1.1.1 最主流的开源模型?
ChatGLM-6B[1] prefix LM

LLaMA-7B[2] causal LM

1.1.2 prefix LM和causal LM的区别?
1.1.2.1 Prefix LM
Prefix LM,即前缀语言模型,该结构是Google的T5模型论文起的名字,望文知义来说,这个模型的”前缀”有些内容,但继续向前追溯的话,微软的UniLM已经提及到了。前缀指的是输入序列中的一部分已知内容,通常用来为模型提供上下文信息,以便生成后续内容。具体来说,前缀就是模型在生成过程中已经处理的那一部分序列,为后续生成提供条件和指导。
Prefix LM其实是Encoder-Decoder模型的变体,为什么这样说?解释如下:
(1) 在标准的Encoder-Decoder模型中,Encoder和Decoder各自使用一个独立的Transformer
( 2) 而在Prefix LM,Encoder和Decoder则共享了同一个Transformer结构,在Transformer内部通过Attention Mask机制来实现。
与标准Encoder-Decoder类似,Prefix LM在Encoder部分采用Auto Encoding (AE-自编码)模式,即前缀序列中任意两个token都相互可见。在自编码过程中,模型学习到的隐藏表示保留了输入数据中的主要特征。在这个过程中,模型需要访问所有输入数据,以便找到数据中的整体结构和相关性。因此,AE模式下的模型可以看到输入数据中的所有内容。
在自然语言处理中,假设有一个前缀序列 X = [x1, x2, x3, ..., xn]。在AE模式下,序列中的每个token(如x2)可以访问整个前缀 X,即可以看到其他token的信息。这不同于自回归模式中的单向性约束(只能看到前面的token),AE模式是双向的。
而Decoder部分采用Auto Regressive (AR-自回归)模式,即待生成的token可以看到Encoder侧所有token(包括上下文)和Decoder侧已经生成的token,但不能看未来尚未产生的token。
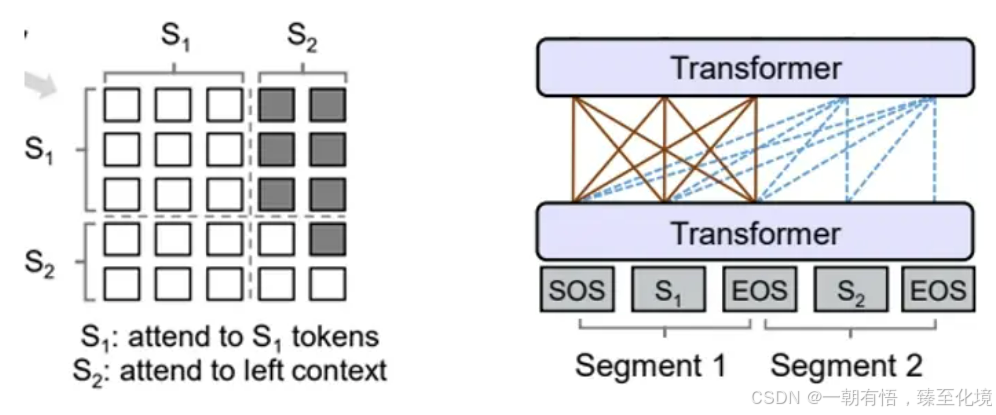
Prefix LM的AttentionMask机制(左)及流转过程(右)


Prefix LM的代表模型有UniLM、T5、GLM(清华滴~)
1.1.2.1.1 Auto Enconding(AE-自编码)
自编码器(AutoEncoder)是一种无监督的模型结构,其用途广泛,可用于特征提取,异常检测,降噪等。
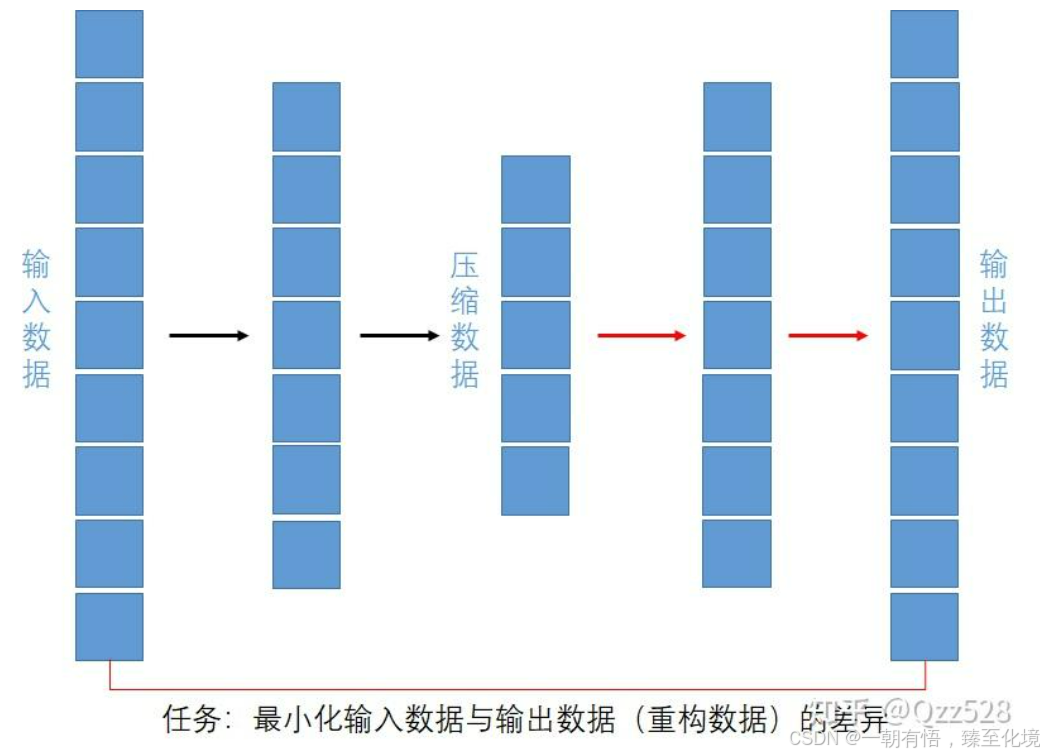
自编码器的基本结构是编码器encoder与解码器decoder,其中编码器对输入的原始数据进行压缩(降维),解码器对压缩后的数据进行重构,将压缩数据还原为原始数据。整体其类似沙漏形状。
自编码器的编码器encoder与解码器decoder多用串联的全连接层构成,如下图:
-
其中黑色箭头为构成编码器encoder的全连接层,多个全连接层逐步将数据维度降低 到指定维度;红色箭头为构成解码器decoder的全连接层,多个全连接层逐步将压缩数据维度增加到 原始维度。一般来说编码器与解码器的结构是对称的。
-
特别的,编码器,解码器内部的层不必为全连接层,卷积层或循环层也可以。
-
-
训练中,该模型的输入为原始数据。因为模型的功能是对输入的数据进行压缩与重构,所以期望的输出应该和原始的输入数据越接近越好。我们以两者的差异为衡量的损失函数(差异可以使用binary交叉熵或者均方误差等),进行模型内部参数的优化。
-
输出是原始数据,模型的输出结果也是与原始数据对比差异,全程只用到了原始数据本身,不需要额外的信息。
-
https://zhuanlan.zhihu.com/p/625085766 代码实例链接
1.1.2.1.2 Auto Regressive(AR-自回归)

1.1.2.2 Causal LM
Causal LM是因果语言模型,目前流行的大多数模型都是这种结构,别无他因,因为GPT系列模型内部结构就是它,还有开源界的LLaMa也是。
Causal LM只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式,直白地说,就是根据历史的token来预测下一个token,也是在Attention Mask这里做的手脚。

CausalLM的Attention Mask机制(左)及流转过程(右)
1.1.2.3 结论
attention mask不同,前者的prefix部分的token互相能看到,后者严格遵守只有后面的token才能看到前面的token的规则。
1.1.3 哪种架构是主流?
GPT系列就是Causal LM,目前除了T5和GLM,其他大模型基本上都是Causal LM。
1.1.4 说一下LLM常见的问题?
出现复读机问题。比如:ABCABCABC不断循环输出到max length。
对于这种现象我有一个直观的解释(猜想):prompt部分通常很长,在生成文本时可以近似看作不变,那么条件概率 P(B|A)也不变,一直是最大的。
固定的 Prompt 和最大条件概率:生成内容的过程中,大语言模型通常会保持给定的 prompt 和上下文不变。这意味着在生成每个新 token 时,模型会基于一个不变的历史内容进行预测。这时候,条件概率 P(B∣A)就倾向于稳定在某种模式下。例如,模型生成了一个短句 ABC,而模型预测下一部分最有可能是同样的 ABC 时,它就可能陷入这种循环,生成 ABCABCABC。
生成内容的高概率反馈循环:由于模型的目标是最大化生成内容的概率,它自然会倾向于在「看起来高概率的句子模式」中停留,尤其是在 prompt 固定且上下文信息较少的情况下。简单来说,重复的句子和结构成为了“高概率”选择,使得模型不断选择生成同样的内容。这可以类比为「陷入一个局部最优解」——模型在 ABCABC 的重复中找到了最高的概率分布,便难以跳脱出来。
生成重复内容,是语言模型本身的一个弱点,无论是否微调,都有可能出现。并且,理论上良好的指令微调能够缓解大语言模型生成重复内容的问题。但是因为指令微调策略的问题,在实践中经常出现指令微调后复读机问题加重的情况。
另外,可能出现重复用户问题的情况,原因未知。
1.1.5 如何缓解复读机问题
1.1.5.1 do_sample:启用随机采样
-
作用:在常规解码中,模型通常会选择概率最高的下一个 token(greedy search),这可能导致高频短语的重复。
do_sample=True则允许模型随机从多个可能的 token 中选择,使生成更具多样性。 -
影响:在启用
do_sample后,模型不再只选取最高概率的 token,而是通过引入随机性选择下一个 token,这可以打破不断循环的高概率模式。这样,生成的内容不再严格依赖于每一步的最高概率,使得模型可以探索更广泛的输出空间。 -
潜在问题:采样过度可能会导致内容的连贯性下降,生成的文本变得不相关。因此,
do_sample通常需要配合其他参数(例如temperature和top-k)进行细致的调节,以保证内容的质量。
1.1.5.2. temperature:温度系数
-
作用:
temperature控制采样的「随机性」。当temperature=1.0时,模型按照默认概率分布进行采样;temperature<1.0时,概率分布变得更尖锐,模型更倾向于选取高概率的 token;而temperature>1.0会使分布变得更平缓,使得低概率的 token 也有较高的可能被选中。 -
实践应用
-
当复读问题严重时,可以适当提高
temperature,例如调至 1.2 或 1.5,使模型不再过于“保守”地生成高概率短语。 -
如果
temperature设得太高(如 >2),会引入极端随机性,使文本变得混乱,生成的内容缺乏连贯性和逻辑。 -
推荐的设置范围:在 1.0 至 1.5 之间微调,既可以提升生成的多样性,又保持一定的逻辑。
-
1.1.5.3. repetition_penalty:重复惩罚
-
作用:
repetition_penalty用来在解码过程中对已经生成的词或短语施加惩罚,以降低重复生成的概率。例如,repetition_penalty=1.2时,模型会对每个重复出现的词或短语施加 1.2 倍的惩罚,减少它们再次被选中的可能性。 -
设置过大时的副作用:如果惩罚设置过大(例如 >2),模型会过度避免任何形式的重复,包括词语的自然重复和标点符号的使用,导致生成的内容缺乏基本的语言结构。例如,“.” 和 “,” 等标点符号可能无法正常出现,使句子结构混乱。
-
合理设置:通常建议在 1.1 到 1.5 之间设定
repetition_penalty,在保持一定惩罚的同时不影响自然语言的流畅度。
1.1.5.4. 组合使用 do_sample、temperature 和 repetition_penalty
在实际应用中,这些参数往往要结合使用,以达到较好的效果。以下是一些常用的组合技巧:
-
解决复读问题的常用组合
-
启用
do_sample,将temperature设置为 1.2 左右,增加随机性,同时将repetition_penalty设置在 1.1-1.3 范围内,适度惩罚重复短语。
-
-
过度随机性问题的解决:如果发现
do_sample使生成内容变得过于随机,降低temperature到 1.0 左右,或者将repetition_penalty调低,减少对低概率词的过度采样。
这种组合方法通常会在减少复读现象的同时,维持生成内容的连贯性和自然性。
1.1.6 llama 输入句子长度理论上可以无限长吗?
以 LLaMA 为代表的许多现代大语言模型,采用了 相对位置编码(ROPE),理论上可以处理无限长度的序列。这种编码方式不固定于某一个具体位置,而是根据每个 token 相对于其他 token 的距离来计算,这使得模型在结构上没有长度限制。因此,模型确实在构架上可以生成极长的文本。
但问题在于:大多数模型的训练数据通常包含长度不超过一定范围(比如 2K 或 4K tokens)的序列。如果训练过程中很少看到长于这个范围的文本,模型在推理时生成超过训练长度的文本效果就会明显下降。这种情况类似于模型在“没有见过的情境”下工作,即 缺乏“长度外推性”。
1.1.6.1 RoPE
1.1.6.1.1. 关于RoPE
RoPE(Rotary Position Embedding),是苏剑林大神在2021年就提出的一种Transformer模型的位置编码。RoPE是一种可以以绝对位置编码形式实现的相对位置编码,兼顾了模型性能和效率。
2023年上半年的时候,大模型位置编码尚有Alibi和RoPE在相互比拼,而到了2023年下半年,及今2024年,新开源出来的模型,大部分都是使用RoPE了。当然Alibi也有其优势,这个在讲Alibi的时候来说。
苏神在他的个人网站科学空间中对RoPE有相关文章进行了介绍,本篇是在这个基础上,对RoPE进行理解(公式和符号上也会沿用苏神的写法)。
1.1.6.1.2. 以绝对位置编码的方式实现相对位置编码
前面提到,RoPE是一种一绝对位置编码的方式实现的相对位置编码,那么这么做能带来什么收益?
先说原因:
在文本长度不长的情况下(比如Bert时代基本都是256/512token的长度),相对位置编码和绝对位置编码在使用效果上可以说没有显著差别。 如果要处理更大长度的输入输出,使用绝对位置编码就需要把训练数据也加长到推理所需长度,否则对于没训练过的长度(训练时没见过的位置编码),效果多少会打些折扣。 而使用相对位置编码则更容易外推,毕竟token-2和token-1的距离,与token-10002和token-10001的距离是一样的,也因此可以缓解对巨量长文本数据的需求。 但是传统相对位置编码的实现相对复杂,有些也会有计算效率低的问题。由于修改了self-attention的计算方式,也比较难推广到线性注意力计算法模型中。 总结来说,就是绝对位置编码好实现,效率高,适用线性注意力,而相对位置编码易外推,因此就有了对“绝对位置编码的方式实现相对位置编码”的追求,去把二者的优点结合起来。








:材质和Effect的了解)



)






