- 什么是 SIMD
- SIMD 基础 API
- System.Runtime.Intrinsics 命名空间
- 如何理解向量的大小
- 跨平台实现方式
- SIMD 指令集的使用
- System.Numerics 命名空间中的 SIMD 支持
- Vector<T> 结构体
- Vector2、Vector3 和 Vector4 结构体
- Matrix2x2、Matrix3x2 和 Matrix4x4 结构体
- 其他 SIMD 的使用场景举例举例
- 字母大小写转换
- 二进制/位操作
- 总结
什么是 SIMD
SIMD(Single Instruction, Multiple Data) 译为 单指令多数据,是一种并行计算技术,允许单条指令同时对多个数据元素进行操作,从而提高计算效率。
与 SIMD 相对的是 SISD(Single Instruction, Single Data,单指令单数据),即每条指令只处理一个数据元素。
现在的大多数 CPU 都支持 SIMD 指令集,例如 Intel 的 SSE 和 AVX,ARM 的 NEON 等。
如果我们要对两组数组进行加法运算,传统方法(SISD)是逐个元素相加,而使用 SIMD 技术,可以一次性将多个元素加载到向量寄存器中,并执行单一的加法指令,从而显著提高计算效率。
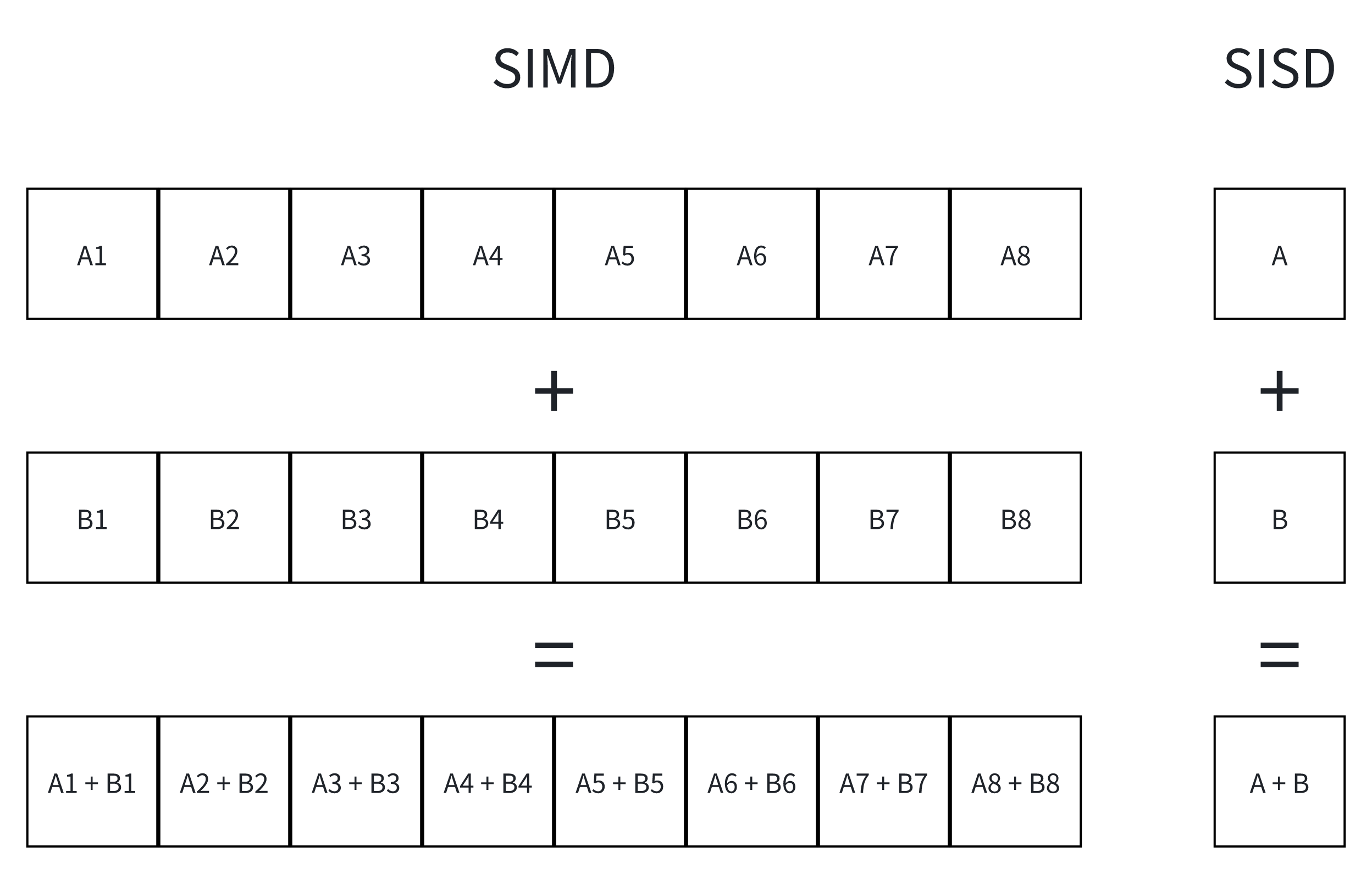
下面我们通过一个简单的示例,对比传统的数组加法和使用 SIMD 优化后的数组加法在性能上的差异。例子中会对两个浮点数组进行加法运算,把结果存储在第三个数组中。
using System.Runtime.Intrinsics;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;[MemoryDiagnoser]
public class SimdBenchmark
{private float[] _arrA;private float[] _arrB;private float[] _resultArray;private readonly int _dataSize = 1_000_000;[GlobalSetup]public void Setup(){var random = new Random();_arrA = new float[_dataSize];_arrB = new float[_dataSize];_resultArray = new float[_dataSize];for (int i = 0; i < _dataSize; i++){_arrA[i] = (float)random.NextDouble() * 10f;_arrB[i] = (float)random.NextDouble() * 10f;}}[Benchmark]public void NormalAdd(){for (int i = 0; i < _dataSize; i++){_resultArray[i] = _arrA[i] + _arrB[i];}}[Benchmark]public void SimdAdd(){// 每次处理 4 个元素int simdLength = Vector128<float>.Count; // 4int i = 0;// 处理可被 SIMD 整除的部分for (; i <= _dataSize - simdLength; i += simdLength){var va = Vector128.Create(_arrA[i], _arrA[i + 1], _arrA[i + 2], _arrA[i + 3]);var vb = Vector128.Create(_arrB[i], _arrB[i + 1], _arrB[i + 2], _arrB[i + 3]);(va + vb).CopyTo(_resultArray, i);}// 处理尾部不足 4 个的元素for (; i < _dataSize; i++){_resultArray[i] = _arrA[i] + _arrB[i];}}
}public class Program
{public static void Main(string[] args){BenchmarkRunner.Run<SimdBenchmark>();}
}
BenchmarkDotNet v0.15.6, macOS Sequoia 15.7.2 (24G325) [Darwin 24.6.0]
Apple M2 Max, 1 CPU, 12 logical and 12 physical cores
.NET SDK 9.0.100[Host] : .NET 9.0.0 (9.0.0, 9.0.24.52809), Arm64 RyuJIT armv8.0-aDefaultJob : .NET 9.0.0 (9.0.0, 9.0.24.52809), Arm64 RyuJIT armv8.0-a| Method | Mean | Error | StdDev | Allocated |
|---------- |---------:|--------:|--------:|----------:|
| NormalAdd | 880.4 us | 9.28 us | 7.75 us | - |
| SimdAdd | 568.5 us | 4.18 us | 3.70 us | - |笔者在 MacBook Pro M2 Max 上测试,使用 SIMD 优化后的数组加法运算相比传统方法提升了约 35% 的性能。
此处所使用的例子可能会受到结果需要拷贝到结果数组的影响,实际应用中如果能直接在向量上进行更多计算,性能提升会更加显著。
此例子也可以在 Windows 和 Linux 上运行,有兴趣的读者可以自行测试不同平台的性能差异。
SIMD 基础 API
System.Runtime.Intrinsics 命名空间
.NET 为我们提供了下面三个命名空间来使用 SIMD 技术:
- System.Runtime.Intrinsics :包含用于创建和传递各种大小和格式的寄存器状态的类型。
- System.Runtime.Intrinsics.X86 :包含特定于 x86/x64 架构的 SIMD 指令集的类型。
- System.Runtime.Intrinsics.Arm :包含特定于 ARM 架构的 SIMD 指令集的类型。
System.Runtime.Intrinsics 命名空间中定义了表示不同大小向量的结构体和提供创建及操作这些向量的静态类。
结构体
| 类型 | 描述 |
|---|---|
| Vector64<T> | 表示指定数值类型的 64 位向量,该向量适用于并行算法的低级别优化。 |
| Vector128<T> | 表示指定数值类型的 128 位向量,该向量适用于并行算法的低级别优化。 |
| Vector256<T> | 表示指定数值类型的 256 位向量,该向量适用于并行算法的低级别优化。 |
| Vector512<T> | 表示指定数值类型的 512 位向量,该向量适用于并行算法的低级别优化。 |
静态类
| 类型 | 描述 |
|---|---|
| Vector64 | 提供静态方法的集合,用于在 64 位向量上创建、操作和以其他方式操作。 |
| Vector128 | 提供静态方法集合,用于在 128 位向量上创建、操作和以其他方式操作。 |
| Vector256 | 提供静态方法集合,用于在 256 位向量上创建、操作和以其他方式操作。 |
| Vector512 | 提供静态方法的集合,用于在 512 位向量上创建、操作和以其他方式操作。 |
System.Runtime.Intrinsics.X86 和 System.Runtime.Intrinsics.Arm 命名空间中定义了特定于各自架构的 SIMD 指令集的类,这些类提供了访问底层硬件 SIMD 指令的能力。
常见的指令集类例如:
| 类型 | 描述 |
|---|---|
| Sse | 提供对 x86/x64 SSE 指令集的访问。 |
| Sse2 | 提供对 x86/x64 SSE2 指令集的访问。 |
| Avx | 提供对 x86/x64 AVX 指令集的访问。 |
| Avx2 | 提供对 x86/x64 AVX2 指令集的访问。 |
| AdvSimd | 提供对 ARM Advanced SIMD(NEON)指令集的访问。 |
更详细的列表可以参考官方文档:
System.Runtime.Intrinsics.X86 命名空间
System.Runtime.Intrinsics.Arm 命名空间
如何理解向量的大小
向量的大小(如 64 位、128 位、256 位、512 位)指的是向量寄存器能够容纳的数据总位数。每个向量寄存器可以存储多个数据元素,这些数据元素的类型和数量取决于向量的大小和数据类型的位数。
例如开头用到的 Vector128<float>,它表示一个 128 位的向量寄存器,可以存储 4 个 32 位的浮点数(因为 128 / 32 = 4)。
如果是用来存储 64 位的双精度浮点数(double),则 Vector128<double> 可以存储 2 个双精度浮点数(因为 128 / 64 = 2)。
using System.Runtime.Intrinsics;// 创建一个 128 位的向量,存储 16 个 8 位的 字节
Vector128<byte> vectorByte = Vector128.Create((byte)1, (byte)2, (byte)3, (byte)4,(byte)5, (byte)6, (byte)7, (byte)8,(byte)9, (byte)10, (byte)11, (byte)12,(byte)13, (byte)14, (byte)15, (byte)16);// 创建一个 128 位的向量,存储 4 个 32 位的 浮点数
Vector128<float> vectorFloat = Vector128.Create(1.0f, 2.0f, 3.0f, 4.0f);// 创建一个 256 位的向量,存储 8 个 32 位的 浮点数
Vector256<float> vector256Float = Vector256.Create(1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f);// 创建一个 128 位的向量,存储 2 个 64 位的 双精度浮点数
Vector128<double> vectorDouble = Vector128.Create(1.0, 2.0);// 创建一个 256 位的向量,存储 4 个 64 位的 双精度浮点数
Vector256<double> vector256Double = Vector256.Create(1.0, 2.0, 3.0, 4.0);
跨平台实现方式
.NET 的 SIMD 提供了跨平台的实现方式。无论是在 x86/x64 还是 ARM 架构上,.NET 都会根据运行时环境自动选择合适的 SIMD 指令集来执行向量化操作。
我们可以使用 VectorXXX.IsHardwareAccelerated 属性来检查当前平台是否支持特定大小的向量操作。例如:
Console.WriteLine(Vector128.IsHardwareAccelerated ? "128 位向量操作受支持" : "128 位向量操作不受支持");
但即使硬件不支持 SIMD,.NET 仍然会回退到非 SIMD 的实现方式,确保代码的兼容性。
VectorXXX 为我们提供了一组静态方法,用于创建和操作向量。例如,Vector128.Add 方法用于对两个 128 位向量执行加法运算。
我们也可以直接使用运算符号来进行向量运算,例如 +、-、*、/ 等。VectorXXX<T> 结构体重载了这些运算符,使得向量运算更加直观和简洁。
下面这个例子使用 Vector128<float> 来进行浮点数的 SIMD 运算:
using System.Runtime.Intrinsics;// 创建两个 128 位的浮点向量
Vector128<float> vectorA = Vector128.Create(1.0f, 2.0f, 3.0f, 4.0f);
Vector128<float> vectorB = Vector128.Create(5.0f, 6.0f, 7.0f, 8.0f);// 执行加法运算
// 等效于 vectorA + vectorB
var result = Vector128.Add(vectorA, vectorB);// 输出结果
Console.WriteLine($"Result: {result}");
Result: <6, 8, 10, 12>
SIMD 指令集的使用
在使用 SIMD 指令集之前,通常需要检查当前平台是否支持特定的指令集。可以通过调用指令集类的 IsSupported 属性来进行检查。例如:
using System.Runtime.Intrinsics.X86;Console.WriteLine(Sse.IsSupported ? "SSE 指令集受支持" : "SSE 指令集不受支持");
一旦确认指令集受支持,就可以使用该指令集类提供的静态方法来执行 SIMD 操作。例如,使用 Sse 类的 Add 方法来对两个 128 位向量执行加法运算:
using System.Runtime.Intrinsics;
using System.Runtime.Intrinsics.X86;if (Sse.IsSupported)
{// 创建两个 128 位的浮点向量Vector128<float> vectorA = Vector128.Create(1.0f, 2.0f, 3.0f, 4.0f);Vector128<float> vectorB = Vector128.Create(5.0f, 6.0f, 7.0f, 8.0f);// 使用 SSE 指令集执行加法运算var result = Sse.Add(vectorA, vectorB);// 输出结果Console.WriteLine($"Result: {result}");
}
else
{Console.WriteLine("SSE 指令集不受支持");
}
Result: <6, 8, 10, 12>
如果是在 ARM 架构上,可以使用 AdvSimd 类来执行类似的操作:
using System.Runtime.Intrinsics;
using System.Runtime.Intrinsics.Arm;if (AdvSimd.IsSupported)
{// 创建两个 128 位的浮点向量Vector128<float> vectorA = Vector128.Create(1.0f, 2.0f, 3.0f, 4.0f);Vector128<float> vectorB = Vector128.Create(5.0f, 6.0f, 7.0f, 8.0f);// 使用 AdvSimd 指令集执行加法运算var result = AdvSimd.Add(vectorA, vectorB);// 输出结果Console.WriteLine($"Result: {result}");
}
else
{Console.WriteLine("AdvSimd 指令集不受支持");
}
Result: <6, 8, 10, 12>
System.Numerics 命名空间中的 SIMD 支持
基于 System.Runtime.Intrinsics,.NET 还提供了别的更高级别的 SIMD 支持。
比如在 System.Numerics 这个命名空间提供了一些易于使用的类型,如 Vector\<T> 和 Matrix4x4,简化了 SIMD 编程。
Vector<T> 结构体
Vector<T> 是一个通用的向量类型,支持多种数值类型(如 int、float、double 等)。它会根据硬件能力自动选择最佳的向量大小(如 128 位或 256 位),从而实现跨平台的 SIMD 优化。
下面是一个使用 Vector<T> 进行数组加法的示例:
var vectorSize = Vector<float>.Count; // 获取向量大小(元素个数)
float[] arrayA = new float[1000];
float[] arrayB = new float[1000];
float[] resultArray = new float[1000];for (int i = 0; i <= arrayA.Length - vectorSize; i += vectorSize)
{var va = new Vector<float>(arrayA, i);var vb = new Vector<float>(arrayB, i);(va + vb).CopyTo(resultArray, i);
}
Vector2、Vector3 和 Vector4 结构体
System.Numerics 命名空间还提供了 Vector2、Vector3 和 Vector4 结构体,分别表示二维、三维和四维向量,常用于图形和物理计算中。
using System.Numerics;// 创建 Vector3 实例
Vector3 vector1 = new Vector3(1.0f, 2.0f, 3.0f);
Vector3 vector2 = new Vector3(4.0f, 5.0f, 6.0f);// 向量加法
Vector3 resultAdd = Vector3.Add(vector1, vector2);
Console.WriteLine($"Addition: {resultAdd}"); // 输出: <5, 7, 9>// 向量点乘
float dotProduct = Vector3.Dot(vector1, vector2);
Console.WriteLine($"Dot Product: {dotProduct}"); // 输出: 32// 向量归一化
Vector3 normalized = Vector3.Normalize(vector1);
Console.WriteLine($"Normalized: {normalized}"); // 输出: <0.2672612, 0.5345225, 0.8017837>
如果我们去看 Vector3 结构体的源码实现,会发现它内部使用了 SIMD 技术来优化向量运算:
public struct Vector3 : IEquatable<Vector3>, IFormattable
{/// <summary>The X component of the vector.</summary>public float X;/// <summary>The Y component of the vector.</summary>public float Y;/// <summary>The Z component of the vector.</summary>public float Z;public Vector3(float x, float y, float z) => this = Vector3.Create(x, y, z);public static Vector3 Create(float x, float y, float z){return Vector128.Create(x, y, z, 0.0f).AsVector3();}// 省略其他成员...
}
Matrix2x2、Matrix3x2 和 Matrix4x4 结构体
System.Numerics 还提供了 Matrix2x2、Matrix3x2 和 Matrix4x4 结构体,用于表示二维和三维空间中的矩阵,常用于变换和投影计算。
using System.Numerics;// 创建一个 4x4 矩阵
Matrix4x4 matrix = Matrix4x4.CreateRotationX((float)(Math.PI / 4));
Vector3 point = new Vector3(1.0f, 0.0f, 0.0f);// 使用矩阵变换点
Vector3 transformedPoint = Vector3.Transform(point, matrix);
Console.WriteLine($"Transformed Point: {transformedPoint}");
Transformed Point: <1, 0, 0>
其他 SIMD 的使用场景举例举例
字母大小写转换
在 ASCII 码表的设计中,大写字母和小写字母之间的差异仅在于第 6 位(从右往左数)。大写字母的第 6 位为 0,而小写字母的第 6 位为 1。因此,我们可以通过对字符的二进制表示进行按位操作来实现大小写转换。
示例:字母 A B C D 的 ASCII 编码对照
| 字符 | ASCII 十进制 | ASCII 十六进制 | 二进制表示 |
|---|---|---|---|
| A | 65 | 0x41 | 01000001 |
| B | 66 | 0x42 | 01000010 |
| C | 67 | 0x43 | 01000011 |
| D | 68 | 0x44 | 01000100 |
| a | 97 | 0x61 | 01100001 |
| b | 98 | 0x62 | 01100010 |
| c | 99 | 0x63 | 01100011 |
| d | 100 | 0x64 | 01100100 |
可以看到,对应的大写和小写之间,二进制的第 6 位(从右数,值为 32,即 0x20)状态不同:
- 大写:第 6 位为 0
- 小写:第 6 位为 1
这样,只需用 按位或(OR) 大写字母加上 0x20,就能得到对应的小写字母;
用 按位与(AND) 去掉 0x20,可以从小写变成大写。
在 System.Text 命名空间中,.NET 提供了 Ascii 类,里面包含了一些用于 ASCII 字符处理的静态方法。我们可以利用 SIMD 技术来实现高效的大小写转换。
public static class Ascii
{public static OperationStatus ToUpper(ReadOnlySpan<byte> source, Span<byte> destination, out int bytesWritten);public static OperationStatus ToLower(ReadOnlySpan<byte> source, Span<byte> destination, out int bytesWritten);public static OperationStatus ToUpperInPlace(Span<byte> value, out int bytesWritten);public static OperationStatus ToLowerInPlace(Span<byte> value, out int bytesWritten);public static OperationStatus ToUpper(ReadOnlySpan<char> source, Span<char> destination, out int charsWritten);public static OperationStatus ToLower(ReadOnlySpan<char> source, Span<char> destination, out int charsWritten);public static OperationStatus ToUpperInPlace(Span<char> value, out int charsWritten);public static OperationStatus ToLowerInPlace(Span<char> value, out int charsWritten);
}public enum OperationStatus
{/// <summary>The entire input buffer has been processed and the operation is complete.</summary>Done,/// <summary>The input is partially processed, up to what could fit into the destination buffer. The caller can enlarge the destination buffer, slice the buffers appropriately, and retry.</summary>DestinationTooSmall,/// <summary>The input is partially processed, up to the last valid chunk of the input that could be consumed. The caller can stitch the remaining unprocessed input with more data, slice the buffers appropriately, and retry.</summary>NeedMoreData,/// <summary>The input contained invalid bytes which could not be processed. If the input is partially processed, the destination contains the partial result. This guarantees that no additional data appended to the input will make the invalid sequence valid.</summary>InvalidData,
}
参数的重载有 byte 和 char 两种,分别用于处理保存为 byte 和 char 类型的 ASCII 字符数据。
如果是从 IO 流中读取数据进行大小写转换,可以使用 Span<byte> 版本;如果是处理 char 数组或字符串,则使用 Span<char> 版本。
ToUpper 和 ToLower 方法会将源数据转换为目标数据,并返回一个 OperationStatus 枚举值,指示操作的状态。
ToUpperInPlace 和 ToLowerInPlace 方法则会直接在原始数据上进行大小写转换。
需要注意的是,这些方法仅处理 ASCII 范围内的字符(0-127),对于非 ASCII 字符不会进行任何转换。
这些方法并不能替代 string.ToUpper 等方法来获取 string 的大写或小写形式。需考虑 string 和 Span<byte>, Span<char> 之间的转换开销,最终性能并不一定优于直接使用 string.ToUpper 等方法。
可以参考微软的开源项目 Garnet 中的使用场景 AsciiUtils.cs
Ascii.ToUpperInPlace(Span<char> value, out int charsWritten) 的核心实现经整理后大致如下:
void ToUpperInPlace(Span<char> value)
{// 将 Span<char> 转换成 Span<ushort>(char 占 2 字节,方便 SIMD 处理)var buffer = MemoryMarshal.Cast<char, ushort>(value);// 获取元素数量(ushort 数量)var elementCount = (uint)buffer.Length;// 每个向量能处理多少个 ushortvar numElementsPerVector = (uint)(Unsafe.SizeOf<Vector128<byte>>() / sizeof(ushort));// 如果支持 SIMD 且数据足够,否则走普通循环if (Vector128.IsHardwareAccelerated && elementCount >= numElementsPerVector){// 有符号最小值 (0x8000) 用于偏移正确比较ushort sourceSignedMinValue = (ushort)(1 << (8 * sizeof(ushort) - 1));// 'a' 的基准向量(所有元素都是 0x8000 + 'a')var subtractionVector = Vector128.Create((ushort)(sourceSignedMinValue + 'a'));// 26 个字母范围偏移向量(所有元素都是 0x8000 + 26)var comparisonVector = Vector128.Create((ushort)(sourceSignedMinValue + 26));// 大小写差值向量(0x20,所有元素都是这个值)var caseConversionVector = Vector128.Create((ushort)0x20);// 向量化循环索引uint i = 0;// 可以整除的元素个数uint n = elementCount - (elementCount % numElementsPerVector);// 向量化批量处理for (; i < n; i += numElementsPerVector){// 加载当前批次的向量数据var srcVector = Vector128.LoadUnsafe(ref Unsafe.Add(ref MemoryMarshal.GetReference(buffer), (int)i));// 计算 src - 'a' 基准,并判断是否小于 26(即在 a..z 范围)var matches = SignedLessThan(srcVector - subtractionVector, comparisonVector);// 对匹配的小写字母执行大小写转换(异或 0x20 得到大写)srcVector ^= matches & caseConversionVector;// 存回修改后的向量数据srcVector.StoreUnsafe(ref Unsafe.Add(ref MemoryMarshal.GetReference(buffer), (int)i));}// 处理剩余不足一个向量大小的元素for (; i < elementCount; i++){// 读取当前字符ushort c = Unsafe.Add(ref MemoryMarshal.GetReference(buffer), (int)i);// 如果是小写字母则转为大写if (c is >= 'a' and <= 'z'){c = (ushort)(c - 0x20);}// 写回结果Unsafe.Add(ref MemoryMarshal.GetReference(buffer), (int)i) = c;}}else{// 非向量化处理,每个元素单独判断for (int i = 0; i < buffer.Length; i++){ushort c = buffer[i];if (c is >= 'a' and <= 'z'){c = (ushort)(c - 0x20);}buffer[i] = c;}}
}// 有符号比较(用于判断 a..z 范围)
Vector128<ushort> SignedLessThan(Vector128<ushort> left, Vector128<ushort> right)
{// 将 ushort 当成 short 做有符号比较,然后再转换回 ushort 掩码return Vector128.LessThan(left.AsInt16(), right.AsInt16()).AsInt16().AsUInt16();
}
调用上述方法可以高效地将 ASCII 字符串转换为大写形式:
string input = "Hello World! This is a Test String.";
Span<char> span = input.ToCharArray();
ToUpperInPlace(span);
string result = new string(span);
Console.WriteLine(result); // 输出: "HELLO WORLD! THIS IS A TEST STRING."
实际的 Ascii 类实现要复杂得多,包含了更多的边界检查和错误处理逻辑,上述代码仅仅是为了说明核心的 SIMD 思路的简化版本。
使用 Ascii.UpperInPlace 的示例:
using System.Text;string input = "Hello World! This is a Test String. 这部分不会被转换。";
Span<char> span = input.ToCharArray();Ascii.ToUpperInPlace(span, out int charsWritten);// charsWritten 表示实际转换的字符数,非 ASCII 字符不会被转换
string result = new string(span[..charsWritten]);
Console.WriteLine(result); // 输出: "HELLO WORLD! THIS IS A TEST STRING."
二进制/位操作
SIMD 技术非常适合处理大量的二进制数据或位操作。例如,BinaryPrimitives.ReverseEndianness 方法利用 SIMD 来高效地反转字节序:
Span<ushort> data = [0x1234, 0xABCD, 0x5678, 0xEF01];
Span<ushort> reversedData = stackalloc ushort[4];
BinaryPrimitives.ReverseEndianness(data, reversedData);foreach (var value in reversedData)
{Console.WriteLine(value.ToString("X4"));
}
3412
CDAB
7856
01EF
总结
SIMD 技术在 .NET 中提供了强大的并行计算能力,能够显著提升处理大量数据时的性能。通过 System.Runtime.Intrinsics 和 System.Numerics,我们可以方便地利用 SIMD 指令集进行高效的向量化运算。
很多基础库已经内置了 SIMD 优化,开发者在日常编程中可以通过这些库间接受益于 SIMD 技术,而无需深入了解底层实现细节。当然,对于性能敏感的应用场景,理解和直接使用 SIMD 指令集仍然是非常有价值的。
)

















 - 指南)
