前言
最近看到一道面试题:假如线上系统流量突然暴涨10倍,你该怎么办?
感觉挺有意思的。
我在之前的工作中,也经常遇到流量突增的情况,特别是在中午和晚上的用餐高峰期,流量会突增几倍。
今天这篇文章就跟大家好好聊一下这个问题,希望对你会有所帮助。
加苏三的工作内推群
1.先快速解决问题
1.1 紧急扩容
如果发现系统真的扛不住了,第一时间应该是扩容。
现在云计算这么方便,扩容就是点几下鼠标的事。
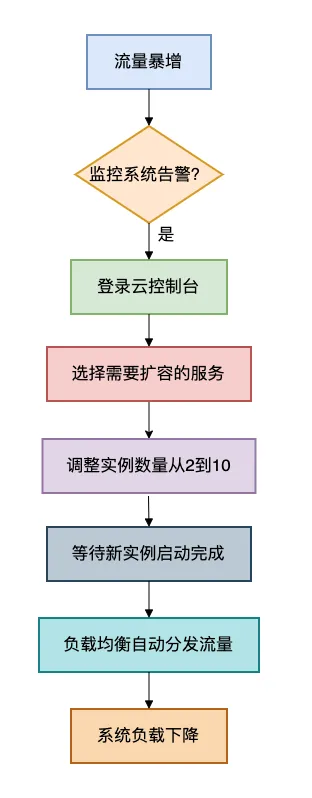
为什么要先扩容?
因为这是最快见效的方法。
你可能需要5分钟分析代码,但扩容只需要1分钟。
先保住系统,再慢慢优化。
1.2 快速定位问题
当监控告警响起时,千万别慌!首先要快速定位瓶颈点。
我有个"5分钟排查法":
# 第1分钟:看整体负载
top -c # 按CPU排序,看哪个进程最耗资源# 第2分钟:看网络连接
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'# 第3分钟:看JVM状态
jstat -gcutil <pid> 1000 # 看内存回收情况# 第4分钟:看接口QPS
tail -f access.log | awk '{print $7}' | sort | uniq -c | sort -nr | head -10# 第5分钟:看错误日志
tail -n 100 error.log | grep -E "(ERROR|Exception)"
2.分层防御
2.1 网关层
它是流量入口的第一道防线。
网关就像小区的门卫,先把不必要的访客挡在外面。
Spring Cloud Gateway限流配置示例:
@Bean
public RedisRateLimiter redisRateLimiter() {// 每秒允许1000个请求,最大允许2000个return new RedisRateLimiter(1000, 2000);
}@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {return builder.routes().route("order_route", r -> r.path("/api/orders/**").filters(f -> f.requestRateLimiter(c -> c.setRateLimiter(redisRateLimiter()))).uri("lb://order-service")).build();
}
这个配置的作用:当订单接口的请求量超过每秒1000次时,多余的请求会被直接拒绝,保护后台服务不被冲垮。
2.2 服务层
我们需要保护核心业务。
服务层就像公司的各个部门,需要保护核心部门正常运转。
熔断降级示例:
@Service
public class OrderService {@Autowiredprivate ProductClient productClient;@CircuitBreaker(name = "productService", fallbackMethod = "getProductFallback")public Product getProduct(Long id) {// 调用商品服务return productClient.getProduct(id);}// 降级方法:当商品服务不可用时执行private Product getProductFallback(Long id, Throwable t) {log.warn("商品服务不可用,返回缓存数据,商品ID: {}", id);// 返回缓存中的默认商品信息return new Product(id, "默认商品", 0.0);}
}
熔断器的工作原理:
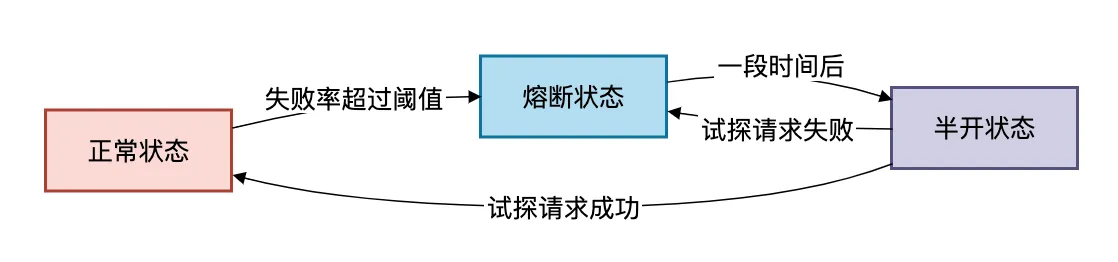
当商品服务的失败率超过50%时,熔断器会打开,后续请求直接走降级逻辑,避免雪崩效应。
2.3 缓存层
通过缓存减少数据库压力。
缓存就像你的笔记本,先把常用的东西记下来,不用每次都去翻大词典。
多级缓存架构:
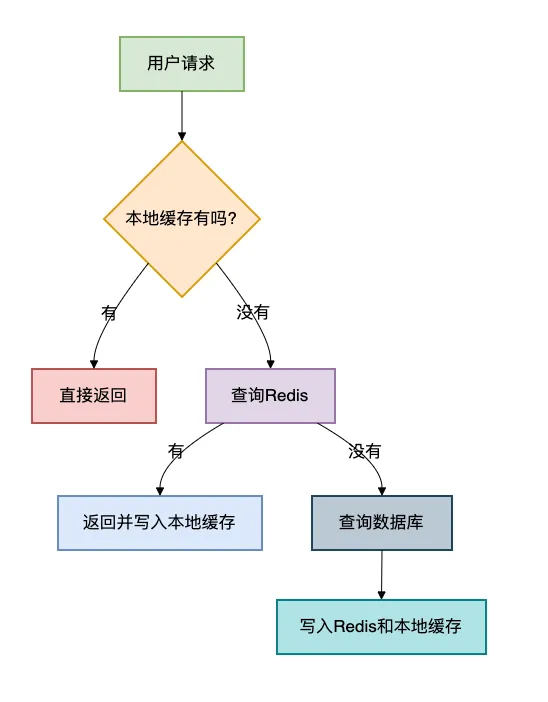
代码实现:
@Service
public class ProductService {// 本地缓存private Cache<Long, Product> localCache = Caffeine.newBuilder().maximumSize(10000).expireAfterWrite(5, TimeUnit.MINUTES).build();public Product getProduct(Long id) {// 1. 先查本地缓存Product product = localCache.getIfPresent(id);if (product != null) {return product;}// 2. 查Redisproduct = redisTemplate.opsForValue().get("product:" + id);if (product != null) {localCache.put(id, product);return product;}// 3. 查数据库product = productRepository.findById(id);if (product != null) {redisTemplate.opsForValue().set("product:" + id, product, 30, TimeUnit.MINUTES);localCache.put(id, product);}return product;}
}
这样设计后,90%的请求在本地缓存就返回了,9%的请求走到Redis,只有1%的请求会到数据库。
2.4 数据库层
它是最后的堡垒。
数据库就像银行的保险库,访问要特别小心。
读写分离:把读操作和写操作分开到不同的数据库
# application.yml 配置
spring:datasource:write:url: jdbc:mysql://write-db:3306/appusername: userpassword: passread:url: jdbc:mysql://read-db:3306/appusername: userpassword: pass
代码中使用:
@Service
public class OrderService {// 写操作用写库@Transactional@WriteDataSourcepublic void createOrder(Order order) {orderRepository.save(order);}// 读操作用读库@ReadDataSourcepublic Order getOrder(Long id) {return orderRepository.findById(id);}
}
如果有需求,可以做分库分表。
// 基于ShardingSphere的分库分表配置
spring:shardingsphere:datasource:names: ds0,ds1ds0: ...ds1: ...rules:sharding:tables:orders:actualDataNodes: ds$->{0..1}.orders_$->{0..15}databaseStrategy:standard:shardingColumn: user_idshardingAlgorithmName: database_inlinetableStrategy:standard:shardingColumn: order_idshardingAlgorithmName: table_inline
可以用批量处理提升吞吐量。
批量写入数据库示例:
@Slf4j
@Service
public class BatchInsertService {private List<Order> batchList = new ArrayList<>();private final int BATCH_SIZE = 1000;@Scheduled(fixedDelay = 1000) // 每秒批量写入一次public void batchInsert() {if (batchList.isEmpty()) {return;}List<Order> currentBatch;synchronized (batchList) {currentBatch = new ArrayList<>(batchList);batchList.clear();}try {jdbcTemplate.batchUpdate("INSERT INTO orders (...) VALUES (?, ?, ...)",currentBatch,100,(ps, order) -> {ps.setLong(1, order.getId());ps.setString(2, order.getNo());// ...其他字段});} catch (Exception e) {log.error("批量插入失败", e);}}
}
3. 异步化
让请求排队处理。
同步处理就像只有一个收银台的超市,异步处理就像让顾客把需求写在纸上,我们慢慢处理。
消息队列削峰示例:
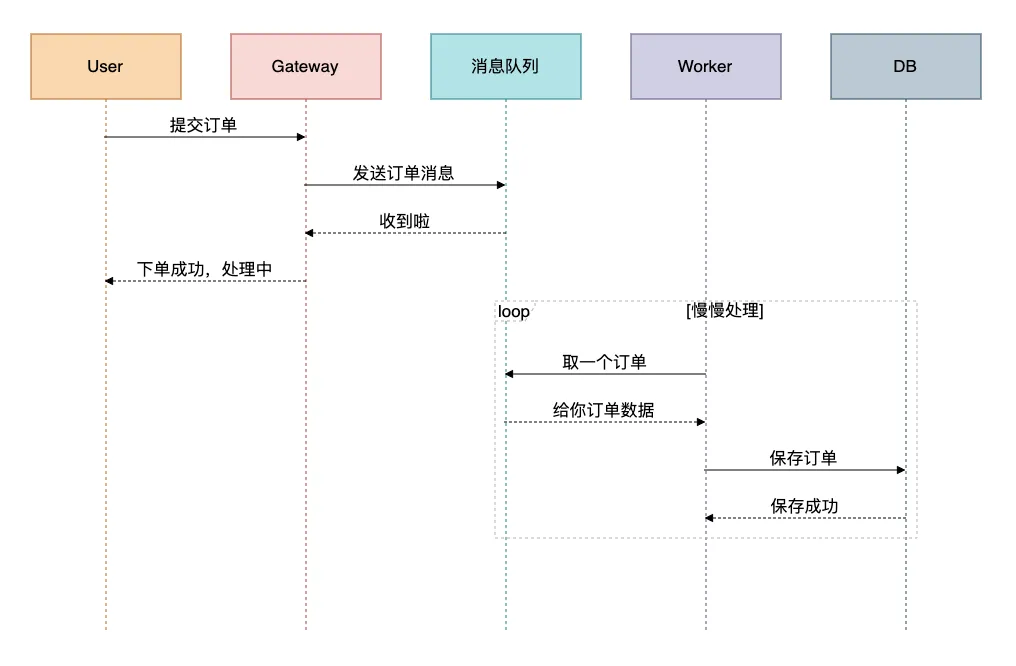
代码实现:
@Component
@RocketMQMessageListener(topic = "order_topic", consumerGroup = "order_group")
public class OrderConsumer implements RocketMQListener<OrderMessage> {@Overridepublic void onMessage(OrderMessage message) {// 这里可以慢慢处理,不用着急orderService.processOrder(message);}
}
这样即使瞬间来了10万个订单,也不会把数据库冲垮,而是慢慢处理。
4.容量评估与弹性伸缩
4.1 性能压测与容量规划
使用JMH进行压力测试代码如下:
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
@State(Scope.Thread)
public class OrderServiceBenchmark {private OrderService orderService;@Setuppublic void setup() {// 初始化测试环境}@Benchmarkpublic void testCreateOrder() {Order order = new Order();// 设置订单参数orderService.createOrder(order);}public static void main(String[] args) throws Exception {Options opt = new OptionsBuilder().include(OrderServiceBenchmark.class.getSimpleName()).forks(1).warmupIterations(5).measurementIterations(10).build();new Runner(opt).run();}
}
4.2 基于指标的弹性伸缩
我们需要建立一套基于指标的弹性伸缩的机制:

当监控系统发现异常时,在K8S中能够自动扩容Prod实例,同时自动更新负载均衡。
5.实战演练
我们需要有全链路压测方案,每隔一段时间做一次实战演练。
5.1 影子库表方案
为压测流量提供隔离的数据库环境,防止压测数据污染正式数据。
基于MyBatis插件的影子库表路由:
@Intercepts({@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class})})
public class ShadowDatabaseInterceptor implements Interceptor {@Overridepublic Object intercept(Invocation invocation) throws Throwable {MappedStatement ms = (MappedStatement) invocation.getArgs()[0];Object parameter = invocation.getArgs()[1];if (isPressureTestRequest()) {// 切换到影子库表String shadowTableName = "shadow_" + getOriginalTableName(ms);MappedStatement shadowMs = createShadowMappedStatement(ms, shadowTableName);invocation.getArgs()[0] = shadowMs;}return invocation.proceed();}private boolean isPressureTestRequest() {// 通过ThreadLocal或请求头判断是否为压测流量return PressureTestContext.isPressureTest();}
}
5.2 压测流量染色
流量染色,顾名思义,就是给压测流量“染上颜色”,打上独特的标记,以便在整个复杂的分布式系统中能够清晰地识别和追踪它。
下面的例子中通过header中的X-Pressure-Test参数,判断是否需要加上染色。
// 全局压测上下文
public class PressureTestContext {private static final ThreadLocal<Boolean> PRESSURE_TEST_FLAG = new ThreadLocal<>();public static void markPressureTest() {PRESSURE_TEST_FLAG.set(true);}public static boolean isPressureTest() {return Boolean.TRUE.equals(PRESSURE_TEST_FLAG.get());}public static void clear() {PRESSURE_TEST_FLAG.remove();}
}// 网关过滤器进行流量染色
@Component
public class PressureTestFilter implements GlobalFilter {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {String pressureTestHeader = exchange.getRequest().getHeaders().getFirst("X-Pressure-Test");if ("true".equals(pressureTestHeader)) {PressureTestContext.markPressureTest();}return chain.filter(exchange).then(Mono.fromRunnable(PressureTestContext::clear));}
}
总结
流量暴增时的应对策略如下:
- 预防优于救治:建立完善的监控预警体系,提前发现容量瓶颈。
- 立即行动:先扩容保住系统,再分析问题。
- 分层防御:从网关到数据库,每层都要有相应的防护措施。
- 弹性设计:系统要具备水平扩展能力,能够快速应对流量变化。
- 异步解耦:通过消息队列等手段,将同步调用转为异步处理。
- 容错降级:保证核心业务的可用性,非核心功能可适当降级。
- 定期演练:通过全链路压测验证系统容量和应急预案。
记住这个处理顺序:先保命(扩容),再治病(优化),最后养生(架构升级)。
最后送大家一句箴言:真正优秀的系统不是永远不会出问题,而是出了问题能快速恢复。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
更多项目实战在我的技术网站:http://www.susan.net.cn/project



)







)







