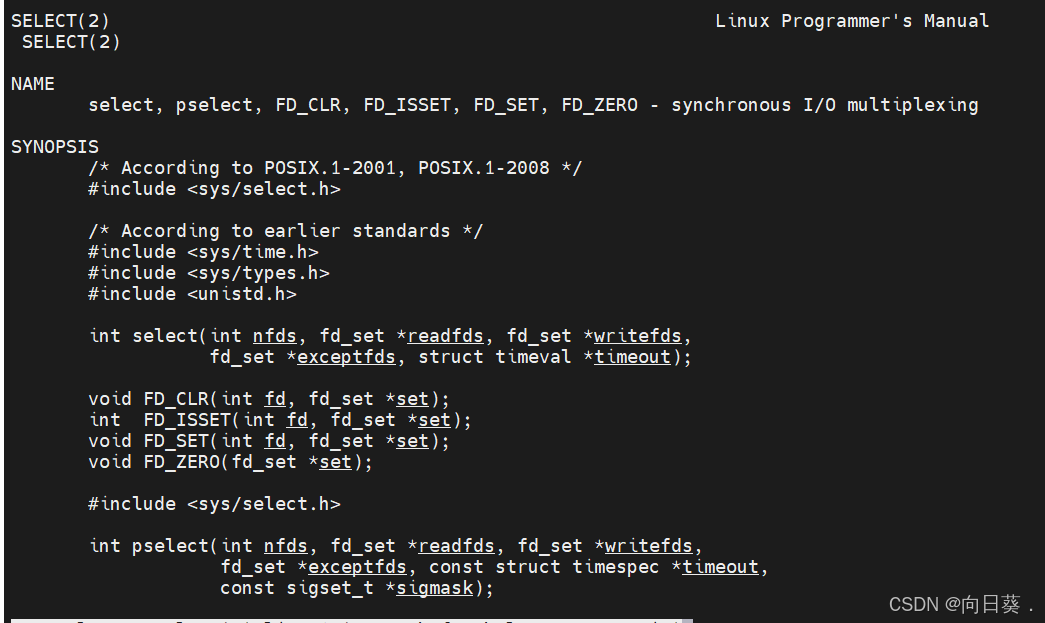
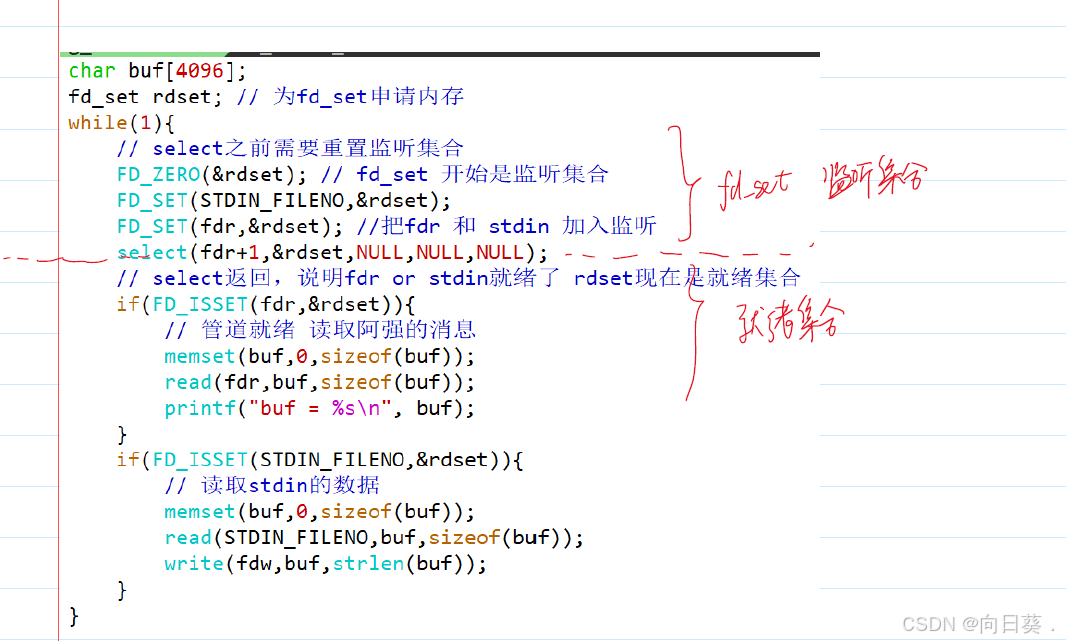
(1)select
- 原理:将文件描述符集合(
fd_set)传递给内核,内核遍历集合,检查哪些描述符就绪。 - 缺点:
- 文件描述符数量受限(通常为1024)。
- 每次调用都需要重新构造
fd_set,并拷贝到内核空间,开销较大。 - 内核遍历整个集合,时间复杂度为O(n)。
- 适用场景:低并发、文件描述符数量较少的场景。
(2)poll
- 原理:使用
pollfd结构体数组替代fd_set,每个元素包含文件描述符和需要监控的事件。 - 改进:
- 取消了文件描述符数量限制。
- 无需每次重新构造集合,只需修改
pollfd数组。
- 缺点:
- 仍然需要内核遍历整个数组,时间复杂度为O(n)。
pollfd数组需要用户态和内核态之间的拷贝。
- 适用场景:中低并发、文件描述符数量较多的场景。
(3)epoll(Linux特有)
- 原理:基于事件通知机制,内核维护一个就绪队列,当文件描述符就绪时,直接将其加入就绪队列。
- 改进:
- 边缘触发(ET):只通知一次状态变化,减少通知次数。
- 水平触发(LT):持续通知,直到状态变化被处理。
- 就绪队列:内核直接返回就绪的文件描述符,无需遍历。
- 优点:
- 支持大量文件描述符(理论上无上限)。
- 时间复杂度为O(1),高效处理高并发。
- 适用场景:高并发、海量连接的场景。
4. 工作原理
以epoll为例,其工作原理如下:
- 创建epoll实例:调用
epoll_create创建一个epoll对象,返回一个文件描述符。 - 注册文件描述符:调用
epoll_ctl将需要监控的文件描述符和事件类型(如可读、可写)注册到epoll对象中。 - 等待事件:调用
epoll_wait阻塞等待,直到有文件描述符就绪。 - 处理事件:内核将就绪的文件描述符和事件类型返回给应用程序,应用程序处理对应的事件。
5. 优势
- 高效性:通过事件通知机制,避免无效的轮询和阻塞。
- 可扩展性:支持大量并发连接,适用于高并发场景。
- 资源节省:减少线程数量,降低线程切换和内存占用。
6. 应用场景
- Web服务器:如Nginx、Lighttpd,使用
epoll处理海量HTTP连接。 - 网络库:如libuv(Node.js底层)、Boost.Asio,基于IO多路复用实现异步IO。
- 实时通信:如IM系统、游戏服务器,处理大量长连接。
- 数据库连接池:管理多个数据库连接,避免阻塞。
高并发IO(Input/Output) 是指系统在 短时间内需要处理大量的输入输出请求 的场景。它通常出现在需要同时服务大量用户或设备的应用中,例如网站、数据库、消息队列、分布式存储系统等。
一、核心概念解析
- 高并发
- 定义:系统在同一时间需要处理大量并发请求(如每秒数千次甚至上百万次)。
- 挑战:资源(CPU、内存、网络、磁盘)的竞争,可能导致性能瓶颈。
- IO(输入输出)
- 定义:系统与外部设备(如磁盘、网络)的数据交互。
- 特点:IO操作通常比CPU计算慢几个数量级,因此容易成为性能瓶颈。
- 高并发IO的挑战
- 传统IO模型:每个请求需要等待IO操作完成,导致线程阻塞,资源利用率低。
- 目标:在保证高并发的同时,优化IO性能,减少延迟。
二、高并发IO的典型场景
- Web应用
- 大量用户同时访问网站,服务器需要快速响应HTTP请求,读取数据库或文件系统中的数据。
- 数据库
- 高并发读写操作,例如电商平台的秒杀活动,大量用户同时查询或更新商品库存。
- 消息队列
- 生产者和消费者同时发送和接收消息,系统需要高效处理消息的存储和分发。
- 分布式存储
- 大量客户端同时读写存储节点,例如云存储服务需要处理海量文件上传和下载请求。
三、高并发IO的核心技术
- 异步IO(Asynchronous IO)
- 原理:线程发起IO请求后,无需等待操作完成,可以继续处理其他任务。
- 优势:减少线程阻塞,提高资源利用率。
- 实现:
- Linux的
epoll、kqueue等事件驱动模型。 - Java的
NIO(Non-blocking IO)和AIO(Asynchronous IO)。
- Linux的
- 多路复用(IO Multiplexing)
- 原理:单个线程可以同时监控多个IO通道,当某个通道准备好时,再处理该通道的请求。
- 工具:
select、poll、epoll(Linux)、kqueue(BSD)。
- 非阻塞IO(Non-blocking IO)
- 原理:IO操作不会阻塞线程,而是立即返回一个状态(如“未完成”),线程可以继续执行其他任务。
- 应用:结合事件循环(Event Loop)实现高效IO处理。
- 缓存
- 原理:将频繁访问的数据存储在内存中,减少对磁盘或网络的访问。
- 工具:Redis、Memcached等内存数据库。
- 分布式系统
- 原理:将IO负载分散到多个节点上,避免单点瓶颈。
- 技术:分片(Sharding)、复制(Replication)、负载均衡(Load Balancing)。
四、高并发IO的优化策略
- 减少IO操作
- 合并小IO请求为批量请求。
- 使用批量写入(Batch Write)减少磁盘访问次数。
- 异步化
- 将耗时的IO操作异步化,避免阻塞主线程。
- 例如:使用异步HTTP客户端(如
aiohttp)处理网络请求。
- 资源隔离
- 为不同类型的请求分配独立的资源池,避免资源争用。
- 例如:为数据库连接、线程池设置合理的上限。
- 监控与调优
- 使用监控工具(如Prometheus、Grafana)实时观察系统性能。
- 根据监控数据调整线程池大小、缓存策略等参数。
五、高并发IO的实践案例
- 电商秒杀系统
- 挑战:高并发读写数据库,可能导致数据库崩溃。
- 解决方案:
- 使用Redis缓存商品库存,减少数据库压力。
- 使用消息队列(如Kafka)异步处理订单请求。
- 实时日志系统
- 挑战:大量日志数据需要快速写入磁盘,同时支持实时查询。
- 解决方案:
- 使用
epoll实现高效的日志收集。 - 将日志存储在分布式文件系统(如HDFS)中,支持水平扩展。
- 使用
- 游戏服务器
- 挑战:大量玩家同时发送和接收游戏状态更新。
- 解决方案:
- 使用UDP协议进行实时通信,减少延迟。
- 使用状态同步机制,减少网络带宽占用。
六、总结
- 高并发IO的核心:在保证高并发的同时,优化IO性能,减少延迟。
- 关键技术:异步IO、多路复用、非阻塞IO、缓存、分布式系统。
- 优化方向:减少IO操作、异步化、资源隔离、监控与调优。
通过合理设计和优化,系统可以在高并发场景下实现高效、稳定的IO处理
)
笔记250407)




:进阶应用篇——Python 脚本自动化与三维可视化)




)
)
)




