论文链接
机构:Improbable AI Lab+MIT
日期:25.09
insight
这篇论文的核心问题是:基础模型(如大语言模型或机器人策略)在微调以适应新任务时,常常出现灾难性遗忘(catastrophic forgetting),即学习新知识会损害先前掌握的能力。论文通过对比监督微调(SFT)和强化学习(RL)微调方法,发现了一个关键洞察:RL在学习新任务时遗忘更少,而SFT则导致显著遗忘,即使两者在新任务上的性能相似。
论文提出,遗忘程度主要由分布偏移决定,具体是通过新任务上微调策略与基础策略之间的KL散度(Kullback-Leibler divergence)来预测。
该定律还阐明了 SFT 与 RL 之间的令人惊讶的差异。我们的分析揭示了一个简单但强大的
原则,我们称之为 RL 的剃刀:在新任务的众多高奖励解中,同策略方法(如 RL)本质上
倾向于选择 KL 散度上更接近原点策略的解。图 1(左)突出了这一效应:在众多能够达到
高成功率的新策略中,RL 倾向于收敛到 KL 极小值解,而 SFT 可以收敛到距离较远的解。
这种偏差直接源于 RL 的 同策略训练:通过在每一步从模型自身的分布中采样,RL 将学习
限制在基础模型已赋予非可忽略概率的输出范围内。为了提升奖励,这些样本被重新加权并
用于更新模型,从而使策略逐渐转移,而非拉向任意分布。因此,当新任务存在多个表现相
当的解时,RL 倾向于找到靠近原策略的解,而 SFT 则可能收敛到与原策略相距甚远的解,
具体取决于所提供的标签。在简化情景下的理论分析进一步证实了这一观点,表明即使没有
显式的正则化,策略梯度方法仍会收敛至 KL 极小值解。
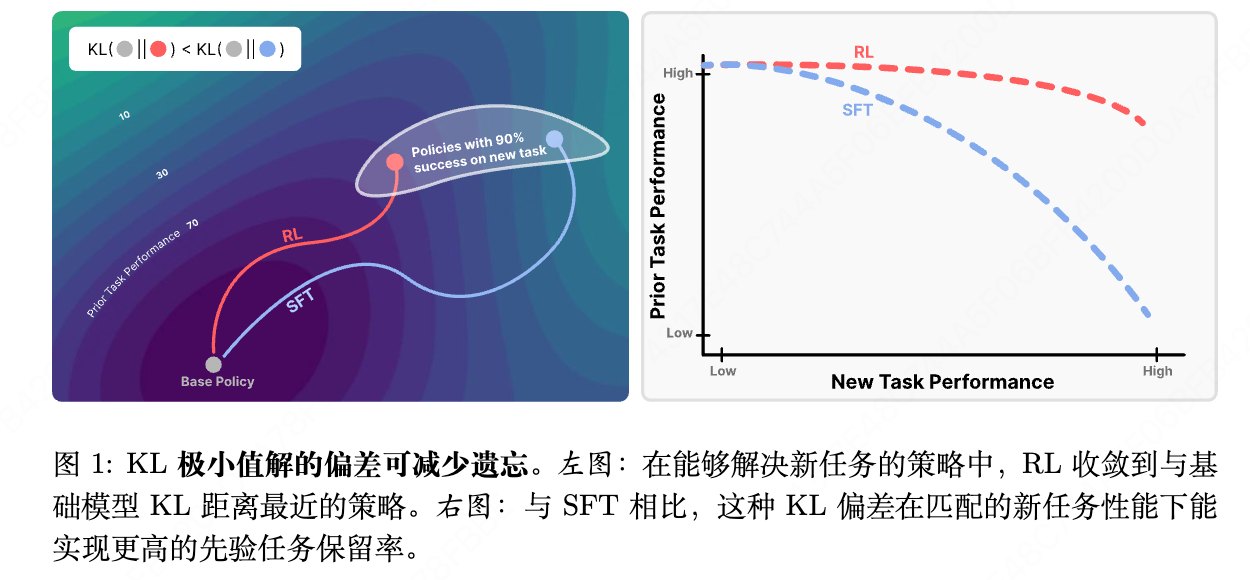
实验1:RL的遗忘学习程度低于SFT
做了若干实验,在训练集相同的情况下,GRPO的遗忘程度总会比sft更低。

实验2:较小的KL散度导致遗忘更少
作者发现,KL散度可以很好的和遗忘程度(在先验数据集中性能的下降程度)拟合。
实验3:同策略方法导致更小的KL散度
作者提出,RL和SFT的区别主要在于:
- RL是on-policy的,而sft是off-policy的
- RL时,存在负例;而SFT时,只有正例
基于此,作者对比了四种方法:
- GRPO
- 1–0 Reinforce:一种同策略算法,不使用错误示例。其中,A(x, y) = 1 表示正确响应,0表示错误响应。这等价于从模型中采样,并仅对正确答案进行 SFT。
- SFT
- SimPO:一种离线优化方法,利用负样本。我们通过从外部模型中采样错误响应来创建负样本,并使用 SFT 数据作为正样本。然后最大化正负样本的概率分布之差。
实验发现:1–0 Reinforce和GRPO的遗忘程度类似;SimPO和SFT的遗忘程度类似,说明主要是同策略方法导致了更小的KL散度,而不是正负例。
此外,作者还提供了理论证明,证明同策略方法等价于收敛到所有可行解中和基础模型KL散度最小的那个。
问题:作者没有对比RFT方法,如果使用RFT的方法,遗忘程度同样很低。
















2026有哪些好用的降ai率工具?亲测5个靠谱平台,这个真能把AI率降下去!)


