langgraph-reflexion
https://github.com/fanqingsong/langgraph-reflexion/tree/main
Implementation of a sophisticated Reflexion agent using LangGraph and LangChain, designed to generate high-quality responses through self-reflection and iterative improvement.
This project demonstrates advanced AI agent capabilities using LangGraph's state-of-the-art control flow mechanisms for self-reflection and response refinement.

- Self-Reflection: Implements sophisticated reflection mechanisms for response improvement
- Iterative Refinement: Uses a graph-based approach to iteratively enhance responses
- Production-Ready: Built with scalability and real-world applications in mind
- Integrated Search: Leverages Tavily search for enhanced response accuracy
- Structured Output: Uses Pydantic models for reliable data handling
- Docker Support: Complete Docker setup for easy deployment
- LangGraph Dev Server: Supports LangGraph Studio for visualization and debugging
The agent uses a graph-based architecture with the following components:
- Entry Point:
draftnode for initial response generation - Processing Nodes:
execute_toolsandrevisefor refinement - Maximum Iterations: 2 (configurable)
- Chain Components: First responder and revisor using GPT-4
- Tool Integration: Tavily Search for web research
https://blog.langchain.com/reflection-agents/
Reflexion by Shinn, et. al., is an architecture designed to learn through verbal feedback and self-reflection. Within reflexion, the actor agent explicitly critiques each response and grounds its criticism in external data. It is forced to generate citations and explicitly enumerate superfluous and missing aspects of the generated response. This makes the content of the reflections more constructive and better steers the generator in responding to the feedback.
In the linked example, we stop after a fixed number of steps, though you can also offload this decision to the reflection LLM call.
An overview of the agent loop is shown below:
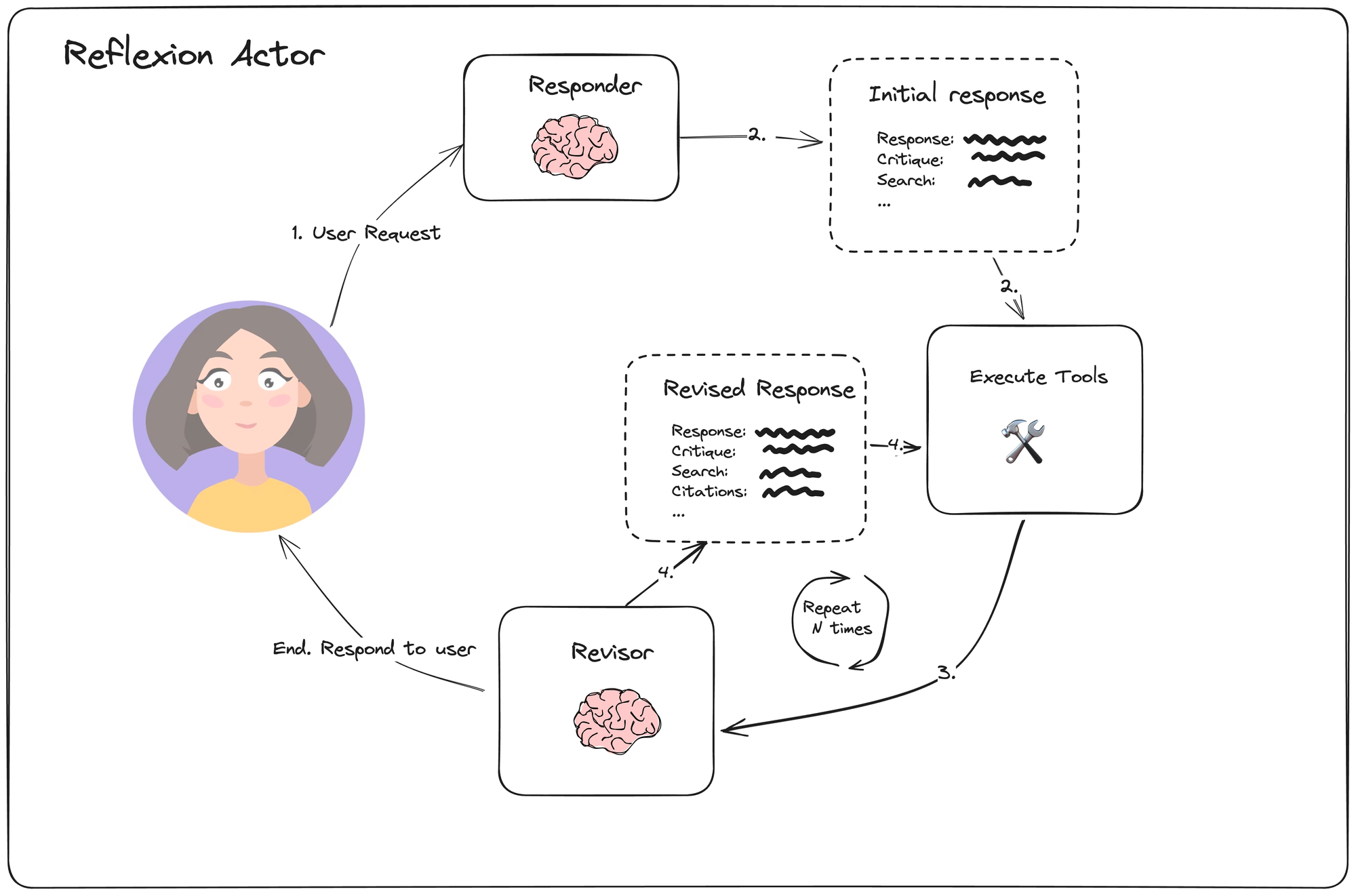 Reflexion Actor Overview
Reflexion Actor Overview
For each step, the responder is tasked with generating a response, along with additional actions in the form of search queries. Then the revisor is prompted to reflect on the current state. The logic can be defined in LangGraph as follows:
from langgraph.graph import END, MessageGraphMAX_ITERATIONS = 5
builder = MessageGraph()
builder.add_node("draft", first_responder.respond)
builder.add_node("execute_tools", execute_tools)
builder.add_node("revise", revisor.respond)
# draft -> execute_tools
builder.add_edge("draft", "execute_tools")
# execute_tools -> revise
builder.add_edge("execute_tools", "revise")# Define looping logic:
def event_loop(state: List[BaseMessage]) -> str:# in our case, we'll just stop after N plansnum_iterations = _get_num_iterations(state)if num_iterations > MAX_ITERATIONS:return ENDreturn "execute_tools"# revise -> execute_tools OR end
builder.add_conditional_edges("revise", event_loop)
builder.set_entry_point("draft")
graph = builder.compile()This agent can effectively use explicit reflections and web-based citations to improve the quality of the final response. It only pursues one fixed trajectory, however, so if it makes a misstep, that error can impact subsequent decisions.
https://python.langchain.com.cn/docs/modules/agents/tools/how_to/custom_tools
https://juejin.cn/post/7514593209680986163
import requests from langchain.tools import StructuredTooldef post_message(url: str, body: dict, parameters: Optional[dict] = None) -> str:"""Sends a POST request to the given url with the given body and parameters."""result = requests.post(url, json=body, params=parameters)return f"Status: {result.status_code} - {result.text}"tool = StructuredTool.from_function(post_message)

)

















