主流消息队列对比
消息队列是一种重要的分布式系统组件,可用于异步通信、削峰填谷、解耦系统、数据缓存等多个方面。在选择消息队列时,需要考虑诸多因素,包括性能、可靠性、可用性、扩展性、可维护性、社区支持等等。
| 维度 | ActiveMQ | RabbitMQ | RocketMQ | Kafka | Pulsar |
|---|---|---|---|---|---|
| 单机吞吐量 | 较低(万级) | 一般(万级) | 高(十万级) | 高(十万级) | 高(十万级) |
| 开发语言 | Java | Erlang | Java | Java/Scala | Java |
| 维护者 | Apache | Spring | Apache(Alibaba) | Apache(Confluent) | Apache(StreamNative) |
| Star 数量 | 2.3K | 12K | 21K | 28.2K | 14.1K |
| Contributor | 139 | 264 | 527 | 1189 | 661 |
| 社区活跃度 | 低 | 高 | 较高 | 高 | 高 |
| 消费模式 | P2P、Pub-Sub | direct、topic、Headers、fanout | 基于 Topic 和 MessageTag 的的 Pub-Sub | 基于 Topic 的 Pub-Sub | 基于 Topic 的 Pub-Sub,支持独占(exclusive)、共享(shared)、灾备(failover)、key 共享(key_shared)4 种模式 |
| 持久化 | 支持(小) | 支持(小) | 支持(大) | 支持(大) | 支持(大) |
| 顺序消息 | 不支持 | 不支持 | 支持 | 支持 | 支持 |
| 性能稳定性 | 好 | 好 | 一般 | 较差 | 一般 |
| 集群支持 | 主备模式 | 复制模式 | 主备模式 | Leader-Slave 每台既是 master 也是 slave,集群可扩展性强 | 集群模式,broker 无状态,易迁移,支持跨数据中心 |
| 管理界面 | 一般 | 较好 | 一般 | 无 | 无 |
| 计算和存储分离 | 不支持 | 不支持 | 不支持 | 不支持 | 支持 |
| AMQP 支持 | 支持 | 支持 | 支持 | 不完全支持 | 不完全支持 |
RabbitMQ
RabbitMQ是一个用Erlang语言开发的、实现了AMQP协议的消息中间件。
AMQP :(Advanced Message Queue,高级消息队列协议)它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
核心组件
生产者发送消息给交换机,交换机根据路由规则,将不同的消息路由到不同的队列,消费者订阅/监听队列,当有消息过来时,就立即消费。
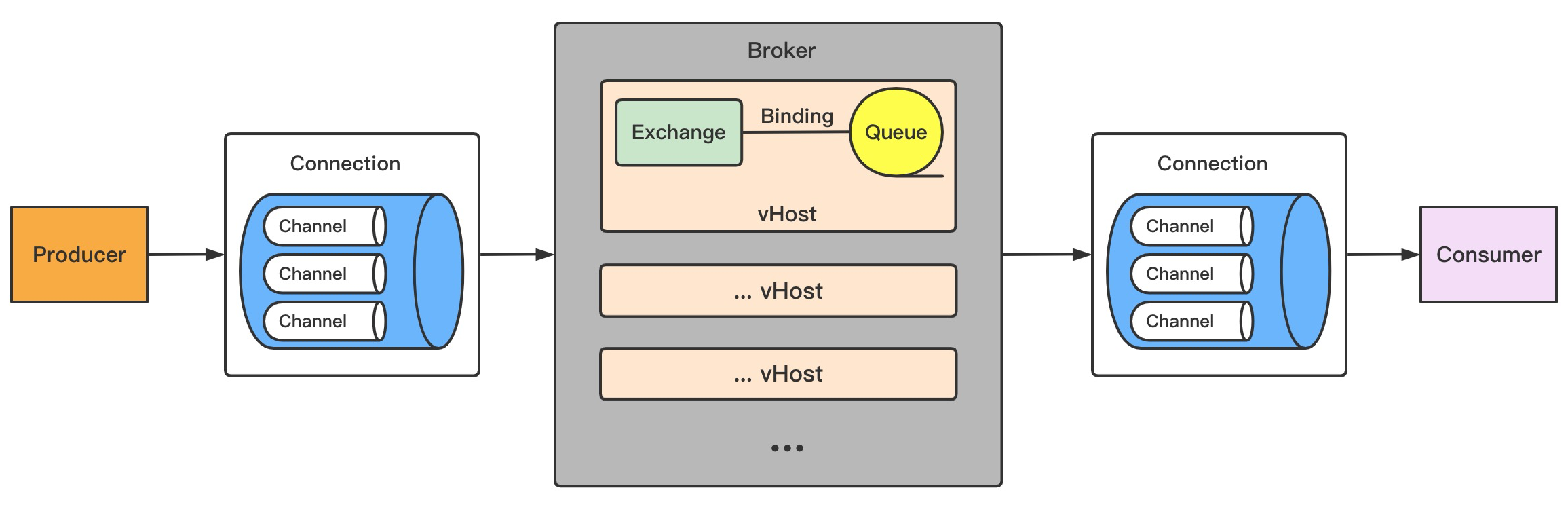
Broker:Broker简单理解就是RabbitMQ服务器,图中灰色的整个部分。后面说Broker说的就是RabbitMQ服务器。
VHost虚拟主机:相当于数据库(vhost)一样,本地连接可以创建多个数据库,数据库里有多个表(交换机、队列等等),起到隔离作用。
每个RabbitMQ服务器可以开设多个虚拟主机vhost(图中橘色的部分),每一个vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的 "交换机exchange、绑定Binding、队列Queue",更重要的是每一个vhost拥有独立的权限机制,这样就能安全地使用一个RabbitMQ服务器来服务多个应用程序,其中每个vhost服务一个应用程序。
每一个RabbitMQ服务器都有一个默认的虚拟主机 "/",客户端连接RabbitMQ服务时须指定vHost,如果不指定默认连接的就是"/"。
Connection连接:无论是生产者还是消费者,都需要和 Broker 建立连接,这个连接就是Connection(看图),是一条 TCP 连接 ,一个生产者或一个消费者与 Broker 之间只有一个Connection,即只有一条TCP连接。
Channel 信道 :消息推送使用的通道,信道是建立在真实的TCP连接内的虚拟连接。AMQP的命令都是通过信道发送出去的,每条信道都会被指派一个唯一ID,不论是发布消息、订阅队列还是接收消息都是通过信道完成的。一个TCP连接下包含多个信道,实现共用TCP、减少TCP创建和销毁的开销。
Exchange 交换机 :用于接受、分配消息;交换机的作用就是根据路由规则,将消息转发到对应的队列上。
Queue 队列:用于存储生产者的消息
Routing key 路由键:用于把生产者的数据分配到路由上,Routing key是消息头的属性,生产者将消息发送到交换机时,会在消息头上携带一个 key,这个 key就是routing key,来指定这个消息的路由规则。
Binding & Binding key 绑定键
Binding,可理解成一个动词,作用就是把exchange交换机和queue队列按照Binding key绑定起来。
Binding key,用于把交换机的消息绑定到队列上,生产者将消息发送给Exchange时,消息头上会携带一个routing key,当binding key与routing key相匹配时,消息将会被路由到对应的Queue中。
队列模式
生产者发送消息给交换机,消息头上会携带一个routing key,通过routing key,交换机就知道该把消息分发到哪个队列,这些规则都通过exchange类型来定义。RabbitMQ 的交换机有四种类型:fanout、direct、topic、headers。
fanout广播模式
就跟广播一样,会将消息投递给所有绑定在此交换器的队列。
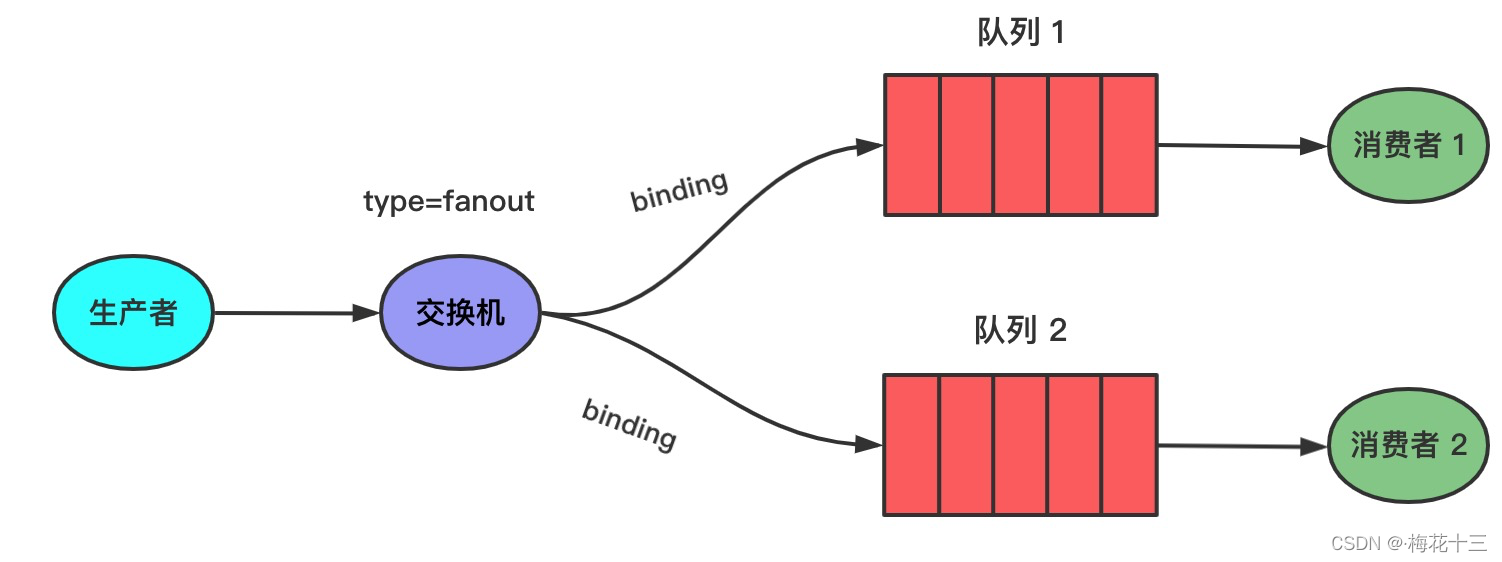
direct路由模式
在 direct 模式里,交换机和队列之间绑定了一个 key(这个key就是Binding key),只有消息的 Routing key 与Binding key 相同时,交换机才会把消息发给该队列。
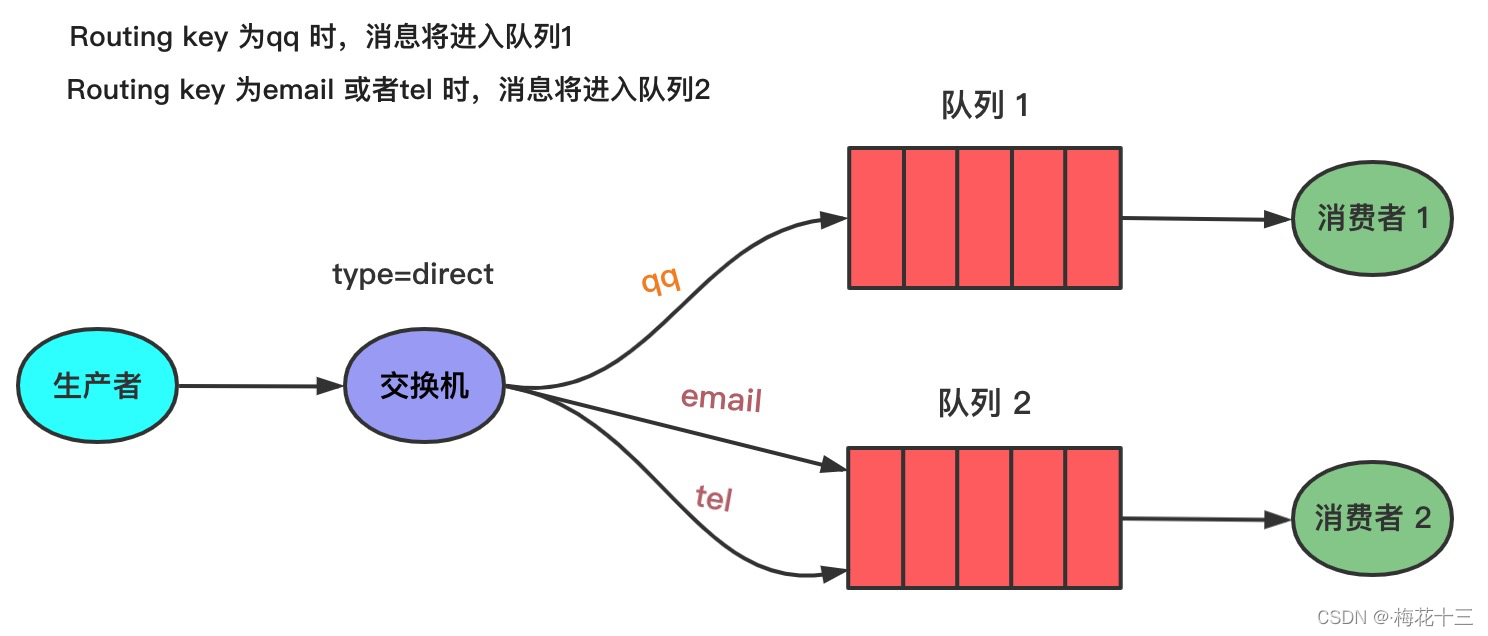
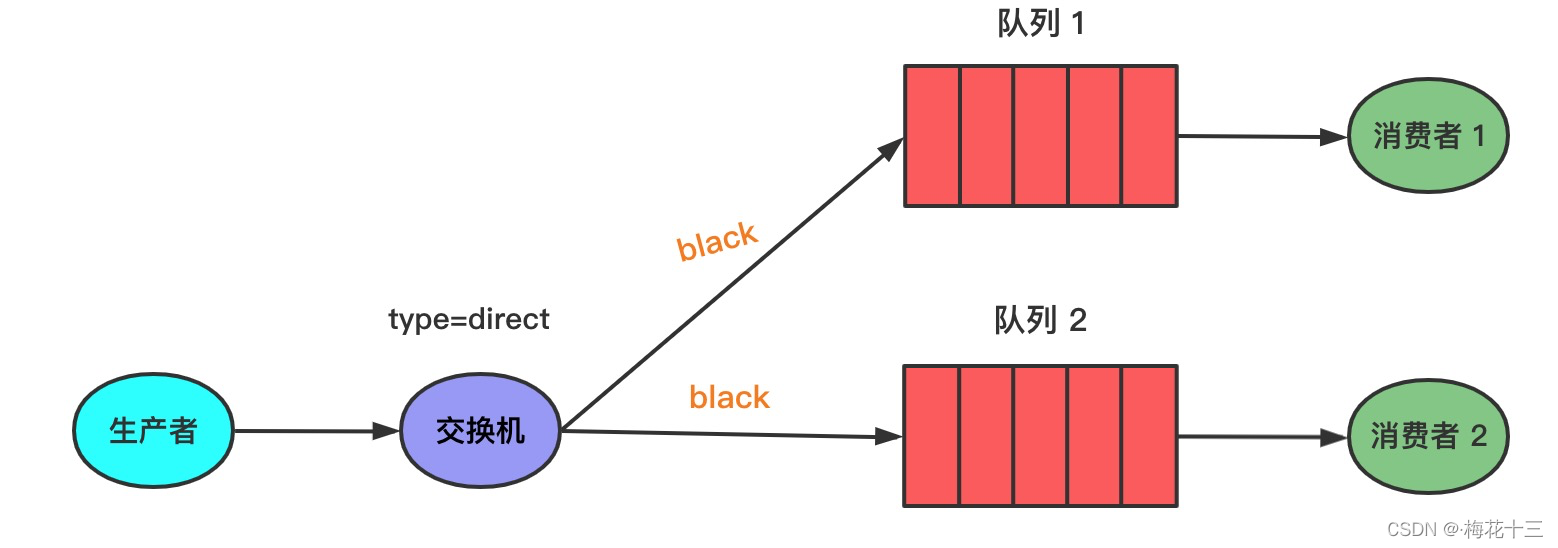
同时,交换机也支持多重绑定。不同的队列可以用相同的Binding key与同一交换机绑定。如下图,当消息的Routing key为black时,消息将进入 Q1 和 Q2。
topic主题模式
通过模糊路由到队列。该方式的Routing key必须具有固定格式:以 . 间隔的一串单词,比如:quick.orange.rabbit,Routing key 最多不能超过255byte。
交换机和队列的Binding key用通配符来表示,有两种语法:
- 可以替代一个单词;
- 可以替代 0 或多个单词;
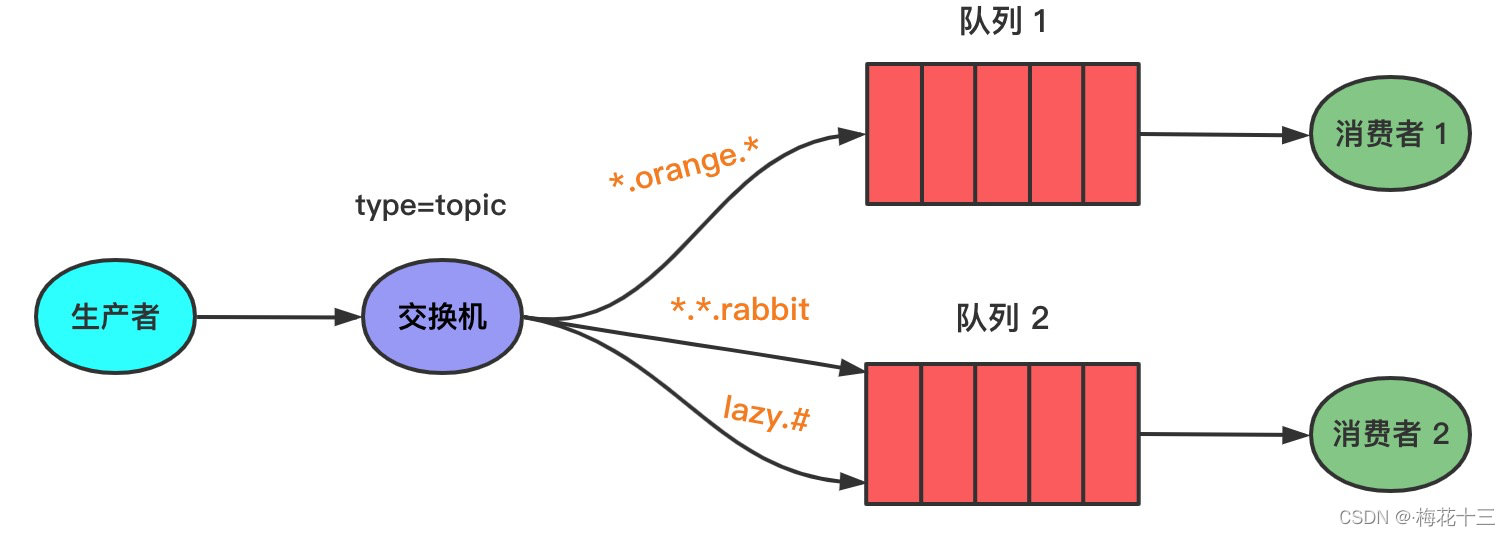
Q1与交换机的 绑定kye 为 " * .orange. *",当消息的Routing key为三个单词,且中间的单词为 orange 时,消息将进入 Q1。
Q2 与交换机的绑定key 为 "lazy.#",当消息的Routing key以 lazy 开头时,消息将进入 Q2 。
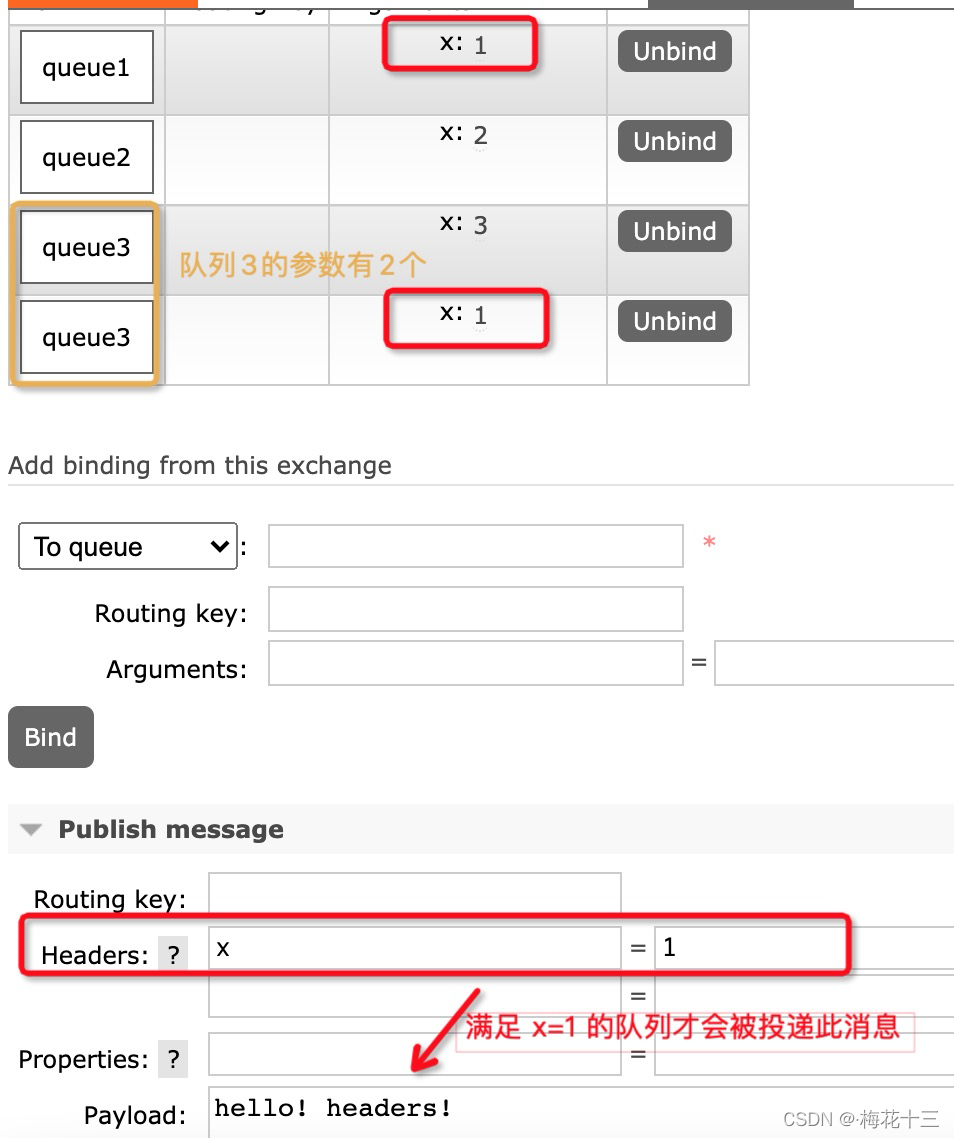
headers参数方式
不常用,headers交换机是通过Headers头部来将消息映射到队列的,Headers头部携带一个Hash结构,Hash结构中要求携带一个键"x-match",这个键的Value可以是any或者all,这代表消息携带的Hash是需要全部匹配(all),还是仅匹配一个键(any)就可以了。相比直连交换机,首部交换机的优势是匹配的规则不被限定为字符串String类型。
扩展
工作队列
在多个消费者之间分配任务(竞争的消费者模式),一个生产者对应多个消费者。适用于资源密集型任务, 单个消费者处理不过来,需要多个消费者进行处理的场景。

高可用
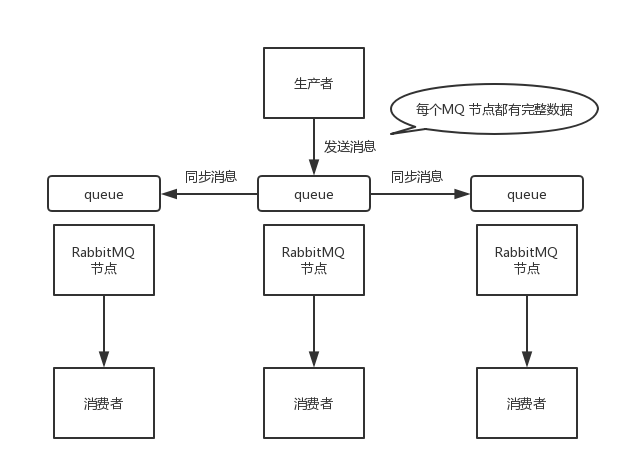
RabbitMQ通过镜像集群模式实现高可用。在镜像集群模式下,每个 RabbitMQ节点都有这个queue的一个完整镜像,包含 queue 的全部数据。每次写消息到queue的时候,都会自动把消息同步到多个实例的queue上。配合负载均衡(HAProxy、Nginx、LVS)和健康检查(keepalived)工具实现高可用访问。
Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能、持久化、多副本备份、横向扩展能力。
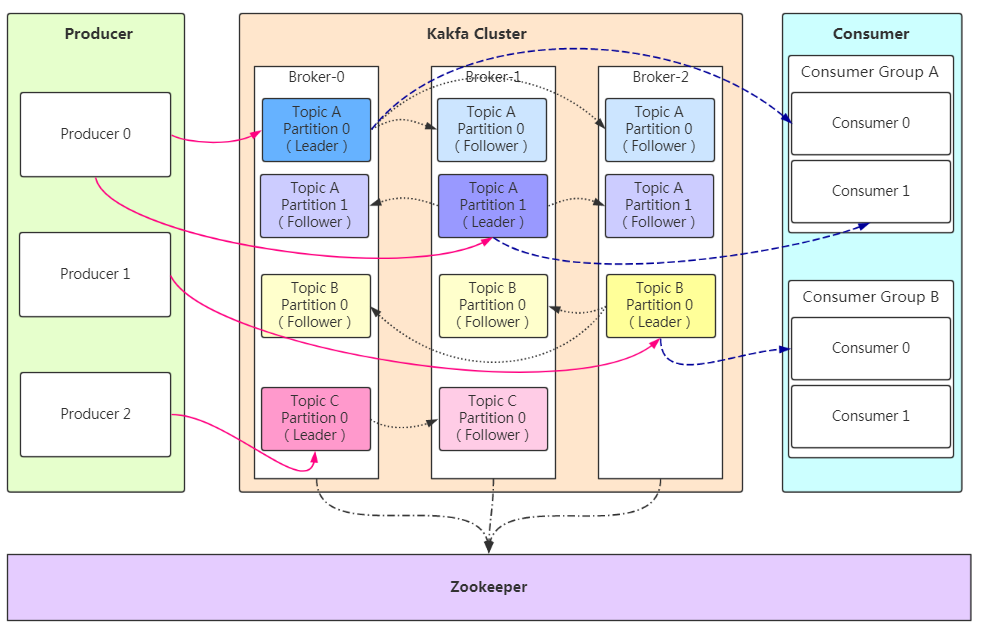
基础架构
-
Producer:Producer即生产者,消息的产生者,是消息的入口。
-
kafka cluster:
- Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message:每一条发送的消息主体。
-
Consumer:消费者,即消息的消费方,是消息的出口。
-
Consumer Group:我们可以将多个消费者组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
-
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
工作流程
发送数据
Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!
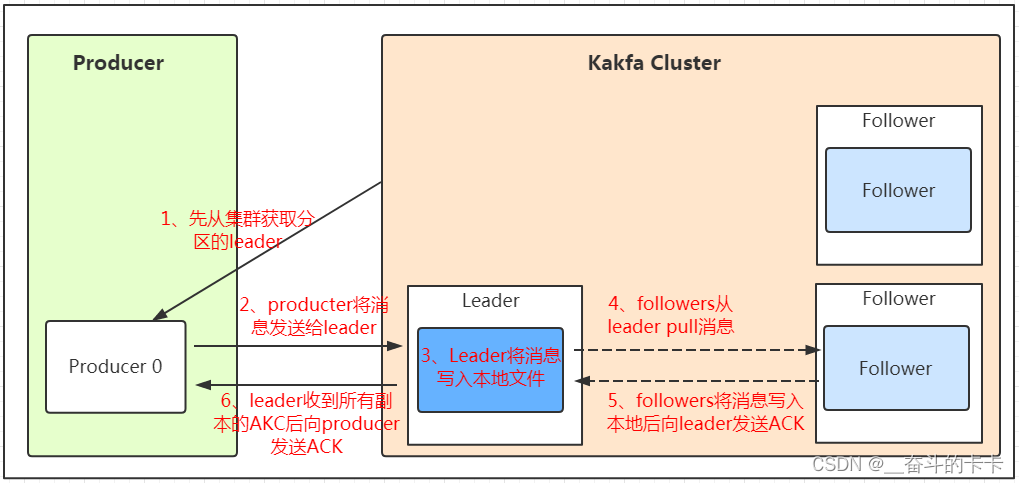
producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!
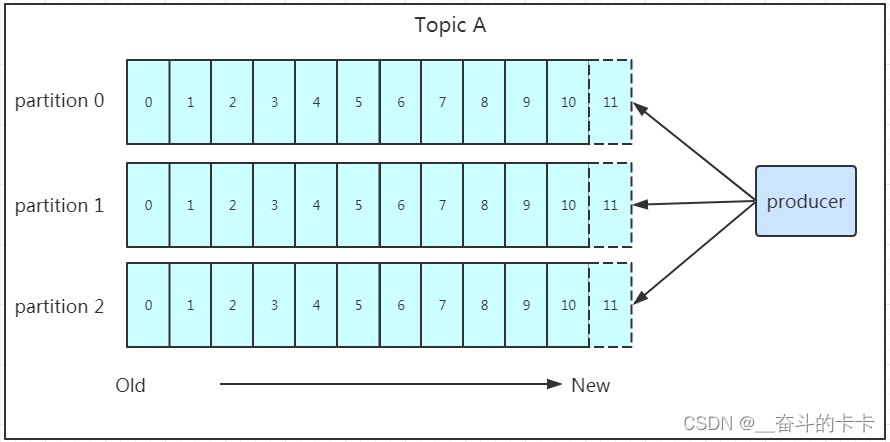
分区的主要目的是:
- 方便扩展。因为一个
topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。 - 提高并发。以
partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
在kafka中,如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?kafka中有几个原则:
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
- 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?其实上面的写入流程图中有描述出来,那就是通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
保存数据
Producer将数据写入kafka后,集群就需要对数据进行保存了!kafka将数据保存在磁盘,可能在我们的一般的认知里,写入磁盘是比较耗时的操作,不适合这种高并发的组件。Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。
Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。

这个partition有三组segment文件,每个log文件的大小是一样的,但是存储的message数量是不一定相等的(每条的message大小不一致)。文件的命名是以该segment最小offset来命名的,如000.index存储offset为0~368795的消息,kafka就是利用分段+索引的方式来解决查找效率的问题。
log文件就实际是存储message的地方,我们在producer往kafka写入的也是一条一条的message,那存储在log中的message是什么样子的呢?消息主要包含消息体、消息大小、offset、压缩类型……等等!我们重点需要知道的是下面三个:
1、 offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置!
2、 消息大小:消息大小占用4byte,用于描述消息的大小。
3、 消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略呢?
1、 基于时间,默认配置是168小时(7天)。
2、 基于大小,默认配置是1073741824。
需要注意的是,kafka读取特定消息的时间复杂度是O(1),所以这里删除过期的文件并不会提高kafka的性能!
消费数据
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id!同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据!!!
在实际的应用中,建议消费者组的consumer的数量与partition的数量一致!
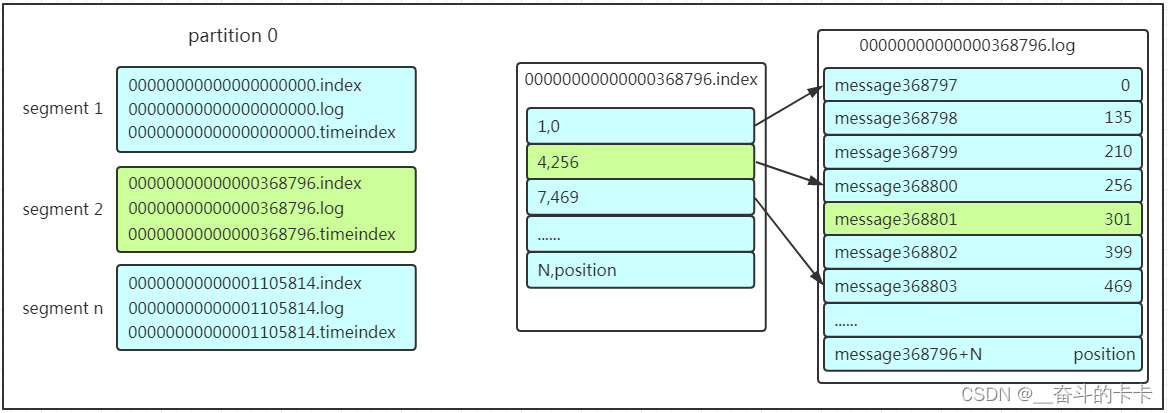
- 先找到offset的368801message所在的segment文件(利用二分法查找),这里找到的就是在第二个segment文件。
- 打开找到的segment中的.index文件(也就是368796.index文件,该文件起始偏移量为368796+1,我们要查找的offset为368801的message在该index内的偏移量为368796+5=368801,所以这里要查找的相对offset为5)。由于该文件采用的是稀疏索引的方式存储着相对offset及对应message物理偏移量的关系,所以直接找相对offset为5的索引找不到,这里同样利用二分法查找相对offset小于或者等于指定的相对offset的索引条目中最大的那个相对offset,所以找到的是相对offset为4的这个索引。
- 根据找到的相对offset为4的索引确定message存储的物理偏移位置为256。打开数据文件,从位置为256的那个地方开始顺序扫描直到找到offset为368801的那条Message。
扩展
消息重复
通常,消息消费时候都会设置一定重试次数来避免网络波动造成的影响,同时带来副作用是可能出现消息重复。生产端: 遇到异常,基本解决措施都是重试;消费端:poll 一批数据,处理完毕还没提交 offset ,机子宕机重启了,又会 poll 上批数据,再度消费就造成了消息重复。
消息重复解决方式:
- Kafka 幂等性 Producer: 保证生产端发送消息幂等。局限性是只能保证单分区且单会话(重启后就算新会话)。——在生产端添加对应配置即可,开启幂等和acks=all,通过携带一个从0开始单调递增的
Sequence确保重复消息被拒绝。 - Kafka 事务: 保证生产端发送消息幂等。解决幂等 Producer 的局限性。生产端数据发送及 Offset 发送均成功的情况下,提交事务,如果数据发送或者 Offset 发送出现异常时,终止事务。消费端配置
isolation.level参数为read_committed: 表明Consumer只会读取事务型Producer成功提交事务写入的消息。 - 消费端幂等: 保证消费端接收消息幂等。消费端拉取到一条消息后,开启事务,将消息Id 新增到本地消息表中,同时更新订单信息。如果消息重复,则新增操作
insert会异常,同时触发事务回滚。
消息丢失
生产者端问题:配置好 消息发送确认机制(ACKs)。
Broker 写入失败:Kafka Broker 需要将消息写入磁盘日志,如果写入失败,比如磁盘空间不足、宕机等情况,消息可能丢失。
Kafka 默认使用异步刷盘(Async Flushing),这意味着消息先写入内存中的 page cache,再由操作系统定期写入磁盘。如果在刷盘前 Broker 挂了,内存中的消息可能会丢失。可以通过配置 flush.messages 和 flush.ms 参数,强制更频繁地刷盘。
但,刷盘太频繁会降低吞吐量。
副本同步问题:Kafka 的分区副本机制虽然提高了容灾能力,但在 Leader 副本和 Follower 副本同步不及时的情况下,也会丢消息。假设某条消息写入了 Leader 副本,但还没同步到 Follower 副本,Leader 就挂了,新选举出来的 Leader 没有这条消息,结果消息就丢失了。解决方案是开启 ISR(In-Sync Replicas) 机制,只允许 ISR(确保只有同步完成的副本参与选举) 中的副本作为候选 Leader。这种情况下,确保 min.insync.replicas 参数配置合理。
消费者端问题:消费者还没处理完消息就提交了位移(Offset)。一旦 Consumer 挂了,已经处理的消息可能重复消费,而未处理的消息却被跳过了。消费者处理消息失败,但没有重试机制。解决方案为设置offset手动提交,而非自动提交,自动提交的机制是根据一定的时间间隔,将收到的消息进行commit。








,源地址转换出去前)










