前言
上篇我们学会的文本文件、csv文件和excel文件的相关基础知识和操作,这一次我们再来了解一下四个文件操作方式
存储方法
HTML文件
将数据保存为HTML格式,可以直接在浏览器中查看。
使用字符串拼接将数据保存为HTML格式。
代码案例
# 创建数据列表
data = [{'name': 'Alice', 'age': 25, 'city': 'New York'},{'name': 'Bob', 'age': 30, 'city': 'San Francisco'},# 其他数据行
]# 构建 HTML 内容
html_data = "<h1>Users</h1>\n"
for item in data:html_data += "<div>\n"for key, value in item.items():html_data += f" <p>{key}: {value}</p>\n"html_data += "</div>\n"# 将HTML内容写入文件
with open('data.html', 'w', encoding='utf-8') as f:f.write(html_data)
输出结果
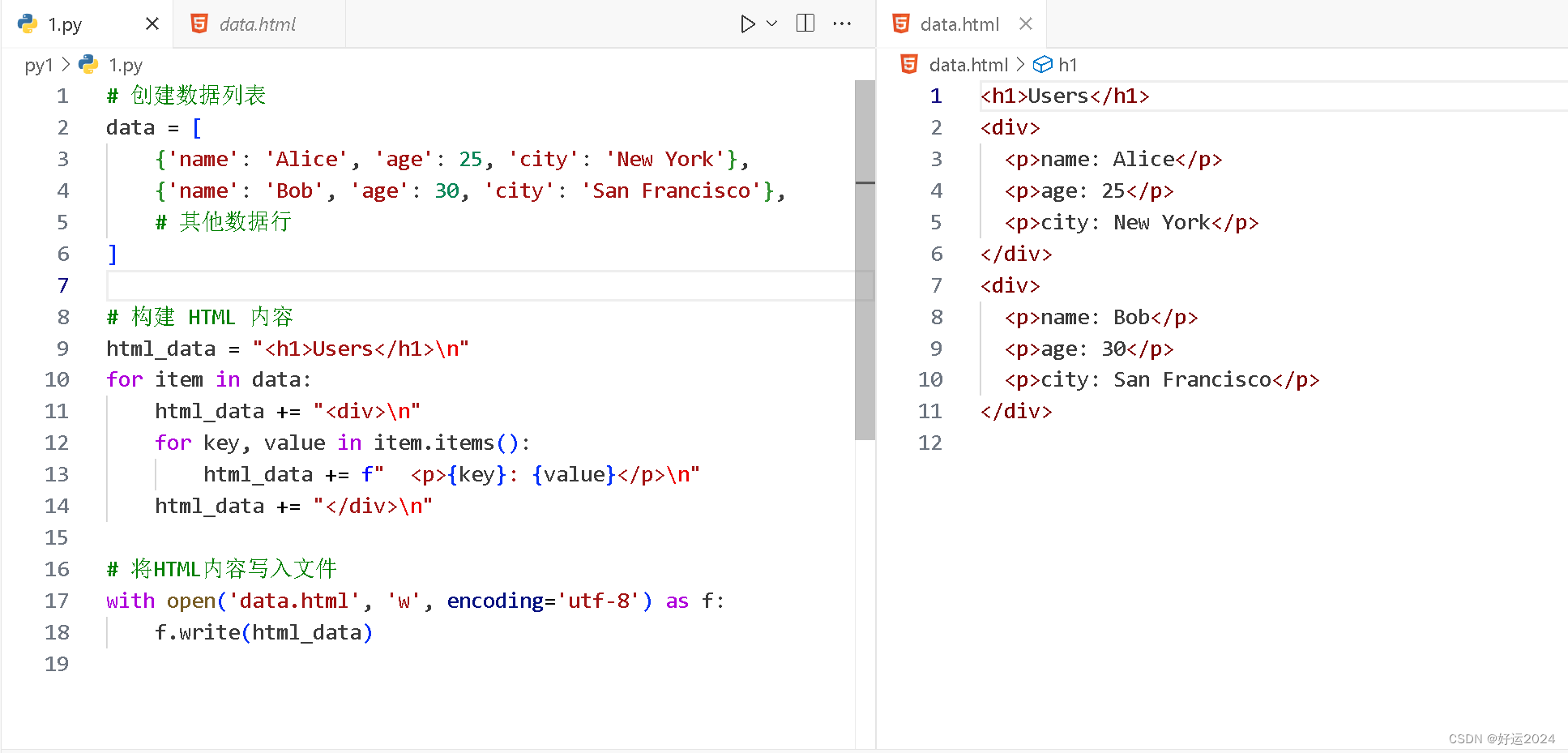
代码解释(解释较难的代码)
1.初始化一个名为 html_data 的字符串,它将用来存储最终的HTML内容。首先添加一个 <h1> 标签,表示一级标题,标题文本为 "Users"。
html_data = "<h1>Users</h1>\n"2.开始一个 for 循环,遍历 data 列表中的每个字典(即每个用户的信息)。
for item in data:3.对于每个用户,html_data 字符串会追加一个新的 <div> 标签,用来包裹该用户的详细信息。
html_data += "<div>\n"4.在这个 <div> 内部,开始另一个 for 循环,遍历当前用户字典 item 中的每个键值对。
for key, value in item.items():5.对于每个键值对,html_data 字符串会追加一个带有格式化文本的 <p> 标签。这里使用了格式化字符串字面量(f-string),将键(key)和值(value)插入到 <p> 标签的文本中,并以冒号分隔。
html_data += f" <p>{key}: {value}</p>\n"6.在添加完当前用户的所有信息后,html_data 字符串会追加一个 </div> 标签来关闭 <div>。
html_data += "</div>\n"JSON文件
以JSON格式保存数据,易于阅读和跨语言交换数据。
使用json模块将数据保存为JSON格式。
代码案例
import json
data = {"name": "John", "age": 30, "city": "New York"}
with open('data.json', 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)输出结果
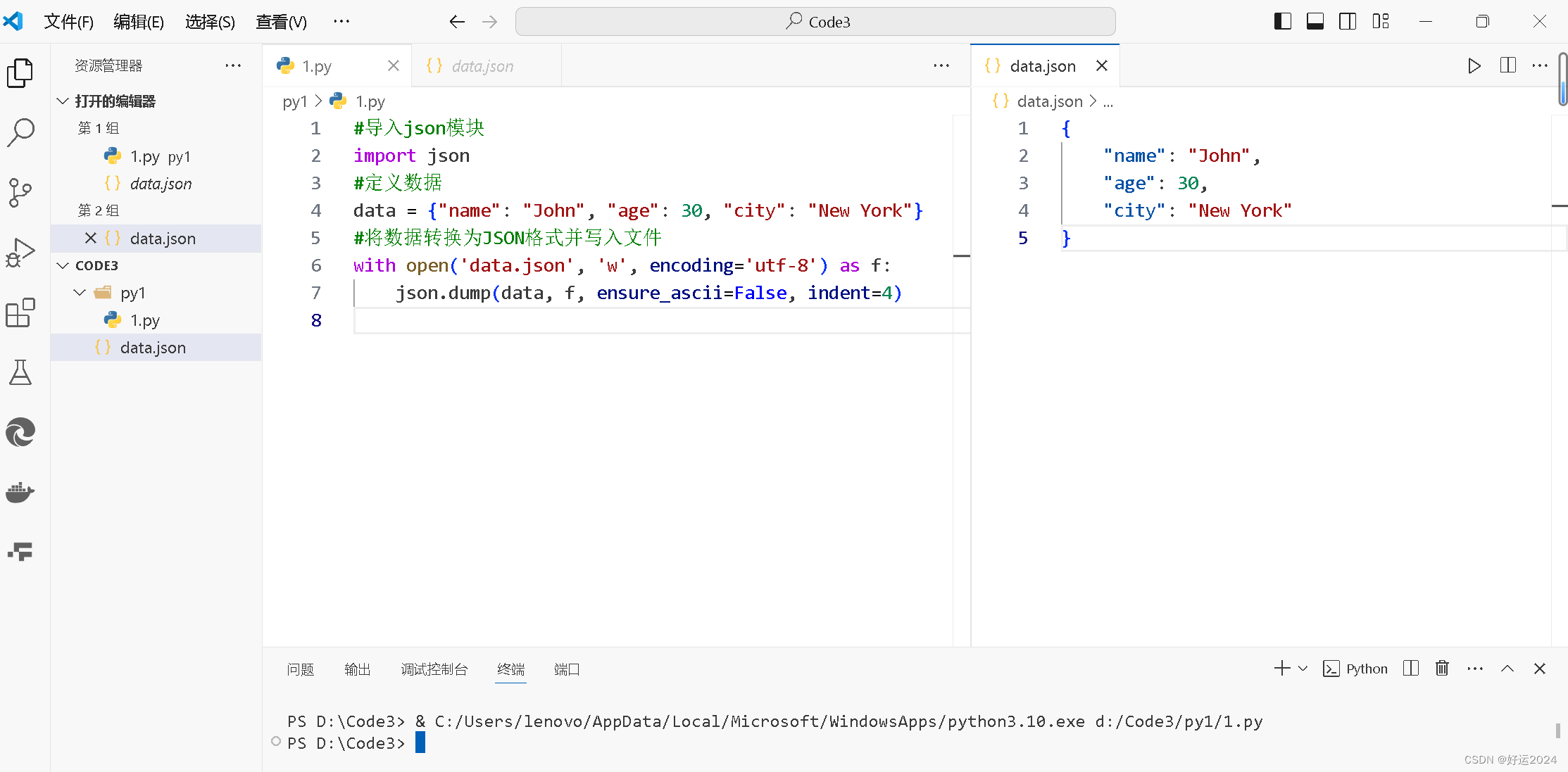
代码解释
1.导入json模块:
import json这行代码从Python标准库中导入了json模块,该模块用于处理JSON数据。
2.创建字典数据:
data = {"name": "John", "age": 30, "city": "New York"}这里创建了一个名为data的字典,包含了键值对:"name"对应"John","age"对应30,"city"对应"New York"。
3.打开文件:
with open('data.json', 'w', encoding='utf-8') as f:使用with语句打开一个名为data.json的文件,用于写入操作:
'data.json'是文件的名称。'w'表示写入模式,如果文件已存在,它会被覆盖;如果不存在,将会创建一个新文件。encoding='utf-8'确保文件以UTF-8编码保存,这对于包含非ASCII字符的数据很重要。
4.使用json.dump()写入JSON数据:
json.dump(data, f, ensure_ascii=False, indent=4)json.dump()函数用于将Python对象转换为JSON格式的字符串,并写入到指定的文件中:
data是要转换为JSON格式的字典对象。f是文件对象,即上面打开的data.json文件。ensure_ascii=False指示json.dump()允许输出非ASCII字符,而不是将它们转义为\uXXXX形式。indent=4指定了输出的缩进级别,使得JSON文件具有可读性,每个层级缩进4个空格。
整个代码块的作用是创建一个包含个人信息的字典,并将其以格式化的JSON格式保存到文本文件中。这种格式的文件易于阅读和处理,常用于数据交换和配置文件。
XML文件
可扩展标记语言,适合存储结构化数据。
使用xml.etree.ElementTree模块将数据保存为XML格式。
代码案例
#导入ElementTree模块
import xml.etree.ElementTree as ET
# 创建数据列表
data = [{'name': 'Alice', 'age': 25, 'city': 'New York'},{'name': 'Bob', 'age': 30, 'city': 'San Francisco'}
]
#创建根元素
root = ET.Element('users')
# 遍历数据列表,创建子元素
for item in data:user = ET.SubElement(root, 'user') # 创建子元素# 遍历字典,创建属性子元素for key, value in item.items():# 创建属性子元素ET.SubElement(user, key).text = str(value)
# 写入XML文件
tree = ET.ElementTree(root)
tree.write('data.xml', encoding='utf-8', xml_declaration=True)
输出结果
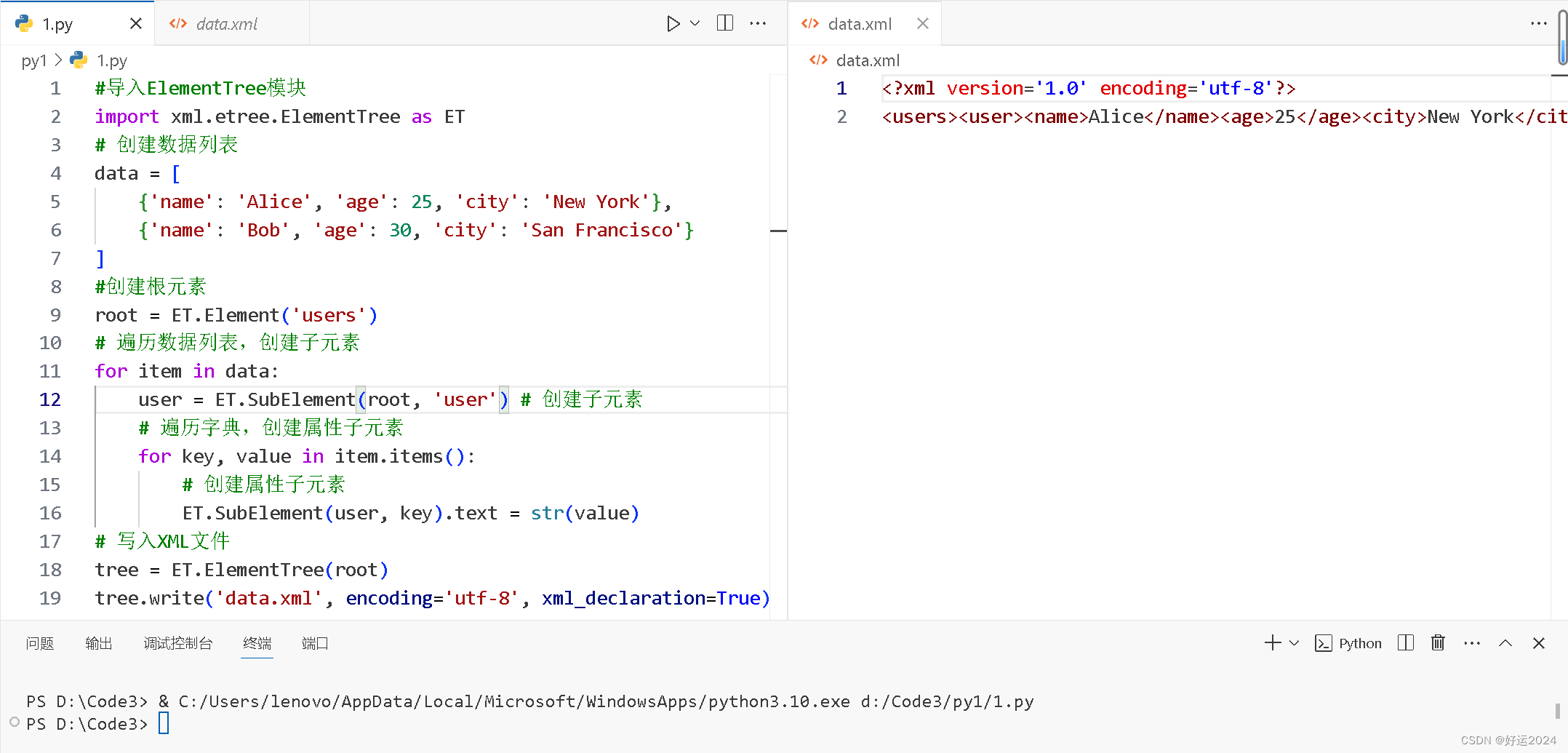
数据库文件
使用关系型数据库(如MySQL、PostgreSQL)或非关系型数据库(如MongoDB)存储结构化数据。
使用sqlite3模块将数据保存到SQLite数据库中。
代码案例
import sqlite3#导入sqlite3模块conn = sqlite3.connect('data.db')#连接到数据库
cursor = conn.cursor()#创建游标
#创建users表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (name TEXT,age INTEGER,city TEXT
)
''')
#插入数据
data = ('John', 30, 'New York')
#?占位符,防止SQL注入攻击
cursor.execute('INSERT INTO users VALUES (?, ?, ?)', data)
conn.commit()#提交事务
cursor.close()#关闭游标
conn.close()#关闭连接输出结果
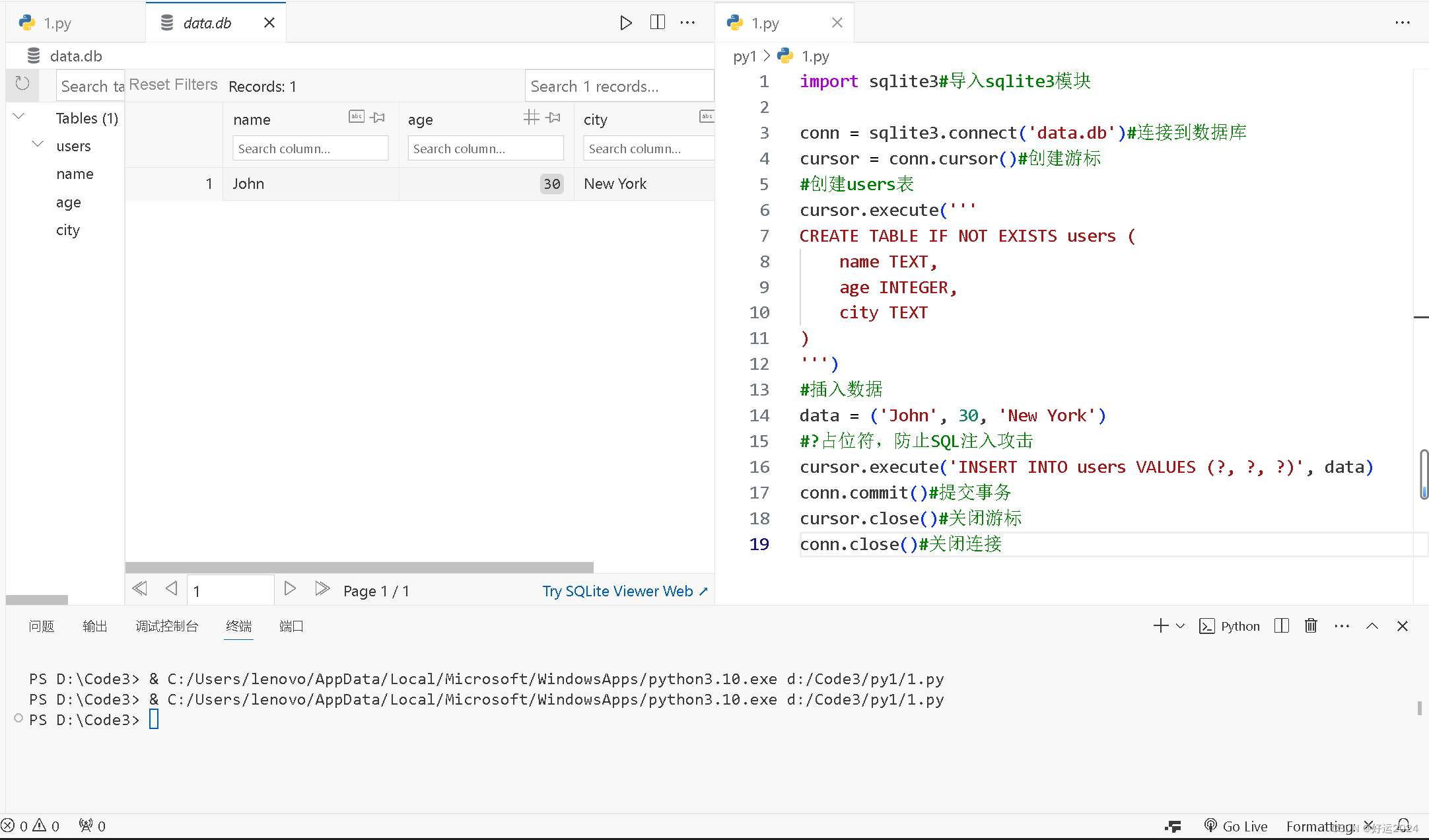
好了,今日分享到此一游,我是好运,想要好运。













的区别)



)
)
