3.5.1 局部与全局分配策略 Local versus Global Allocation Policies
当一个进程发生 page fault 需要换出页面时,应当换出这个进程的页面,还是其他进程的页面?
- 局部策略:换出当前进程中最少使用的页面,保持每个进程占用的内存比例固定
- 全局策略:换出整个内存中最少使用的页面,动态调整进程占用的内存比例
一般来说,全局策略的性能更好。
局部策略保持进程的内存不变,但是进程的 working set 是动态变化的,如果 working set 超过进程内存大小,就会导致 trashing,如果 woking set 减少,就会浪费内存。
使用全局策略的话,操作系统必须判断出给每个进程分配多少页帧。
- 通过 aging bits 计算进程需要分配多少内存。
aging bits 可以反馈每个页面的活跃程度,有更多搞活跃度页面的进程应当分配更多的页帧,相反,低活跃度页面较多的进程应当让出一些页帧。
但是 aging bits 的变化周期远大于 working set 的变化时间粒度。aging bits 随时钟中断发生变化,而 working set 可能在几个指令后就发生变化,所以 aging bits 无法及时反馈 working set 的变化,自然无法防止 trashing。
- 周期性统计运行中的进程数量,根据每个进程的内存大小按比例分配页帧。至少分配可以维持进程正常运行的页帧数量。在程序的运行过程中,必须动态更新。
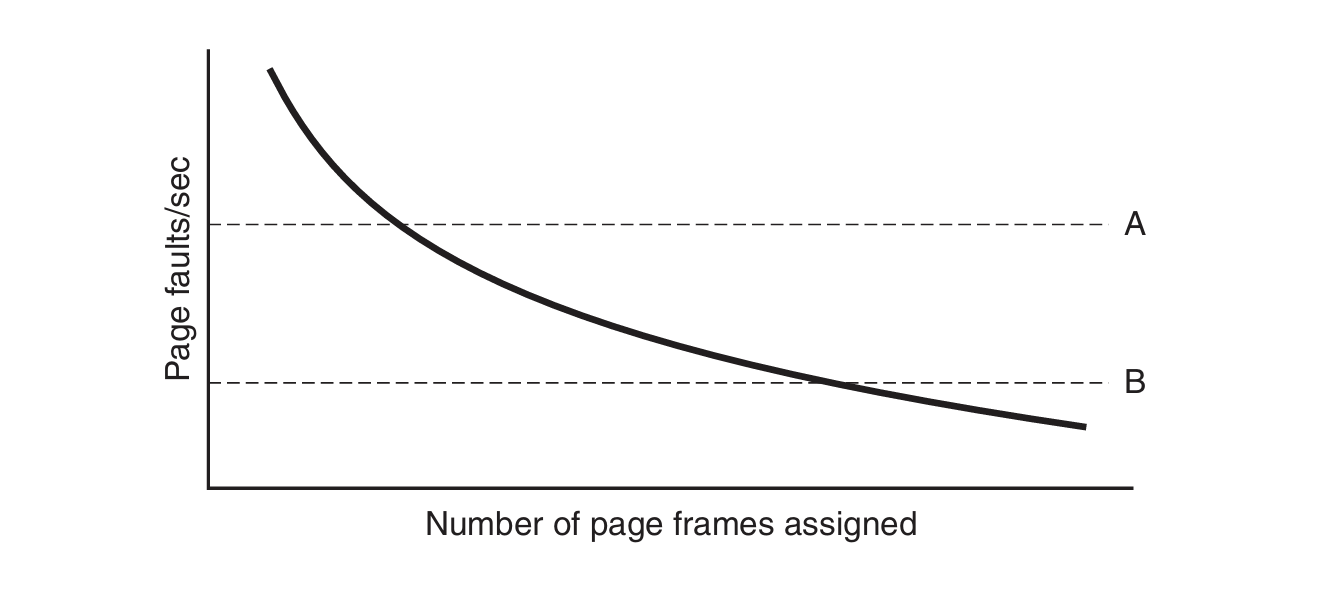
PFF(Page Fault Frequency):单位时间内缺页中断次数,\(pff = \frac{pff_{cur} + pff_{old}}{2}\)
给定一个 pff 的最大值和最小值,超过最大值时,说明当前 page fault 的次数过多,应当增加分配的页帧,可以从 pff 低于最小值的进程那里获取页帧。
适用局部和全局策略的页面替换算法:FIFO, LRU
只适用于局部策略的页面替换算法:Working Set, WSClock
3.5.2 负载控制 Load Control
当所有进程的 working set 总和超过系统的内存时,trash 是不可避免的。只能将一部分进程 swap 到磁盘上,释放他们的页帧给其他进程。
轮流交替将部分进程 swap 到磁盘,再从磁盘 swap 到内存中,确保系统整体的 page fault frequency 可以接受。
在多任务系统中,如果内存中的进程数量太少,部分 CPU 处于闲置状态。在 swap 时考虑进程时 CPU 密集型还是 IO 密集型,以及一些其他特性。
3.5.3 页面大小 Page Size
小页面:
- 更少的内存碎片(internal gragmentation)
程序的段不会完全占满页面,一般段的最后一页会剩余一半的空闲内存。所以页面越小,内部碎片越少
- 减少内存浪费
假设一个进程需要 5KB 内存运行,如果页面大小为 32KB,需要分配一个页,浪费 27KB内存,如果特面大小为 4KB,分配两个页,只浪费 3KB 内存。
大页面:
- 更少的页表项
- 更少的 TLB 项
- 更快的页面传输
内存和磁盘之间的交互一般是一次一页,磁盘 IO 的主要时间花费在寻道和磁头旋转上,所以完成一次大页面 IO 和小页面 IO 的时间基本相同,但是使用大页面可以减少 IO 次数。
- 更快的进程上下文切换
进程上下文切换时,需要存储和加载页表,使用大页时,页表项更少。
3.5.4 分离指令和地址空间 Separate Instruction and Data Spaces
将地址空间划分为指令空间(I-Space) 和数据空间 (D-Space),它们都可以分页,但是相互独立,拥有自己的页表。
划分地址空间不会引入复杂的涉及,还可以让可用的地址空间翻倍。
目前地址空间已经足够大了,分离地址空间主要用于 L1 缓存中。
3.5.5 共享页面 Shared Pages
以下场景存在重复的页面,可以通过共享页面的方式避免内存中存在同一个页面的多个副本。
- 同时运行多个相同的程序
- 不同的程序依赖相同的共享库
- ...
只有只读的页面可以共享,如代码段对应的页。可以被修改的页面不允许被共享,如数据段对应的页。
如果系统支持分离指令和数据地址空间,可以让进程使用相同的指令空间和不同的数据空间。
每个进程都有两个指针,一个指向指令空间,一个指向数据空间。
如果系统不支持分离指令和数据地址空间,就需要更加复杂的机制来共享页面。
当多个进程共享代码段页面时,如果调度决定换出一个程序时,要换出这个的页面并且其他程序的页面填充这些空的页帧,这就会导致另一个程序产生大量的缺页中断并把页面重新加载到内存。
所以需要一种高效的数据结构来记录这些被共享的页面。
特别的,在一些系统中可以共享数据页面。
unix 系统中,在进行 fork 调用后,父子进程共享代码和数据,它们拥有各自的页表,但都指向相同的页面。
所有映射到两个进程的数据页面都是只读的,如果其中一个进程要修改数据页,就会触发只读保护(read-only preotection),引发操作系统 trap,然后生成一个数据页面的副本
这种方法称为写时复制(copy on write)。
3.5.6 共享库 Shared Libraries
动态链接库的优点:
- 相比静态链接,不必包含一些公共库,编译产物更小
- 所有依赖该动态库的进程共享一个动态库,在内存中仅需保存一份副本
- 修改程序源码时,可以只替换修改过的动态库,无需重新编译整个程序
PLT 详细解析:
demo 部分源码:
libmath.so 源码
// math.c
int add(int a, int b)
{return a + b;
}
可执行文件源码
// main.c
int main(void)
{int ret = add(1, 2);printf("1 + 2 = %d\n", ret);ret = add(2, 1);printf("2 + 1 = %d\n", ret);return 0;
}
objdump 反汇编可执行文件,main 函数如下:
0000000000401136 <main>:401136: 55 push %rbp401137: 48 89 e5 mov %rsp,%rbp40113a: 48 83 ec 10 sub $0x10,%rsp40113e: be 02 00 00 00 mov $0x2,%esi401143: bf 01 00 00 00 mov $0x1,%edi401148: e8 e3 fe ff ff call 401030 <add@plt>40114d: 89 45 fc mov %eax,-0x4(%rbp)401150: 8b 45 fc mov -0x4(%rbp),%eax401153: 89 c6 mov %eax,%esi401155: bf 04 20 40 00 mov $0x402004,%edi40115a: b8 00 00 00 00 mov $0x0,%eax40115f: e8 dc fe ff ff call 401040 <printf@plt>401164: be 01 00 00 00 mov $0x1,%esi401169: bf 02 00 00 00 mov $0x2,%edi40116e: e8 bd fe ff ff call 401030 <add@plt>401173: 89 45 fc mov %eax,-0x4(%rbp)401176: 8b 45 fc mov -0x4(%rbp),%eax401179: 89 c6 mov %eax,%esi40117b: bf 10 20 40 00 mov $0x402010,%edi401180: b8 00 00 00 00 mov $0x0,%eax401185: e8 b6 fe ff ff call 401040 <printf@plt>40118a: b8 00 00 00 00 mov $0x0,%eax40118f: c9 leave 401190: c3 ret
.plt 节如下:
Disassembly of section .plt:0000000000401020 <add@plt-0x10>:401020: ff 35 e2 2f 00 00 push 0x2fe2(%rip) # 404008 <_GLOBAL_OFFSET_TABLE_+0x8>401026: ff 25 e4 2f 00 00 jmp *0x2fe4(%rip) # 404010 <_GLOBAL_OFFSET_TABLE_+0x10>40102c: 0f 1f 40 00 nopl 0x0(%rax)0000000000401030 <add@plt>:401030: ff 25 e2 2f 00 00 jmp *0x2fe2(%rip) # 404018 <add@Base>401036: 68 00 00 00 00 push $0x040103b: e9 e0 ff ff ff jmp 401020 <_init+0x20>0000000000401040 <printf@plt>:401040: ff 25 da 2f 00 00 jmp *0x2fda(%rip) # 404020 <printf@GLIBC_2.2.5>401046: 68 01 00 00 00 push $0x140104b: e9 d0 ff ff ff jmp 401020 <_init+0x20>
当执行到 add 函数时,先调用 <add@plt> 函数,首先执行 jmp *0x2fe2(%rip) 指令,此时 rip 的值是顺序下一条指令的地址,即 0x401036,查看这个地址的值如下
Dump of assembler code for function add@plt:
=> 0x0000000000401030 <+0>: jmp *0x2fe2(%rip) # 0x404018 <add@got.plt>0x0000000000401036 <+6>: push $0x00x000000000040103b <+11>: jmp 0x401020
End of assembler dump.
(gdb) x/xg 0x404018
0x404018 <add@got.plt>: 0x0000000000401036
0x2fe2(%rip) 是 add 函数对应的 GOT 表条目的地址,它的值是接下来要跳转的地址。现在看来 jmp *0x2fe2(%rip) 指令还只是跳转到 <add@plt> 的下一条指令。
之后执行到 jmp 401020 <_init+0x20>,即 <add@plt-0x10>,执行指令 push 0x2fe2(%rip)
0000000000401020 <add@plt-0x10>:401020: ff 35 e2 2f 00 00 push 0x2fe2(%rip) # 404008 <_GLOBAL_OFFSET_TABLE_+0x8>401026: ff 25 e4 2f 00 00 jmp *0x2fe4(%rip) # 404010 <_GLOBAL_OFFSET_TABLE_+0x10>40102c: 0f 1f 40 00 nopl 0x0(%rax)
push 指令将 0x2fe2(%rip) 的值压入栈中,这个地址在后面回用到。
(gdb) x/xg 0x404008
0x404008: 0x00007ffff7ffe2e0
jmp *0x2fe4(%rip) 要跳转的地址如下,0x404010 存放的是 _dl_runtime_resolve_xsavec 的地址,该函数用于解析和绑定动态库函数。
(gdb) x/xg 0x404010
0x404010: 0x00007ffff7fd8d30
(gdb) x *(void**)0x404010
0x7ffff7fd8d30 <_dl_runtime_resolve_xsavec>: 0xe3894853fa1e0ff3
反汇编 _dl_runtime_resolve_xsavec,该函数调用 _dl_fixup 解析 add 函数的地址,传入的参数 rdi 就是之前压入栈的的地址 0x00007ffff7ffe2e0,其本质上是一个 struct link_map 结构体。
在 _dl_fixup 中,根据传入的 struct link_map 拿到 GOT 条目的地址,然后将 add 函数的地址写入这个 GOT 条目,下一次再调用 <add@plt> 时就可以直接跳转到 add 的地址,无需上述解析绑定过程。
(gdb) disass _dl_runtime_resolve_xsavec
Dump of assembler code for function _dl_runtime_resolve_xsavec:0x00007ffff7fd8d30 <+0>: endbr640x00007ffff7fd8d34 <+4>: push %rbx0x00007ffff7fd8d35 <+5>: mov %rsp,%rbx0x00007ffff7fd8d38 <+8>: and $0xffffffffffffffc0,%rsp0x00007ffff7fd8d3c <+12>: sub 0x23f4d(%rip),%rsp # 0x7ffff7ffcc90 <_rtld_global_ro+432>0x00007ffff7fd8d43 <+19>: mov %rax,(%rsp)0x00007ffff7fd8d47 <+23>: mov %rcx,0x8(%rsp)0x00007ffff7fd8d4c <+28>: mov %rdx,0x10(%rsp)0x00007ffff7fd8d51 <+33>: mov %rsi,0x18(%rsp)0x00007ffff7fd8d56 <+38>: mov %rdi,0x20(%rsp)0x00007ffff7fd8d5b <+43>: mov %r8,0x28(%rsp)0x00007ffff7fd8d60 <+48>: mov %r9,0x30(%rsp)0x00007ffff7fd8d65 <+53>: mov $0xee,%eax0x00007ffff7fd8d6a <+58>: xor %edx,%edx0x00007ffff7fd8d6c <+60>: mov %rdx,0x250(%rsp)0x00007ffff7fd8d74 <+68>: mov %rdx,0x258(%rsp)0x00007ffff7fd8d7c <+76>: mov %rdx,0x260(%rsp)0x00007ffff7fd8d84 <+84>: mov %rdx,0x268(%rsp)0x00007ffff7fd8d8c <+92>: mov %rdx,0x270(%rsp)0x00007ffff7fd8d94 <+100>: mov %rdx,0x278(%rsp)0x00007ffff7fd8d9c <+108>: xsavec 0x40(%rsp)0x00007ffff7fd8da1 <+113>: mov 0x10(%rbx),%rsi0x00007ffff7fd8da5 <+117>: mov 0x8(%rbx),%rdi0x00007ffff7fd8da9 <+121>: call 0x7ffff7fd5e70 <_dl_fixup>0x00007ffff7fd8dae <+126>: mov %rax,%r110x00007ffff7fd8db1 <+129>: mov $0xee,%eax0x00007ffff7fd8db6 <+134>: xor %edx,%edx0x00007ffff7fd8db8 <+136>: xrstor 0x40(%rsp)0x00007ffff7fd8dbd <+141>: mov 0x30(%rsp),%r90x00007ffff7fd8dc2 <+146>: mov 0x28(%rsp),%r80x00007ffff7fd8dc7 <+151>: mov 0x20(%rsp),%rdi0x00007ffff7fd8dcc <+156>: mov 0x18(%rsp),%rsi0x00007ffff7fd8dd1 <+161>: mov 0x10(%rsp),%rdx0x00007ffff7fd8dd6 <+166>: mov 0x8(%rsp),%rcx0x00007ffff7fd8ddb <+171>: mov (%rsp),%rax0x00007ffff7fd8ddf <+175>: mov %rbx,%rsp0x00007ffff7fd8de2 <+178>: mov (%rsp),%rbx0x00007ffff7fd8de6 <+182>: add $0x18,%rsp0x00007ffff7fd8dea <+186>: jmp *%r11
End of assembler dump.
3.5.7 文件映射 Mapped Files
内存映射文件(memory-mapped file):进程通过一个系统调用,将一个文件映射到虚拟地址空间。
- 在进行映射动作时不会加载文件内容到内存,只有当访问这个页面时,触发缺页中断,由操作系统加载页面到内存
- 当进程退出或者解除映射时,所有被修改的文件页面被写回磁盘
- 可以把映射在内存中的文件页面当作一个大字符数组来访问,不必使用 read/write 来访问文件
- 多个进程同时映射同一个文件时,可以将其当作共享内存来实现进程间通信
3.5.8 清理策略 Cleaning Policy
如果内存中的页帧都被占用并且被修改,当发生缺页中断时,需要先将页面写回磁盘,再加载新页面。因此,在系统中保留足够的空闲页帧可以提高页面替换的效率。
分页系统中一般存在一个分页守护进程(paging daemon),定期被唤醒检查内存中的页帧使用情况,如果空闲页帧过少,就调用页面替换算法换出部分页面。
使用双指针算法。前指针由页面守护进程控制,指针向前移动,如果遇到脏页面,需要先写回页面再移动。后指针用于页面替换,总是指向一个干净的页帧。
3.5.9 虚拟内存接口 Virtual Memory Interface
对一片内存区域进行命名,多个进程可以根据命名找到共享内存,从而实现进程间通信。
分布式共享内存:可以让网络上的多个进程共享一个页面集合。
当访问到未加载的页面时,产生缺页中断,操作系统处理缺页中断时,向拥有该页面的机器发送消息,从而获取要访问的页面。



















