01 论文概述
论文标题: Agent Learning via Early Experience: Bridging Imitation and Reinforcement Learning Without Explicit Rewards
作者团队: 由Meta AI FAIR实验室(Facebook人工智能研究院)主导,华人研究者张明宇(通讯作者,曾主导Meta Reflection项目)、李然(第一作者,哥伦比亚大学联合培养博士)牵头,共12位研究者参与(含3位华人核心成员)
发布时间: 2025年10月11日(arXiv预印本,已提交NeurIPS 2025评审)
👉一键直达论文
问题背景:AI 智能体的「成长困境」
当前 AI 智能体训练面临两大核心难题:
1. 强化学习 依赖明确奖励信号,但现实环境中(如医疗决策、复杂机器人控制)难以设计可验证的奖励函数,且长任务链导致「信用分配」困难。
2. 模仿学习 依赖昂贵专家数据,但人类示范数据有限且模型无法通过失败经验迭代,泛化能力弱。例如,购物网站智能体若仅按人类示范选择商品,可能无法应对价格波动或库存变化等新情况。如何让 AI 像人类一样通过自身探索积累经验,成为破局关键。
核心解决方案:「早期经验」范式
Meta 提出的 「早期经验」(Early Experience)范式,在模仿学习与强化学习之间架起桥梁,让智能体通过 「行动 - 观察 - 反思」自主学习,无需外部奖励。

核心亮点
1. 无需奖励信号: 智能体通过自身探索产生的动作 - 结果数据生成监督信号,替代人工标注。
2. 双策略协同:
隐式世界建模(IWM):智能体模拟「如果这样做会发生什么」,通过预测动作导致的状态变化,内化环境因果规律。
自我反思(SR):对比自身动作与专家示范,生成反思性思维链(如「选择红衬衫超预算,应考虑蓝衬衫」),作为训练数据优化决策。
3. 数据效率提升: 减少对专家数据的依赖,在 ALFWorld 等复杂环境中任务成功率平均提升 9.6%,泛化能力提升 9.4%。
技术原理深度解析
1. 灵感来源:人类学习的「试错 - 反思」机制
人类通过尝试新动作(如学习骑车)、观察结果(摔倒或成功)、总结经验(调整平衡)逐步掌握技能。早期经验范式模拟这一过程,让智能体在无奖励环境中自主探索。
2. 理论基础:因果推理与元学习
隐式世界建模基于马尔可夫决策过程(MDP),通过动作 - 状态转移序列构建环境动态模型,类似人类大脑的「心理模拟」。
自我反思借鉴元认知思想,智能体通过生成自然语言反思,将经验转化为可复用的知识。
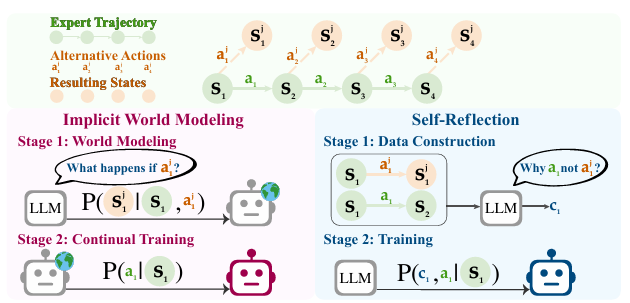
3. 核心方法
- 初始化:用少量专家数据进行模仿学习,建立基础策略。
- 探索阶段:智能体在安全环境中尝试替代动作,记录状态变化(如价格波动对购物决策的影响)。
- 训练阶段:将状态转移数据与反思内容输入模型,优化策略以最大化未来回报。
4. 流程拆解
输入环境状态 → 策略生成动作 → 执行动作并观察结果 →隐式建模预测状态转移 → 自我反思生成改进逻辑 → 联合优化策略与反思质量 → 输出优化后的动作
挑战与未来方向
1. 局限性
- 长序列规划困难:当前方法侧重短跨度经验,对需要长期信用分配的任务(如多步医疗诊断)效果有限。
- 反思质量依赖环境验证:若智能体生成的反思脱离实际(如错误归因),可能误导训练。
2. 未来优化方向
- 结合显式奖励:在复杂场景中引入稀疏奖励,提升长序列任务性能。
- 多智能体协作:通过群体探索加速经验积累,类似人类社会的知识共享。
- 具身智能扩展:从数字环境(如网页浏览)向物理世界(如机器人操作)迁移,验证泛化能力。
02 论文原文阅读
您可以跳转到Lab4AI平台上去阅读论文原文。
👉Lab4AI大模型实验室论文阅读
AI翻译——对照阅读
AI导读——获取核心信息
- Lab4AI.cn提供免费的AI翻译和AI导读工具辅助论文阅读;
- 支持投稿复现,动手复现感兴趣的论文;
- 论文复现完成后,您可基于您的思路和想法,开启论文创新。




![[books]Love, Money, and Parenting: How Economics Explains the Way We Raise Our Kids 5 Febrero 2019](http://pic.xiahunao.cn/[books]Love, Money, and Parenting: How Economics Explains the Way We Raise Our Kids 5 Febrero 2019)
推理初尝试)


)






![[题解]P11294 [NOISG 2022 Qualification] Tree Cutting](http://pic.xiahunao.cn/[题解]P11294 [NOISG 2022 Qualification] Tree Cutting)


)

)