Agentic RAG 架构
Agentic RAG 架构的基本原理
在大模型领域技术的发展历程中,提高信息检索的效率和准确性是各行各业都在急需解决的应用难题。在前几年技术地位的是检索增强生成 (RAG)技术,通过将大模型 ( LLMs ) 与外部数据检索相集成,彻底改变了人工智能系统,从而可以做出更明智、上下文更准确的响应。
然而,随着需求变得更加复杂,传统的RAG系统逐渐显露出局限性,难以应对那些需要精细解析、多步推理以及动态调整上下文的高要求任务。正是在这样的背景下,Agent技术在工作流程优化上取得了突破性进展,进而催生了我们今天要探讨的技术——代理检索增强生成(Agentic RAG),这是对原有RAG模式的一次创新性升级。
Agentic RAG的独特之处在于引入了智能且自主的Agent机制到检索流程之中,极大地增强了系统的适应性、推理能力和响应速度。这些代理不再是简单的信息抓取者,而是转变为积极的决策者,它们能够主动规划策略、做出判断,并灵活运用各类专业工具来达成目标。
1. 什么是RAG?
Retrieval-Augmented Generation (RAG) 是帮助大模型更好地回答问题的一种方式。在大模型的应用场景中,一个非常常见的需求是:我们手里有一堆文档,当遇到一个问题时,希望通过其中的一段文本来找到答案。这时,RAG(检索增强生成)技术就能派上用场。它的作用就是从这些文档中找到最相关的信息,然后利用大模型生成精准的回答。简单来说,RAG 就是帮助大模型‘找到’并‘利用’最相关的信息来回答你的问题,就像一个聪明的助手快速翻阅资料给你最合适的答案。如下图所示:
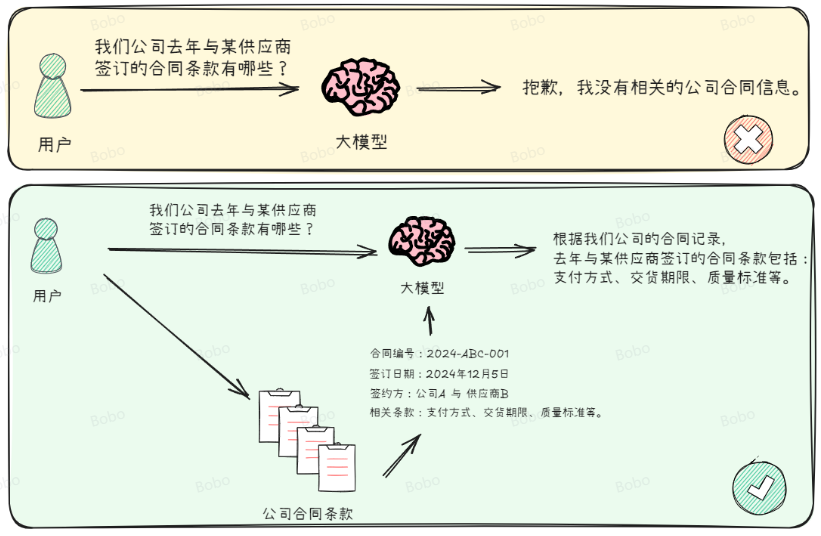
能这样实现的原因在于已经有非常多的实验论文能够证明,当为大模型提供一定的上下文信息后,其输出会变得更稳定。那么,将知识库中的信息或掌握的信息先输送给大模型,再由大模型服务用户,就是大家普遍达成共识的一个结论和方法。传统的对话系统、搜索引擎等核心依赖于检索技术,如果将这一检索过程融入大模型应用的构建中,既可以充分利用大模型在内容生成上的能力,也能通过引入的上下文信息显著约束大模型的输出范围和结果,同时还实现了将私有数据融入大模型中的目的,达到了双赢的效果。
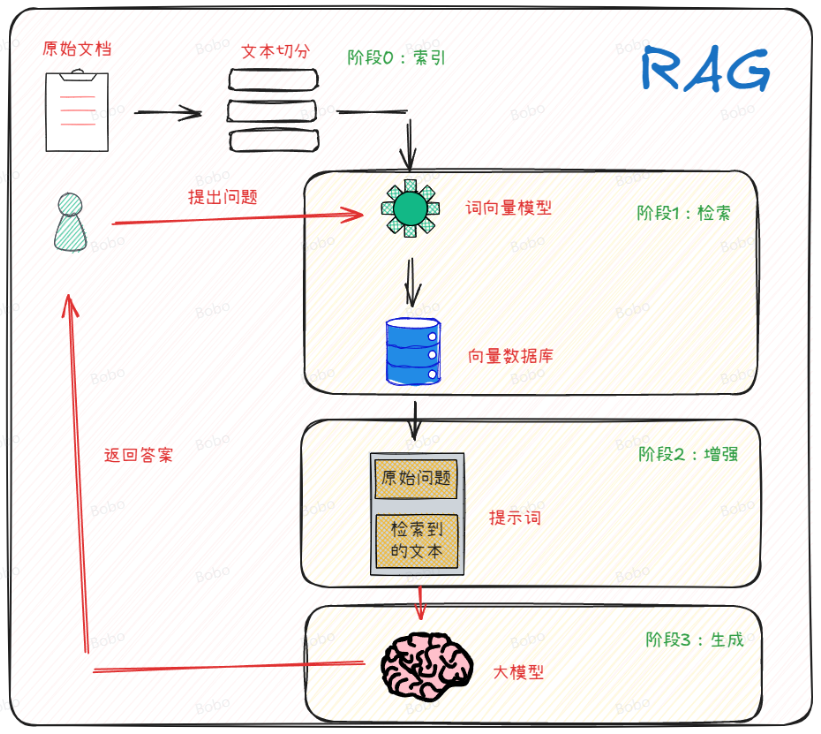
从技术实现细节上看,RAG的实现是包括3个主要阶段的:检索阶段、增强阶段和生成阶段。在检索阶段,从知识库中找出与问题最相关的知识,为后续的答案生成提供素材。在增强阶段可以将检索到的内容作为模型的上下文信息。在生成阶段,RAG会将检索到的知识内容作为输入,与问题一起输入到语言模型中进行生成。这样,生成的答案不仅考虑了问题的语义信息,还考虑了相关私有数据的内容。如下图所示:
2. 什么是 AI Agent?
AI Agent 整个过程是一个动态循环。Agent不断从环境中学习,通过其行动影响环境,然后根据环境的反馈继续调整其行动和策略。这种模式特别适用于那些需要理解和生成自然语言的应用场景,如聊天机器人、自动翻译系统或其他形式的自动化客户支持。
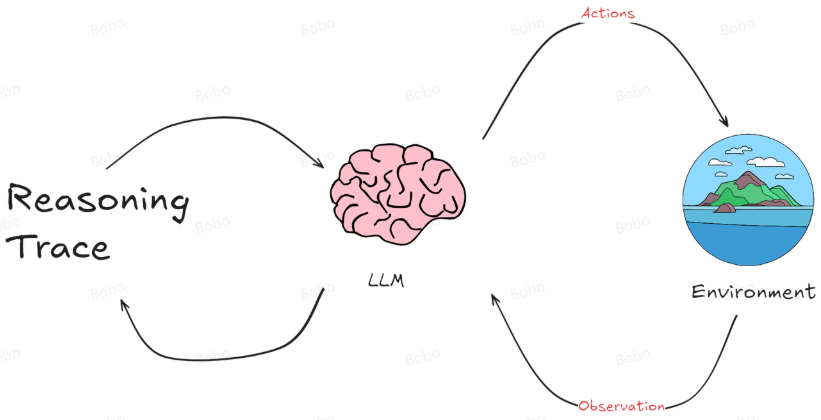
而一个智能体的基础架构主要涉及与环境的交互、感知输入、内部处理及决策过程等关键环节。
在众多技术理念中,ReAct思想颇具影响力。采用ReAct模式的Agent代理能够有序处理多步骤的复杂查询任务,并且通过整合路由选择、查询规划以及工具使用等功能于一体,在内存中维护状态信息,实现高效的任务处理流程。例如,在复杂的科研数据分析场景中,ReAct代理可以先确定数据来源(路由),规划分析步骤(查询规划),再运用合适的数据处理工具进行分析计算,最终得出准确的研究结论。ReAct 使智能体能够动态地在产生想法和特定于任务的行动之间交替。
ReAct 框架有两个过程,由 Reason 和 Act 结合而来。从本质上讲,这种方法的灵感来自于人类如何通过和谐地结合思维和行动来执行任务,就像“我想去北京旅游”这个真实示例一样。
首先第一部分 Reason,它基于一种推理技术——思想链(CoT), CoT是一种提示工程,通过将输入分解为多个逻辑思维步骤,帮助大语言模型执行推理并解决复杂问题。这使得大模型能够按顺序规划和解决任务的每个部分,从而更准确地获得最终结果,具体包括:
- 分解问题:当面对复杂的任务时,CoT 方法不是通过单个步骤解决它,而是将任务分解为更小的步骤,每个步骤解决不同方面的问题。
- 顺序思维:思维链中的每一步都建立在上一步的结果之上。这样,模型就能从头到尾构造出一条逻辑推理链。
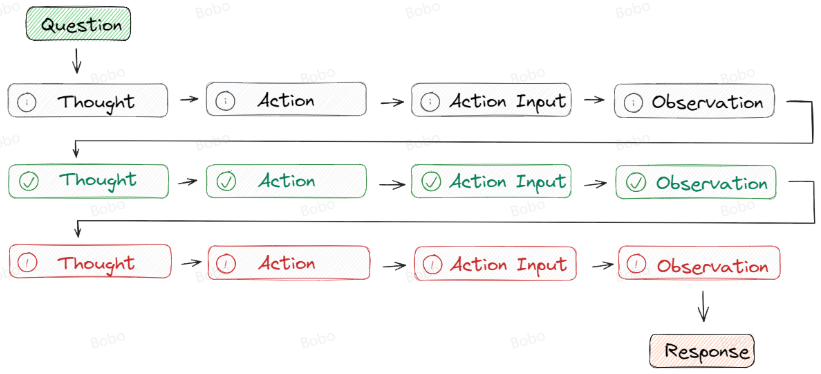
但是,在 CoT 提示工程的限定下,大模型仍然会产生幻觉。因为经过长期的使用,大家发现在推理的中间阶段会产生不正确的答案或上下游的传播错误,所以,Google DeepMind 团队开发了ReAct的技术来弥补这一点。ReAct 采用的是 思想-行动-观察循环的思路,其中代理根据先前的观察进行推理以决定行动。这个迭代过程使其能够根据其行动的结果来调整和完善其方法。如下图所示:
3. Agentic RAG
Agentic RAG(Agent-based Retrieval-Augmented Generation)是指在传统的 RAG(Retrieval-Augmented Generation)框架中引入了 Agent(智能体)作为核心组件的变体。在标准的 RAG 系统中,主要是通过检索相关文档或信息来增强生成模型的能力,而 Agentic RAG 则通过集成一个智能体,帮助系统在搜索和生成过程中进行更智能的决策和交互。
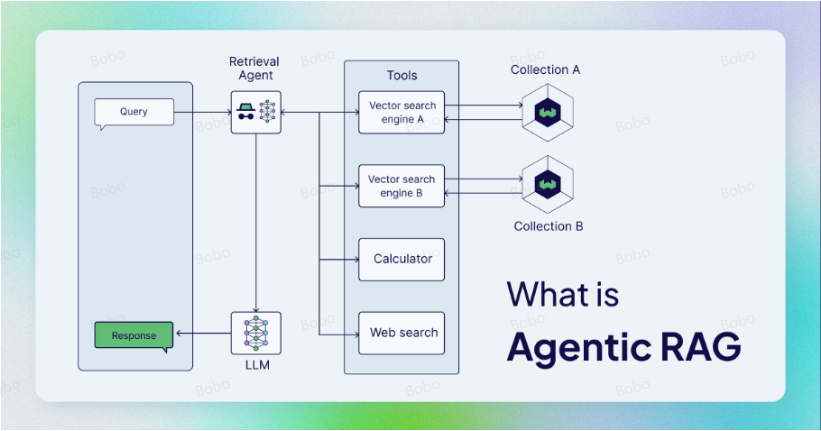
具体来说:Agentic就是将 AI Agent合并到 RAG 中,以编排其组件并执行简单信息检索和生成之外的其他操作。
下面,我们就使用Agentic RAG结合streamlit实现一个问答系统:
如下代码需要依赖的环境有:langchain、streamlit
#下述代码需要复制到一个py文件中,然后在cmd里基于streamlit run xxx.py的指令进行执行
import streamlit as st
import tempfile #创建临时文件和目录,并提供了自动清理这些临时文件和目录的机制,以避免占用不必要的磁盘空间
import os
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain_community.document_loaders import TextLoader
from langchain_openai import ChatOpenAI
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.agents import create_react_agent, AgentExecutor
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import BaichuanTextEmbeddings# 设置Streamlit应⽤的⻚⾯标题和布局
st.set_page_config(page_title="Rag Agent", layout="wide")# 设置应⽤的标题
st.title("Rag Agent")#上传txt⽂件,允许上传多个⽂件
uploaded_files = st.sidebar.file_uploader(label="上传txt⽂件", type=["txt"], accept_multiple_files=True
)
# 如果没有上传⽂件,提示⽤户上传⽂件并停⽌运⾏
if not uploaded_files:st.info("请先上传按TXT⽂档。")st.stop()#实现检索器函数封装:文件读取、分块、向量转换、向量数据库、MMR信息检索
'''
@st.cache_resource(ttl="1h") 是 Streamlit 框架中的一个装饰器,用于缓存资源(如数据文件、数据库连接等)以提高性能和效率。具体来说,这个装饰器会将函数的返回值缓存一段时间(在这里是1小时),以避免在每次调用时都重新加载或计算相同的资源。
'''
@st.cache_resource(ttl="1h")
def configure_retriever(uploaded_files):docs = [] #存储用户上传文件的文件内容(字符串)#创建临时文件和目录temp_dir = tempfile.TemporaryDirectory(dir=r"D:\\")for file in uploaded_files:temp_filepath = os.path.join(temp_dir.name, file.name)with open(temp_filepath, "wb") as f:f.write(file.getvalue())# 使用TextLoader加载文本文件loader = TextLoader(temp_filepath, encoding="utf-8")docs.extend(loader.load())# 进行文档分割text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)splits = text_splitter.split_documents(docs)# 使用BaichuanTextEmbeddings向量模型生成文档的向量表示key = "sk-83cxxxx6f95d"embeddings = BaichuanTextEmbeddings(api_key=key)vectordb = Chroma.from_documents(splits, embeddings)# 创建文档检索器retriever = vectordb.as_retriever()#返回检索器对象return retriever# 配置检索器:调用检索器函数,返回MMR检索器对象
retriever = configure_retriever(uploaded_files)# 如果session_state中没有消息记录或用户点击了清空聊天记录按钮,则初始化消息记录
if "messages" not in st.session_state or st.sidebar.button("清空聊天记录"):st.session_state["messages"] = [{"role": "assistant", "content": "您好,我是AI智能助手,我可以查询文档"}]# 加载历史聊天记录
for msg in st.session_state.messages:st.chat_message(msg["role"]).write(msg["content"])# 下一步工作就是将文档检索作用在Agent对象中。创建Agent时需要让其对多轮对话具备上下文记忆能力
# 创建用于文档检索的工具
'''create_retriever_tool:功能:创建具体的检索工具实例用途:从文档库中检索信息典型场景:问答系统、文档搜索langchain.agents.Tool:功能:定义工具的通用接口用途:自定义工具或扩展工具功能典型场景:创建自定义工具或扩展现有工具
'''
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(retriever = retriever,name = "文档检索",description = "用于检索用户提出的问题,并基于检索到的文档内容进行回复.",
)
tools = [tool]# 创建聊天历史管理工具(对话链)
'''
StreamlitChatMessageHistory 是一个专为 Streamlit 应用设计的聊天历史管理工具,适用于需要保存和管理对话上下文的场景。
支持实时更新聊天历史,并在界面上动态显示。
'''
msgs = StreamlitChatMessageHistory()
# 创建对话缓冲区
'''
参数介绍:chat_memory:指定初始的对话历史记录。 用于加载已有的对话历史,以便在后续对话中参考之前的上下文。return_messages:控制是否在返回结果中包含消息对象。如果设置为 True,则在调用 memory.load_memory() 时,返回的结果中会包含完整的消息对象(包括角色、内容等)。如果设置为 False,则只返回字符串形式的消息的内容。memory_key:指定在内存中存储对话历史的键名。当从内存中加载或保存对话历史时,使用这个键名来标识对话历史。例如,如果内存中存储了多个键值对,可以通过 memory_key 来指定要加载的对话历史。output_key:指定在内存中存储模型输出的键名。当将模型的输出保存到内存中时,使用这个键名来标识输出内容。例如,如果内存中存储了多个键值对,可以通过 output_key 来指定要加载的模型输出。
'''
memory = ConversationBufferMemory(chat_memory=msgs, return_messages=True, memory_key="chat_history", output_key="output"
)# 指令模板
instructions ="""你是一个设计用于查询文档来回答问题的代理对象。
你可以使用文档检索工具,并基于检索内容来回答问题
你可能不查询文档就知道答案,但是你仍然应该查询文档来获得答案。
如果你从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
"""# 基础提示模板-React提示词
base_prompt_template = """
{instructions}TOOLS:
------
You have access to the following tools:
{tools}To use a tool, you MUST strictly follow this EXACT format:Thought: Do I need to use a tool? Yes
Action: the action to take, must be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the actionWhen you have a response to say to the Human, or if you do not need to use a tool, you MUST strictly follow this EXACT format:Thought: Do I need to use a tool? No
Final Answer: [your response here]IMPORTANT RULES:
1. You MUST output EXACTLY one "Thought:" section
2. You MUST output EXACTLY one "Action:" section if using a tool
3. You MUST output EXACTLY one "Final Answer:" section if not using a tool
4. Do NOT add any extra text, explanations, or formatting outside these sectionsBegin!Previous conversation history:
{chat_history}New input: {input}
{agent_scratchpad}"""# 创建基础提示模板
base_prompt = PromptTemplate.from_template(base_prompt_template)
# 创建部分填充的提示模板
prompt = base_prompt.partial(instructions=instructions)# 创建llm
API_KEY = "sk-xxxebb425b3"
llm = ChatOpenAI(model="deepseek-reasoner",openai_api_key=API_KEY,openai_api_base="https://api.deepseek.com")# 创建react Agent
agent = create_react_agent(llm, tools, prompt)# 创建Agent执行器
'''
memory:指定用于存储和管理对话历史的内存对象。用途:- 存储对话历史,包括用户输入和机器人回复。- 在多轮对话中提供上下文,帮助机器人更好地理解用户意图。handle_parsing_errors:控制是否在解析用户输入时自动处理错误。用途:- 如果设置为 True,当用户输入无法被正确解析时,系统会自动尝试修复或忽略错误,而不是直接抛出异常。- 如果设置为 False,系统会在遇到解析错误时抛出异常,可能导致程序中断。
'''
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory, verbose=True, handle_parsing_errors=True)# 创建聊天输入框
user_query = st.chat_input(placeholder="请开始提问吧!")# 如果有用户输入的查询
if user_query:# 添加用户消息到session_statest.session_state.messages.append({"role": "user", "content": user_query})# 显示用户消息st.chat_message("user").write(user_query)#创建一个 Streamlit 的聊天消息块,用于显示助手(机器人)的回复。with st.chat_message("assistant"):# st.container(): 创建一个 Streamlit 的容器组件,用于动态更新内容。#StreamlitCallbackHandler 是 LangChain 的一个回调处理器,用于将模型的输出或日志信息显示在 Streamlit 界面中。通过将 st.container() 传递给 StreamlitCallbackHandler,可以将 LangChain 的输出直接渲染到 Streamlit 的容器中。st_cb = StreamlitCallbackHandler(st.container())# 配置 LangChain 的回调函数列表,将 StreamlitCallbackHandler 添加到回调中。通过配置回调函数,LangChain 可以在处理过程中调用StreamlitCallbackHandler,从而将输出或日志信息显示在 Streamlit 界面中。这种方式可以实现实时更新界面。config = {"callbacks": [st_cb]}# 执行Agent并获取响应response = agent_executor.invoke({"input": user_query}, config=config)# 添加助手消息到session_statest.session_state.messages.append({"role": "assistant", "content": response["output"]})# 显示助手响应st.write(response["output"])


![洛谷 P1203 [USACO1.1] 坏掉的项链 Broken Necklace 题解 最短代码|详细](http://pic.xiahunao.cn/洛谷 P1203 [USACO1.1] 坏掉的项链 Broken Necklace 题解 最短代码|详细)






卷积参数)

)







